Learning to Extract Cross-Domain Aspects and Understanding Sentiments Using Large Language Models
作者: Karukriti Kaushik Ghosh, Chiranjib Sur
分类: cs.CL
发布日期: 2025-01-15
💡 一句话要点
利用大型语言模型进行跨领域方面抽取和情感理解,提升ABSA性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感分析 方面抽取 大型语言模型 跨领域学习 自然语言处理
📋 核心要点
- 传统情感分析无法细粒度地理解用户对产品或服务的具体方面的情感倾向,限制了企业改进的针对性。
- 该论文探索利用大型语言模型(LLM)直接进行跨领域的方面抽取和情感分类,旨在提升ABSA的性能和泛化能力。
- 实验结果表明,该方法在SemEval-2015 Task 12数据集上取得了92%的准确率,验证了LLM在ABSA任务中的有效性。
📝 摘要(中文)
基于方面的情感分析(ABSA)是一种精细的情感分析方法,旨在提取和分类基于产品、服务或实体的特定方面或特征的情感。与传统的将总体情感分数分配给整个评论或文本的情感分析不同,ABSA侧重于将文本分解为各个组成部分或方面(例如,质量、价格、服务),并评估对每个方面的情感。这可以更细致地了解客户的意见,使企业能够查明具体的优势和改进领域。该过程包括几个关键步骤,包括方面提取、情感分类和方面级别的情感聚合,用于评论段落或用户提供的任何其他形式。ABSA在产品评论、社交媒体监控、客户反馈分析和市场研究等领域具有重要的应用。通过利用自然语言处理(NLP)和机器学习技术,ABSA有助于提取有价值的见解,使公司能够做出数据驱动的决策,从而提高客户满意度并优化产品。随着ABSA的发展,它有潜力通过更深入地了解各种产品方面的情感来极大地改善个性化的客户体验。在这项工作中,我们分析了LLM在完整跨领域方面情感分析中的优势,旨在定义某些产品的框架,并将其用于其他类似情况。我们认为,对于SemEval-2015 Task 12的基于方面的情感分析数据集,可以达到92%的准确率。
🔬 方法详解
问题定义:论文旨在解决跨领域方面情感分析(ABSA)问题。现有方法通常依赖于特定领域的数据进行训练,泛化能力较弱,难以直接应用于新的领域。此外,传统方法在方面抽取和情感分类两个子任务上通常是分离的,缺乏统一的建模。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,直接进行跨领域的方面抽取和情感分类。LLM通过预训练学习了丰富的语言知识,可以更好地理解文本的语义信息,从而提高ABSA的性能和泛化能力。通过prompt工程,将ABSA任务转化为LLM擅长的文本生成任务。
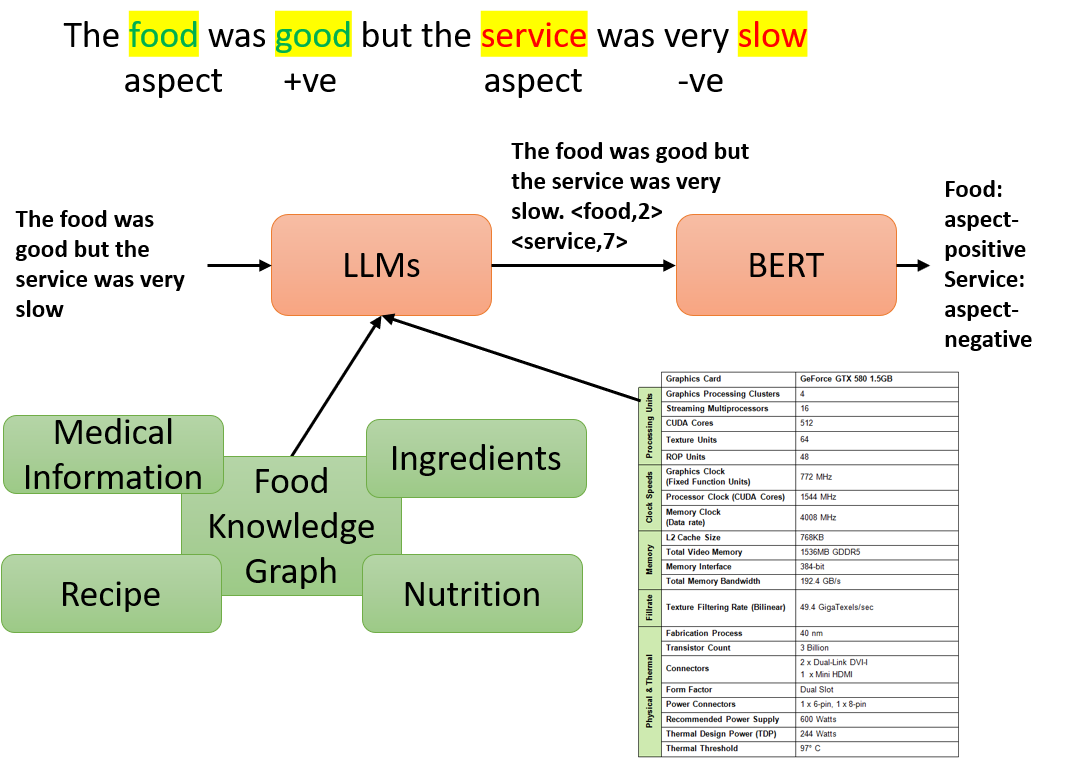
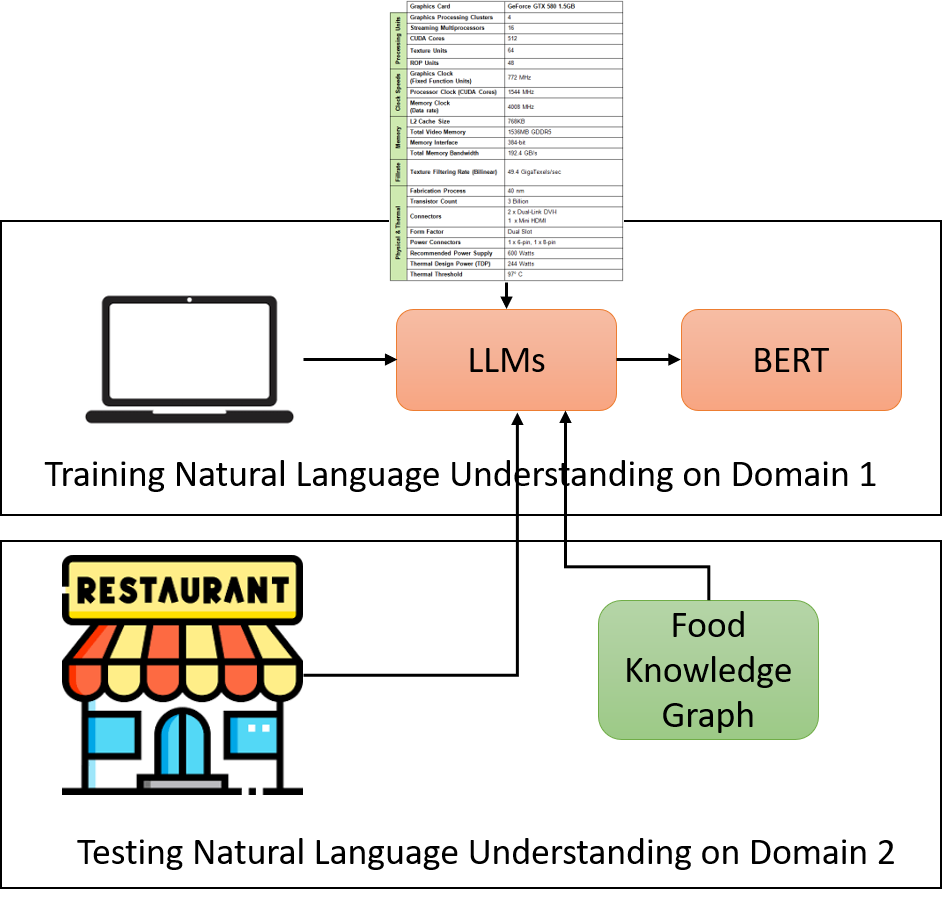
技术框架:该方法没有明确的架构图,本质上是利用LLM进行zero-shot或者few-shot学习。主要流程是:1)构建合适的prompt,将输入文本和目标任务(方面抽取和情感分类)描述清楚;2)将prompt输入到LLM中,LLM生成相应的输出;3)对LLM的输出进行解析,得到方面和情感极性。
关键创新:该方法最重要的创新点在于直接利用LLM进行跨领域的ABSA,避免了传统方法中领域适配和模型迁移的复杂过程。通过prompt工程,将ABSA任务转化为LLM擅长的文本生成任务,充分利用了LLM的语言理解和生成能力。与现有方法的本质区别在于,该方法不需要针对特定领域进行训练,具有更好的泛化能力。
关键设计:论文中没有详细描述prompt的具体设计,这部分是关键的技术细节。另外,如何有效地解析LLM的输出,也是一个需要考虑的问题。论文中没有提及损失函数和网络结构等技术细节,因为该方法直接使用了预训练的LLM。
🖼️ 关键图片
📊 实验亮点
该研究表明,大型语言模型在跨领域方面情感分析任务中具有强大的潜力。在SemEval-2015 Task 12数据集上,该方法取得了92%的准确率,验证了LLM在ABSA任务中的有效性。虽然没有明确的基线对比,但92%的准确率表明LLM在该任务上具有很强的竞争力。
🎯 应用场景
该研究成果可应用于产品评论分析、社交媒体舆情监控、客户反馈处理等领域。企业可以利用该技术自动提取用户评论中的关键方面,并分析用户对这些方面的情感倾向,从而更好地了解用户需求,改进产品和服务,提升用户满意度。该技术还可以用于市场调研,帮助企业了解竞争对手的产品和服务情况。
📄 摘要(原文)
Aspect-based sentiment analysis (ASBA) is a refined approach to sentiment analysis that aims to extract and classify sentiments based on specific aspects or features of a product, service, or entity. Unlike traditional sentiment analysis, which assigns a general sentiment score to entire reviews or texts, ABSA focuses on breaking down the text into individual components or aspects (e.g., quality, price, service) and evaluating the sentiment towards each. This allows for a more granular level of understanding of customer opinions, enabling businesses to pinpoint specific areas of strength and improvement. The process involves several key steps, including aspect extraction, sentiment classification, and aspect-level sentiment aggregation for a review paragraph or any other form that the users have provided. ABSA has significant applications in areas such as product reviews, social media monitoring, customer feedback analysis, and market research. By leveraging techniques from natural language processing (NLP) and machine learning, ABSA facilitates the extraction of valuable insights, enabling companies to make data-driven decisions that enhance customer satisfaction and optimize offerings. As ABSA evolves, it holds the potential to greatly improve personalized customer experiences by providing a deeper understanding of sentiment across various product aspects. In this work, we have analyzed the strength of LLMs for a complete cross-domain aspect-based sentiment analysis with the aim of defining the framework for certain products and using it for other similar situations. We argue that it is possible to that at an effectiveness of 92\% accuracy for the Aspect Based Sentiment Analysis dataset of SemEval-2015 Task 12.