Knowledge Graph-based Retrieval-Augmented Generation for Schema Matching
作者: Chuangtao Ma, Sriom Chakrabarti, Arijit Khan, Bálint Molnár
分类: cs.DB, cs.CL, cs.IR
发布日期: 2025-01-15
备注: Under Review
💡 一句话要点
提出基于知识图谱检索增强的模式匹配方法KG-RAG4SM,提升复杂场景下的匹配精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模式匹配 知识图谱 检索增强生成 大型语言模型 数据集成
📋 核心要点
- 现有模式匹配方法在处理复杂场景时,受限于常识知识和领域知识的缺失,难以消除语义歧义。
- KG-RAG4SM通过知识图谱检索增强LLM,从外部知识库获取相关信息,提升匹配的准确性。
- 实验表明,KG-RAG4SM在多个数据集上显著优于现有SOTA方法,并有效缓解了LLM的幻觉问题。
📝 摘要(中文)
传统的基于相似度的模式匹配方法由于缺乏常识和领域知识,无法解决领域特定复杂映射场景中的语义歧义和冲突。大型语言模型(LLMs)的幻觉问题也使得基于LLM的模式匹配难以解决上述问题。因此,我们提出了一种基于知识图谱的检索增强生成模型用于模式匹配,称为KG-RAG4SM。KG-RAG4SM特别引入了基于向量、基于图遍历和基于查询的图检索,以及一种混合方法和排序方案,用于从外部大型知识图谱(KGs)中识别最相关的子图。我们展示了基于KG的检索增强LLM能够在没有任何重新训练的情况下,为复杂的匹配案例生成更准确的结果。实验结果表明,在MIMIC数据集上,KG-RAG4SM在精确率和F1分数方面分别优于基于LLM的最先进方法(例如,Jellyfish-8B)35.89%和30.50%;在Synthea数据集上,使用GPT-4o-mini的KG-RAG4SM在精确率和F1分数方面分别优于基于预训练语言模型(PLM)的最先进方法(例如,SMAT)69.20%和21.97%。结果还表明,我们的方法在端到端模式匹配中更有效,并且可以扩展到从大型KG中检索。我们在来自真实模式匹配场景的数据集上的案例研究表明,我们的解决方案很好地缓解了LLM在模式匹配中的幻觉问题。
🔬 方法详解
问题定义:论文旨在解决复杂模式匹配场景中,由于缺乏常识和领域知识导致的语义歧义和冲突问题。现有方法,如基于相似度的匹配和基于LLM的匹配,分别存在知识不足和幻觉问题,难以保证匹配的准确性。
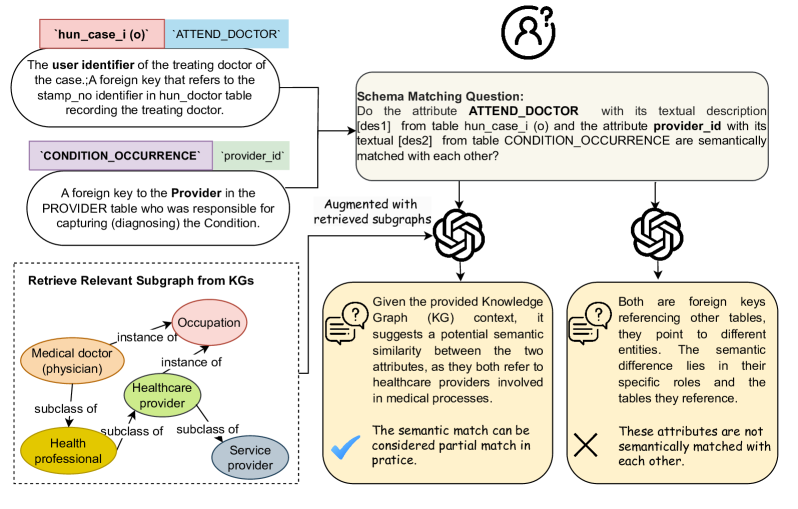
核心思路:论文的核心思路是利用知识图谱(KG)作为外部知识源,通过检索增强生成(RAG)的方式,为LLM提供必要的背景知识,从而提高模式匹配的准确性和可靠性。通过从KG中检索与模式相关的子图,LLM可以更好地理解模式的语义,减少幻觉的产生。
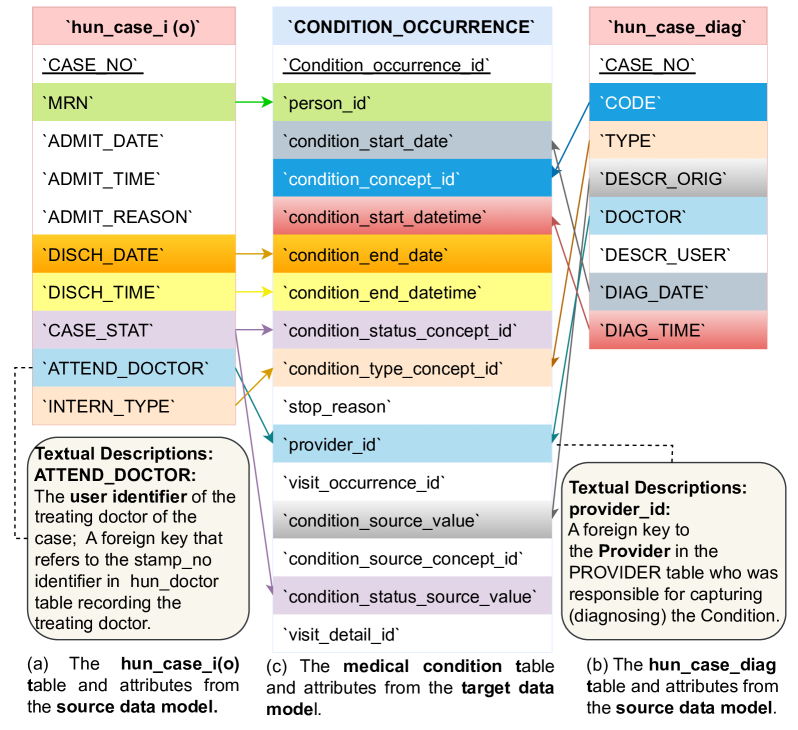
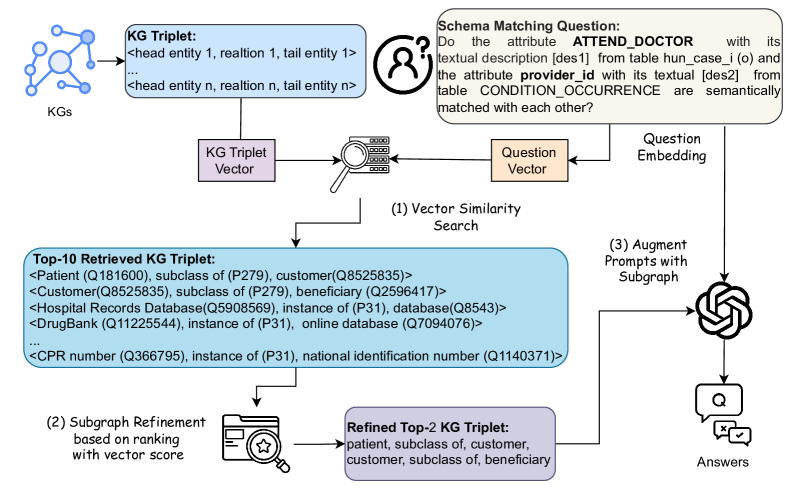
技术框架:KG-RAG4SM的整体框架包括以下几个主要阶段:1) 图检索:从大型知识图谱中检索与待匹配模式相关的子图。论文提出了基于向量、基于图遍历和基于查询的三种检索方法,以及一种混合方法。2) 排序:对检索到的子图进行排序,选择最相关的子图。3) 生成:将检索到的子图作为上下文,输入到LLM中,生成模式匹配结果。
关键创新:KG-RAG4SM的关键创新在于其知识图谱检索增强策略。与传统的RAG方法不同,KG-RAG4SM专注于从结构化的知识图谱中检索信息,并设计了多种检索方法以适应不同的匹配场景。此外,该方法无需对LLM进行重新训练,即可显著提升匹配性能。
关键设计:论文提出了多种图检索方法,包括:1) 基于向量的检索:将模式和KG中的实体嵌入到向量空间中,通过计算向量相似度来检索相关实体。2) 基于图遍历的检索:从与模式相关的实体出发,在KG中进行图遍历,检索相邻的实体和关系。3) 基于查询的检索:使用自然语言查询KG,检索与模式相关的实体和关系。论文还设计了一种混合方法,结合了上述三种检索方法的优点。此外,论文还提出了多种排序方案,用于选择最相关的子图。
🖼️ 关键图片
📊 实验亮点
实验结果表明,KG-RAG4SM在MIMIC数据集上,精确率和F1分数分别优于基于LLM的SOTA方法Jellyfish-8B 35.89%和30.50%。在Synthea数据集上,使用GPT-4o-mini的KG-RAG4SM在精确率和F1分数方面分别优于基于PLM的SOTA方法SMAT 69.20%和21.97%。这些结果表明,KG-RAG4SM能够显著提升模式匹配的性能,并有效缓解LLM的幻觉问题。
🎯 应用场景
该研究成果可应用于医疗、金融、电商等多个领域的数据集成和模式匹配任务。通过提高模式匹配的准确性,可以减少数据集成过程中的错误,提高数据质量,并为后续的数据分析和应用提供更可靠的基础。未来,该方法可以进一步扩展到处理更复杂的模式匹配场景,并与其他数据集成技术相结合,构建更智能的数据集成系统。
📄 摘要(原文)
Traditional similarity-based schema matching methods are incapable of resolving semantic ambiguities and conflicts in domain-specific complex mapping scenarios due to missing commonsense and domain-specific knowledge. The hallucination problem of large language models (LLMs) also makes it challenging for LLM-based schema matching to address the above issues. Therefore, we propose a Knowledge Graph-based Retrieval-Augmented Generation model for Schema Matching, referred to as the KG-RAG4SM. In particular, KG-RAG4SM introduces novel vector-based, graph traversal-based, and query-based graph retrievals, as well as a hybrid approach and ranking schemes that identify the most relevant subgraphs from external large knowledge graphs (KGs). We showcase that KG-based retrieval-augmented LLMs are capable of generating more accurate results for complex matching cases without any re-training. Our experimental results show that KG-RAG4SM outperforms the LLM-based state-of-the-art (SOTA) methods (e.g., Jellyfish-8B) by 35.89% and 30.50% in terms of precision and F1 score on the MIMIC dataset, respectively; KG-RAG4SM with GPT-4o-mini outperforms the pre-trained language model (PLM)-based SOTA methods (e.g., SMAT) by 69.20% and 21.97% in terms of precision and F1 score on the Synthea dataset, respectively. The results also demonstrate that our approach is more efficient in end-to-end schema matching, and scales to retrieve from large KGs. Our case studies on the dataset from the real-world schema matching scenario exhibit that the hallucination problem of LLMs for schema matching is well mitigated by our solution.