MAGNET: Augmenting Generative Decoders with Representation Learning and Infilling Capabilities
作者: Savya Khosla, Aditi Tiwari, Kushal Kafle, Simon Jenni, Handong Zhao, John Collomosse, Jing Shi
分类: cs.CL, cs.AI
发布日期: 2025-01-15 (更新: 2025-02-14)
💡 一句话要点
MAGNET:通过表征学习和文本填充增强生成式解码器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式模型 表征学习 文本填充 自监督学习 大型语言模型
📋 核心要点
- 现有语言模型通常将单向生成和双向表征学习分开训练,忽略了二者相互促进的潜力。
- MAGNET通过引入自监督训练目标和混合注意力机制,统一了生成、表征学习和文本填充任务。
- 实验表明,MAGNET在表征学习、文本填充和开放式生成任务上均取得了优异表现,并保留了预训练知识。
📝 摘要(中文)
虽然最初是为单向生成建模设计的,但仅解码器的大型语言模型(LLM)越来越多地被用于双向建模。然而,单向和双向模型通常使用不同的目标(生成和表征学习)进行单独训练。这种分离忽略了开发更通用的语言模型以及这些目标相互补充的机会。在这项工作中,我们提出了MAGNET,一种用于调整仅解码器LLM的方法,以生成鲁棒的表征并填充缺失的文本跨度。MAGNET采用三个自监督训练目标,并引入了一种结合双向和因果注意力的注意力机制,从而能够在所有目标上进行统一训练。我们的结果表明,通过MAGNET调整的LLM:(1)在token级别和句子级别的表征学习任务上超越了强大的文本编码器,(2)通过利用过去和未来的上下文生成上下文相关的文本填充,(3)执行开放式文本生成而不会过度重复单词或短语,以及(4)保留了LLM在预训练期间获得的知识和推理能力。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)通常被区分为单向生成模型和双向表征模型,它们分别使用不同的训练目标进行训练。单向模型擅长文本生成,而双向模型擅长学习文本的上下文表征。这种分离导致了模型能力的割裂,限制了模型在各种自然语言处理任务中的通用性。此外,现有的方法在文本填充任务中,无法充分利用上下文信息,导致填充结果不准确或不自然。
核心思路:MAGNET的核心思想是将生成式解码器与表征学习和文本填充能力相结合,从而创建一个更通用的语言模型。通过引入新的自监督训练目标和混合注意力机制,MAGNET能够同时学习文本的生成式和判别式表征,并利用上下文信息进行文本填充。这种统一的训练方式使得模型能够更好地理解和生成自然语言。
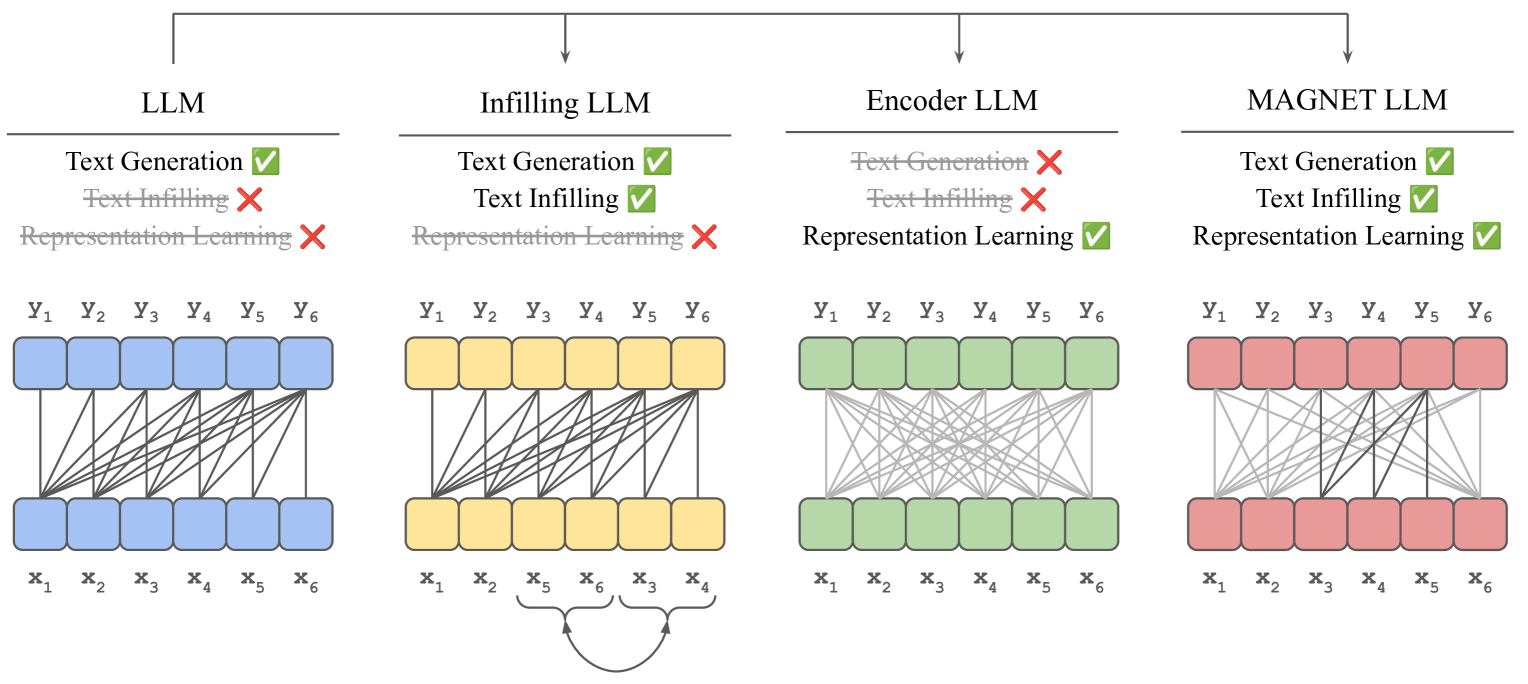
技术框架:MAGNET的整体框架包括一个标准的解码器-only LLM,以及三个自监督训练目标和一个混合注意力机制。三个自监督训练目标分别是:(1) 语言建模目标,用于训练模型的生成能力;(2) 掩码语言建模目标,用于训练模型的表征学习能力;(3) 文本填充目标,用于训练模型利用上下文信息填充缺失文本的能力。混合注意力机制结合了双向注意力和因果注意力,使得模型能够同时利用过去和未来的上下文信息。
关键创新:MAGNET的关键创新在于其统一的训练框架,该框架能够同时优化生成、表征学习和文本填充三个目标。通过引入混合注意力机制,MAGNET能够充分利用上下文信息,从而生成更准确和自然的文本填充结果。此外,MAGNET还能够保留LLM在预训练期间获得的知识和推理能力。
关键设计:MAGNET的关键设计包括:(1) 三个自监督训练目标的具体形式,例如,掩码语言建模目标采用随机掩码策略;(2) 混合注意力机制的实现方式,例如,如何将双向注意力和因果注意力进行融合;(3) 损失函数的权重设置,例如,如何平衡三个自监督训练目标之间的重要性。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
MAGNET在多个任务上取得了显著的性能提升。在表征学习任务上,MAGNET超越了强大的文本编码器,例如BERT和RoBERTa。在文本填充任务上,MAGNET能够生成上下文相关的文本填充,显著优于现有的方法。此外,MAGNET在开放式文本生成任务上表现出色,能够生成流畅自然的文本,避免了过度重复的问题。实验结果表明,MAGNET能够有效地结合生成和表征学习能力,并保留预训练知识。
🎯 应用场景
MAGNET具有广泛的应用前景,包括文本生成、文本摘要、机器翻译、问答系统、对话系统等。其强大的表征学习能力可以用于各种下游任务,例如文本分类、情感分析、命名实体识别等。此外,MAGNET的文本填充能力可以用于修复损坏的文本、生成代码补全建议等。该研究有望推动自然语言处理领域的发展,并为构建更智能的语言模型奠定基础。
📄 摘要(原文)
While originally designed for unidirectional generative modeling, decoder-only large language models (LLMs) are increasingly being adapted for bidirectional modeling. However, unidirectional and bidirectional models are typically trained separately with distinct objectives (generation and representation learning). This separation overlooks the opportunity for developing a more versatile language model and for these objectives to complement each other. In this work, we propose MAGNET, a method for adapting decoder-only LLMs to generate robust representations and infill missing text spans. MAGNET employs three self-supervised training objectives and introduces an attention mechanism that combines bidirectional and causal attention, enabling unified training across all objectives. Our results demonstrate that LLMs adapted with MAGNET (1) surpass strong text encoders on token-level and sentence-level representation learning tasks, (2) generate contextually appropriate text infills by leveraging past and future contexts, (3) perform open-ended text generation without excessive repetition of words or phrases, and (4) preserve the knowledge and reasoning capability gained by the LLM during pretraining.