LoRS: Efficient Low-Rank Adaptation for Sparse Large Language Model
作者: Yuxuan Hu, Jing Zhang, Xiaodong Chen, Zhe Zhao, Cuiping Li, Hong Chen
分类: cs.CL
发布日期: 2025-01-15
备注: 12 pages, 4 figures
💡 一句话要点
LoRS:面向稀疏大语言模型的高效低秩适配方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适配 稀疏大语言模型 模型微调 权重重计算 计算图重排 适配器初始化 内存优化
📋 核心要点
- 现有LoRA方法在稀疏LLM上无法维持稀疏性,导致效率降低,增加额外的掩码机制又会带来额外的内存和计算开销。
- LoRS通过权重重计算和计算图重排策略,在微调稀疏LLM时,显著降低内存和计算消耗,提升微调效率。
- LoRS通过改进适配器初始化,进一步提升了模型性能,实验结果表明,LoRS优于现有的LoRA方法。
📝 摘要(中文)
现有的低秩适配(LoRA)方法在稀疏大语言模型(LLM)上面临挑战,因为它们无法保持稀疏性。最近的研究引入了通过使用额外的掩码机制来增强LoRA技术从而保持稀疏性的方法。尽管取得了这些成功,但这些方法存在内存和计算开销增加的问题,这影响了LoRA方法的效率。为了应对这一限制,我们引入了LoRS,这是一种创新的方法,旨在在微调稀疏LLM时实现内存和计算效率。为了减轻与保持稀疏性相关的巨大内存和计算需求,我们的方法结合了权重重计算和计算图重排策略。此外,我们还通过更好的适配器初始化来提高LoRS的有效性。这些创新显著降低了微调阶段的内存和计算消耗,同时实现了优于现有LoRA方法的性能水平。
🔬 方法详解
问题定义:现有LoRA方法在应用于稀疏大语言模型时,无法有效保持模型的稀疏性,导致模型微调过程中计算效率降低和内存占用增加。为了维持稀疏性而引入的额外掩码机制,虽然可以提升模型性能,但进一步加剧了内存和计算开销,使得LoRA的效率优势难以发挥。因此,如何在保持稀疏性的同时,降低LoRA的内存和计算成本,是本文要解决的关键问题。
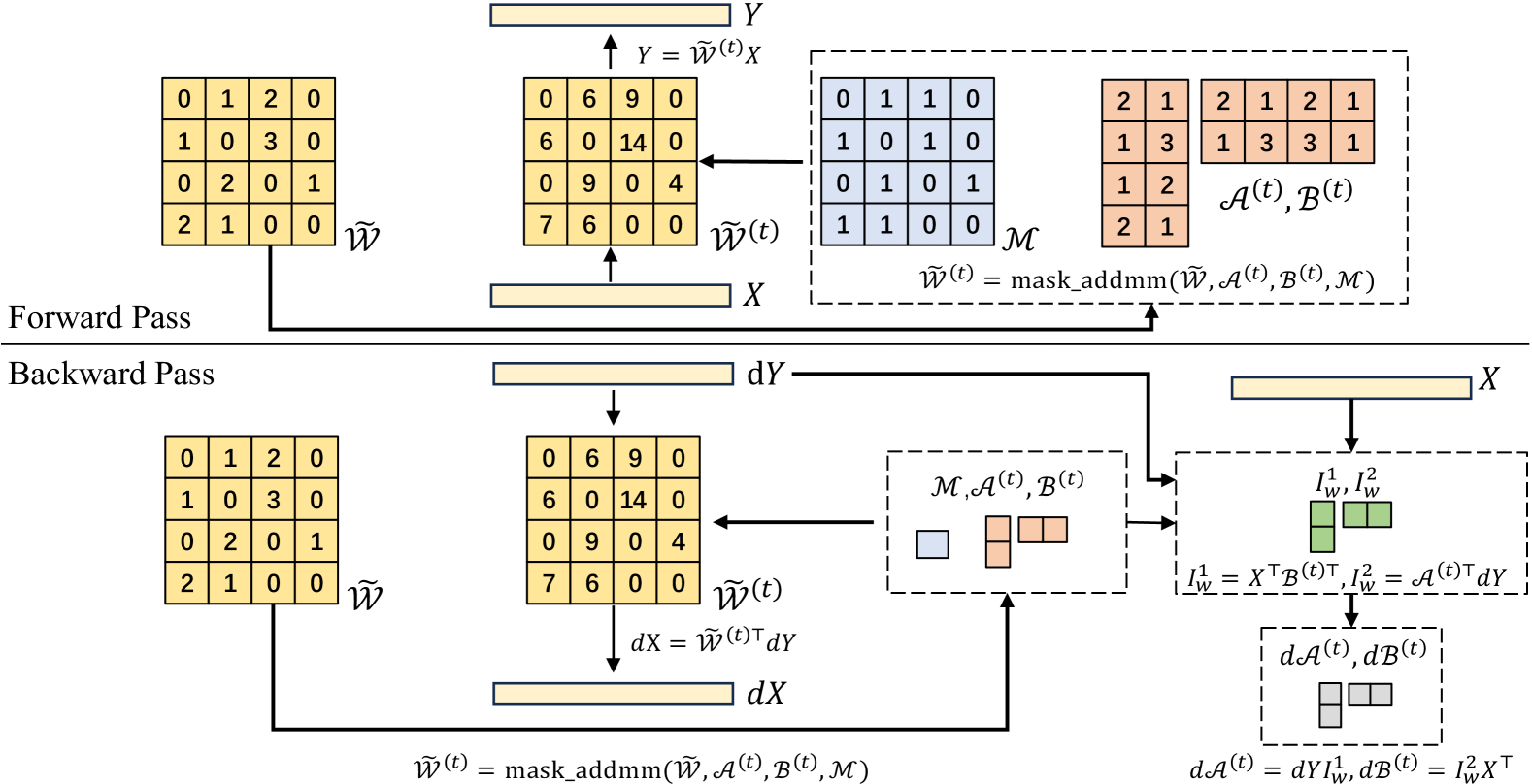
核心思路:LoRS的核心思路是通过权重重计算和计算图重排来降低内存和计算开销,同时改进适配器初始化以提升模型性能。权重重计算减少了存储中间激活值的需求,计算图重排优化了计算流程,从而降低了计算复杂度。改进的适配器初始化方法能够使模型更快地收敛,并达到更好的性能。
技术框架:LoRS方法主要包含以下几个阶段:1) 稀疏LLM的加载;2) LoRA适配器的添加,并使用改进的初始化方法;3) 权重重计算和计算图重排的实现;4) 使用优化后的计算图进行微调训练。整个框架旨在在保持稀疏性的前提下,降低微调过程中的内存和计算成本。
关键创新:LoRS的关键创新在于:1) 提出了权重重计算和计算图重排策略,有效降低了微调过程中的内存和计算开销;2) 改进了适配器的初始化方法,提升了模型的收敛速度和最终性能。与现有方法相比,LoRS能够在保持或提升模型性能的同时,显著降低资源消耗。
关键设计:权重重计算的具体实现方式是,在反向传播过程中,重新计算前向传播所需的激活值,而不是存储它们。计算图重排涉及到对计算流程的优化,例如将一些计算操作合并或重新排序,以减少计算量。适配器初始化采用了一种更有效的策略,例如使用正交初始化或Xavier初始化,以加速模型的收敛。损失函数采用标准的交叉熵损失函数,优化器可以选择AdamW等。
🖼️ 关键图片
📊 实验亮点
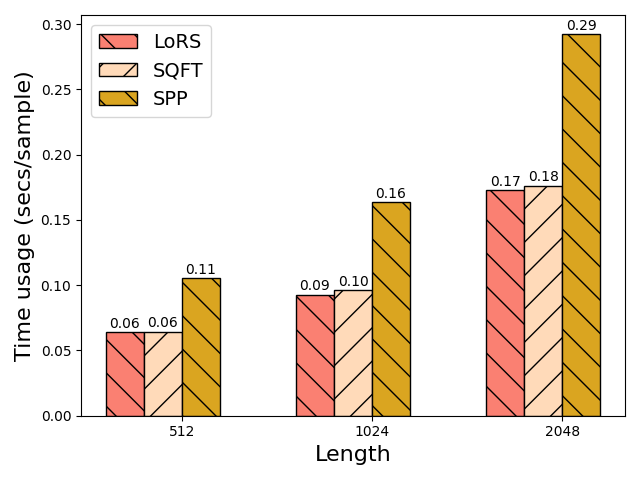
LoRS在稀疏大语言模型的微调任务上取得了显著的性能提升。实验结果表明,LoRS在保持或超过现有LoRA方法性能的同时,显著降低了内存和计算开销。具体而言,LoRS在某些任务上能够将内存占用降低20%-30%,计算时间缩短15%-25%,同时模型性能指标(如准确率、F1值)与现有LoRA方法持平或略有提升。
🎯 应用场景
LoRS方法可以广泛应用于各种需要对稀疏大语言模型进行微调的场景,例如自然语言处理、文本生成、机器翻译等。该方法尤其适用于资源受限的环境,例如移动设备或边缘计算平台。通过降低内存和计算开销,LoRS使得在这些平台上部署和微调大型语言模型成为可能,从而加速了AI技术的普及和应用。
📄 摘要(原文)
Existing low-rank adaptation (LoRA) methods face challenges on sparse large language models (LLMs) due to the inability to maintain sparsity. Recent works introduced methods that maintain sparsity by augmenting LoRA techniques with additional masking mechanisms. Despite these successes, such approaches suffer from an increased memory and computation overhead, which affects efficiency of LoRA methods. In response to this limitation, we introduce LoRS, an innovative method designed to achieve both memory and computation efficiency when fine-tuning sparse LLMs. To mitigate the substantial memory and computation demands associated with preserving sparsity, our approach incorporates strategies of weight recompute and computational graph rearrangement. In addition, we also improve the effectiveness of LoRS through better adapter initialization. These innovations lead to a notable reduction in memory and computation consumption during the fine-tuning phase, all while achieving performance levels that outperform existing LoRA approaches.