Tag&Tab: Pretraining Data Detection in Large Language Models Using Keyword-Based Membership Inference Attack
作者: Sagiv Antebi, Edan Habler, Asaf Shabtai, Yuval Elovici
分类: cs.CR, cs.CL
发布日期: 2025-01-14 (更新: 2025-09-19)
💡 一句话要点
Tag&Tab:利用关键词的成员推理攻击检测大语言模型预训练数据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预训练数据检测 成员推理攻击 关键词提取 数据安全
📋 核心要点
- 现有成员推理攻击方法在检测LLM预训练数据时准确率较低,未能充分考虑文本语义和关键词的重要性。
- Tag&Tab方法通过NLP技术标记关键词,并利用LLM计算关键词概率的平均对数似然来判断数据是否被用于预训练。
- 实验结果表明,Tag&Tab在多个数据集和LLM上显著提升了成员推理攻击的AUC分数,平均提升5.3%至17.6%。
📝 摘要(中文)
大型语言模型(LLMs)已成为重要的数字任务辅助工具。它们的训练严重依赖于大量数据的收集,其中可能包括受版权保护或敏感信息。最近关于检测LLMs中预训练数据的研究主要集中在句子或段落级别的成员推理攻击(MIAs)上,通常涉及目标模型预测token的概率分析。然而,这些方法通常表现出较差的准确性,未能考虑到文本内容的语义重要性和单词的重要性。为了解决这些缺点,我们提出了一种新颖的方法Tag&Tab,用于检测LLM预训练中使用的数据。我们的方法利用已建立的自然语言处理(NLP)技术来标记输入文本中的关键词,我们称之为Tagging。然后,LLM用于获取这些关键词的概率,并计算它们的平均对数似然以确定输入文本的成员资格,我们称之为Tabbing。我们在四个基准数据集(BookMIA、MIMIR、PatentMIA和Pile)以及几个不同大小的开源LLM上的实验表明,AUC分数平均提高了5.3%到17.6%,超过了最先进的方法。Tag&Tab不仅为LLMs中的数据泄露检测设定了新标准,而且其出色的性能证明了单词在LLMs的MIAs中的重要性。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)预训练数据泄露检测问题。现有基于句子或段落的成员推理攻击(MIA)方法准确率低,未能充分利用文本的语义信息和关键词的重要性,导致检测效果不佳。
核心思路:论文的核心思路是利用关键词在文本中的重要性,通过识别和分析输入文本中的关键词,并结合LLM对这些关键词的概率预测,来更准确地判断该文本是否被用于LLM的预训练。这种方法旨在弥补传统MIA方法对语义信息利用不足的缺陷。
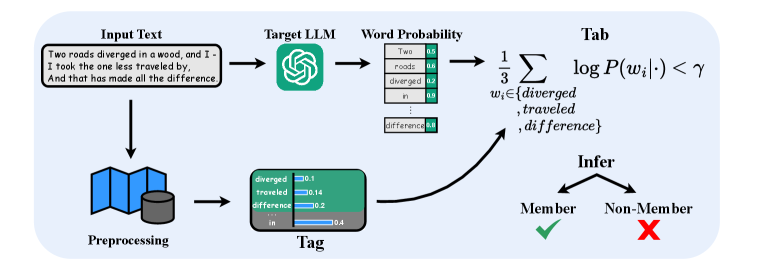
技术框架:Tag&Tab方法主要包含两个阶段:Tagging和Tabbing。Tagging阶段利用NLP技术(具体技术未知)从输入文本中提取关键词。Tabbing阶段则利用LLM计算这些关键词的概率,并计算平均对数似然。最后,根据平均对数似然值判断输入文本是否为LLM的预训练数据。
关键创新:该方法的核心创新在于将关键词提取与LLM的概率预测相结合,从而更有效地利用了文本的语义信息。与传统的基于句子或段落的MIA方法相比,Tag&Tab更加关注文本中具有代表性的关键词,从而提高了检测的准确性。
关键设计:论文中没有详细说明关键词提取的具体方法和LLM概率计算的细节。平均对数似然被用作判断成员资格的指标,但具体的阈值设置和优化方法未知。损失函数和网络结构等技术细节也未提及。
🖼️ 关键图片

📊 实验亮点
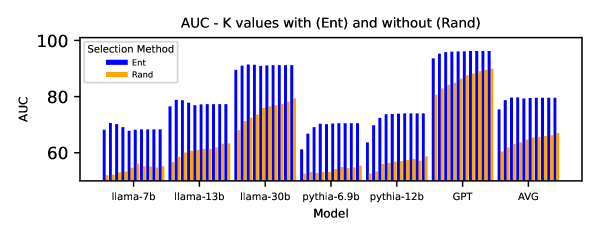
实验结果表明,Tag&Tab在BookMIA、MIMIR、PatentMIA和Pile四个基准数据集上,以及多个不同大小的开源LLM上,均取得了显著的性能提升。AUC分数平均提高了5.3%到17.6%,超过了当前最先进的方法,证明了该方法在数据泄露检测方面的有效性。
🎯 应用场景
Tag&Tab可应用于检测LLM预训练数据中是否存在版权保护或敏感信息泄露,帮助模型开发者评估和降低数据安全风险。该方法还可用于评估不同预训练数据集对模型行为的影响,从而指导数据集的选择和构建。未来,该技术可能被用于构建更安全、更负责任的LLM。
📄 摘要(原文)
Large language models (LLMs) have become essential tools for digital task assistance. Their training relies heavily on the collection of vast amounts of data, which may include copyright-protected or sensitive information. Recent studies on detecting pretraining data in LLMs have primarily focused on sentence- or paragraph-level membership inference attacks (MIAs), usually involving probability analysis of the target model's predicted tokens. However, these methods often exhibit poor accuracy, failing to account for the semantic importance of textual content and word significance. To address these shortcomings, we propose Tag&Tab, a novel approach for detecting data used in LLM pretraining. Our method leverages established natural language processing (NLP) techniques to tag keywords in the input text, a process we term Tagging. Then, the LLM is used to obtain probabilities for these keywords and calculate their average log-likelihood to determine input text membership, a process we refer to as Tabbing. Our experiments on four benchmark datasets (BookMIA, MIMIR, PatentMIA, and the Pile) and several open-source LLMs of varying sizes demonstrate an average increase in AUC scores ranging from 5.3% to 17.6% over state-of-the-art methods. Tag&Tab not only sets a new standard for data leakage detection in LLMs, but its outstanding performance is a testament to the importance of words in MIAs on LLMs.