PokerBench: Training Large Language Models to become Professional Poker Players
作者: Richard Zhuang, Akshat Gupta, Richard Yang, Aniket Rahane, Zhengyu Li, Gopala Anumanchipalli
分类: cs.CL, cs.AI, cs.GT
发布日期: 2025-01-14 (更新: 2025-01-24)
备注: AAAI 2025
💡 一句话要点
PokerBench:训练大型语言模型成为专业扑克玩家的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 扑克游戏 基准测试 非完全信息博弈 策略决策 监督学习 模型微调
📋 核心要点
- 现有大型语言模型在扑克等非完全信息博弈中表现不佳,缺乏数学、推理和策略能力。
- 提出PokerBench基准测试,包含11000个扑克场景,用于评估和提升LLM的扑克游戏能力。
- 实验表明,现有LLM在PokerBench上表现欠佳,但经过微调后性能显著提升,验证了基准的有效性。
📝 摘要(中文)
本文介绍PokerBench,一个用于评估大型语言模型(LLM)扑克游戏能力的基准。尽管LLM在传统NLP任务中表现出色,但将其应用于扑克这类复杂的策略游戏构成了一项新的挑战。扑克是一种非完全信息博弈,需要数学、推理、规划、策略以及对博弈论和人类心理学的深刻理解。这使得扑克成为大型语言模型的理想新领域。PokerBench包含与训练有素的扑克玩家合作开发的11000个最重要的场景,分为翻牌前和翻牌后游戏。我们评估了包括GPT-4、ChatGPT 3.5以及各种Llama和Gemma系列模型在内的著名模型,发现所有最先进的LLM在玩最佳扑克时表现不佳。然而,经过微调后,这些模型显示出显著的改进。我们通过让不同分数的模型相互竞争来验证PokerBench,证明PokerBench上较高的分数会导致实际扑克游戏中更高的胜率。通过微调模型和GPT-4之间的游戏,我们还发现了简单监督微调在学习最佳游戏策略方面的局限性,表明需要更先进的方法来有效地训练语言模型以擅长游戏。因此,PokerBench提供了一个独特的基准,用于快速可靠地评估LLM的扑克游戏能力,以及一个全面的基准,用于研究LLM在复杂游戏场景中的进展。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂策略游戏,特别是扑克游戏中的应用问题。现有方法,如直接使用预训练LLM进行游戏,往往由于缺乏针对性训练和对博弈论、人类心理学的理解,导致表现不佳。痛点在于如何有效地评估和提升LLM在非完全信息博弈中的决策能力。
核心思路:论文的核心思路是构建一个高质量的扑克游戏基准测试集PokerBench,并利用该基准对LLM进行微调。通过监督学习的方式,让LLM学习在各种扑克场景下的最佳策略,从而提高其游戏水平。这样设计的目的是为了提供一个标准化的评估平台,并促进LLM在复杂策略游戏领域的应用。
技术框架:PokerBench的整体框架包括以下几个主要阶段:1) 数据收集与标注:与专业扑克玩家合作,收集并标注11000个重要的扑克场景,包括翻牌前和翻牌后游戏。2) 模型选择与微调:选择主流的LLM,如GPT-4、ChatGPT 3.5、Llama和Gemma系列模型,并在PokerBench数据集上进行微调。3) 性能评估:使用PokerBench评估微调后模型的性能,并与其他模型进行对比。4) 验证与分析:通过模型之间的对战,验证PokerBench的有效性,并分析模型在游戏中的优缺点。
关键创新:论文的关键创新在于构建了一个专门用于评估和训练LLM扑克游戏能力的基准测试集PokerBench。与以往的通用型基准测试不同,PokerBench针对扑克游戏的特点,包含了大量真实且具有挑战性的场景,能够更准确地反映LLM在复杂策略游戏中的表现。
关键设计:PokerBench的关键设计包括:1) 场景选择:选择11000个最重要的扑克场景,覆盖翻牌前和翻牌后游戏,确保场景的多样性和代表性。2) 标注方式:与专业扑克玩家合作,对每个场景进行标注,提供最佳的行动建议。3) 评估指标:使用胜率作为评估指标,衡量模型在扑克游戏中的表现。4) 微调策略:采用监督学习的方式,使用PokerBench数据集对LLM进行微调,优化模型的策略决策能力。
🖼️ 关键图片
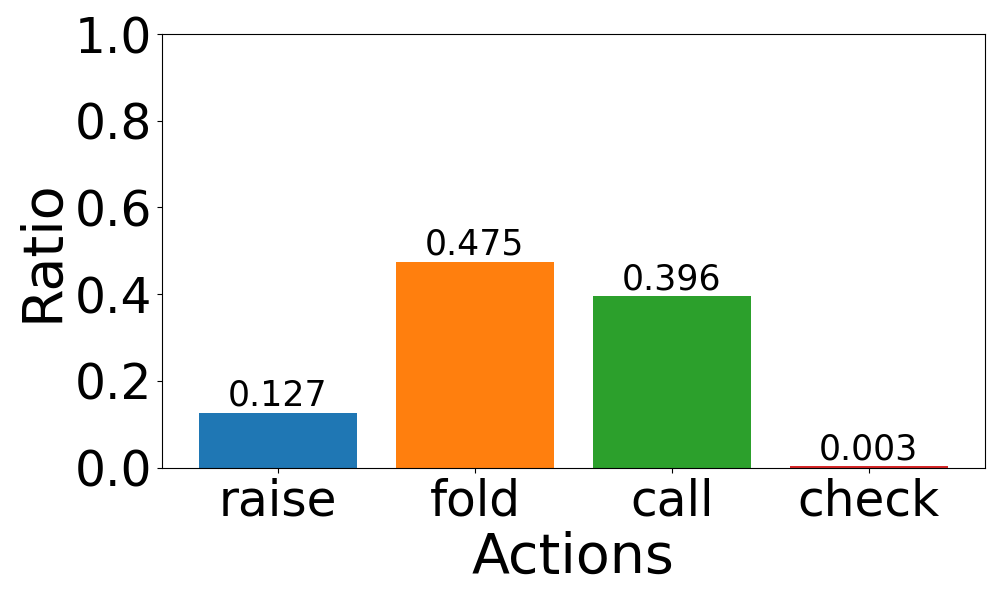
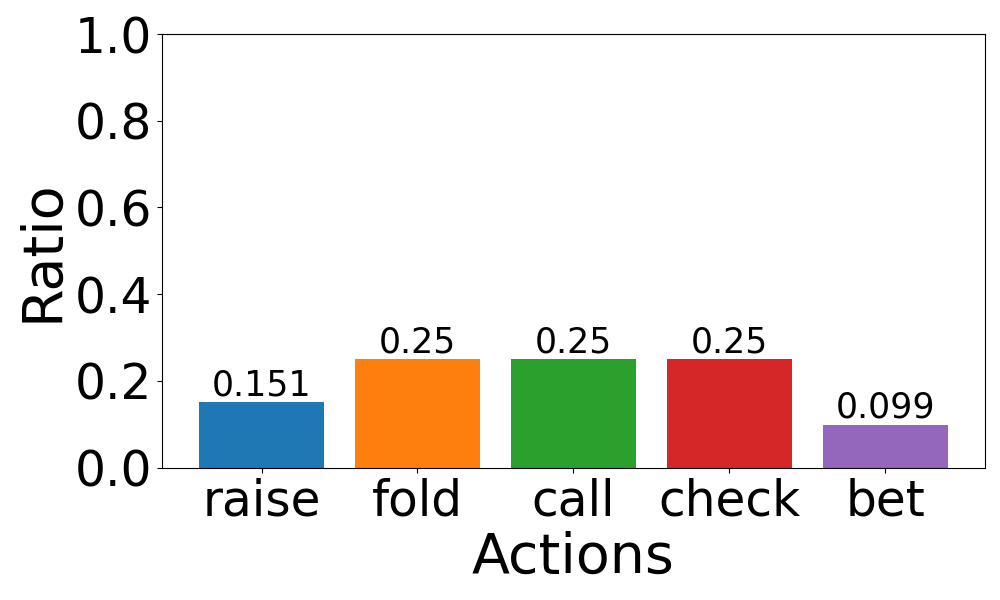

📊 实验亮点
实验结果表明,现有最先进的LLM在PokerBench上表现不佳,但在经过微调后,性能得到显著提升。通过模型之间的对战验证,PokerBench上得分较高的模型在实际扑克游戏中具有更高的胜率。此外,研究还发现简单的监督微调存在局限性,需要更先进的方法来训练LLM以达到最佳游戏策略。
🎯 应用场景
该研究成果可应用于开发更智能的博弈AI,例如在其他策略游戏中与人类玩家对抗或辅助人类玩家进行决策。此外,PokerBench提供了一种评估和提升LLM在复杂决策环境中表现的有效方法,有助于推动LLM在金融、安全等领域的应用,例如风险评估、欺诈检测等。
📄 摘要(原文)
We introduce PokerBench - a benchmark for evaluating the poker-playing abilities of large language models (LLMs). As LLMs excel in traditional NLP tasks, their application to complex, strategic games like poker poses a new challenge. Poker, an incomplete information game, demands a multitude of skills such as mathematics, reasoning, planning, strategy, and a deep understanding of game theory and human psychology. This makes Poker the ideal next frontier for large language models. PokerBench consists of a comprehensive compilation of 11,000 most important scenarios, split between pre-flop and post-flop play, developed in collaboration with trained poker players. We evaluate prominent models including GPT-4, ChatGPT 3.5, and various Llama and Gemma series models, finding that all state-of-the-art LLMs underperform in playing optimal poker. However, after fine-tuning, these models show marked improvements. We validate PokerBench by having models with different scores compete with each other, demonstrating that higher scores on PokerBench lead to higher win rates in actual poker games. Through gameplay between our fine-tuned model and GPT-4, we also identify limitations of simple supervised fine-tuning for learning optimal playing strategy, suggesting the need for more advanced methodologies for effectively training language models to excel in games. PokerBench thus presents a unique benchmark for a quick and reliable evaluation of the poker-playing ability of LLMs as well as a comprehensive benchmark to study the progress of LLMs in complex game-playing scenarios.