Exploring Robustness of Multilingual LLMs on Real-World Noisy Data
作者: Amirhossein Aliakbarzadeh, Lucie Flek, Akbar Karimi
分类: cs.CL
发布日期: 2025-01-14
💡 一句话要点
研究多语言LLM在真实噪声数据上的鲁棒性,发现mT5模型表现更优
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 鲁棒性 噪声数据 多语言 mT5
📋 核心要点
- 大型语言模型在包含噪声的Web数据上训练,但其对真实世界噪声的鲁棒性尚不明确。
- 本文通过构建真实噪声字典,评估不同规模和架构的LLM在多种语言和任务上的性能。
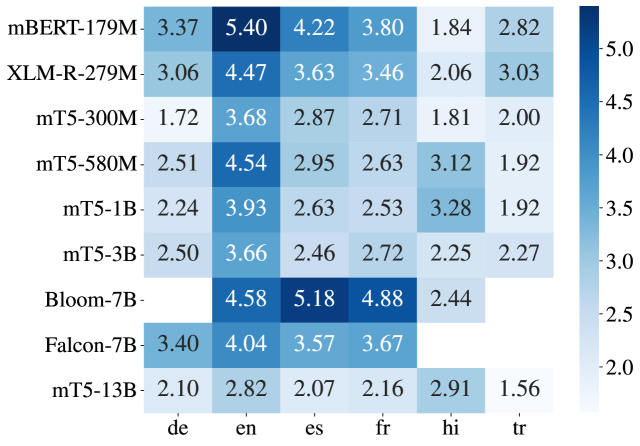
- 实验表明,模型在噪声数据上性能下降,但mT5模型表现出更强的鲁棒性,尤其以13B参数的mT5效果最佳。
📝 摘要(中文)
大型语言模型(LLMs)通常在包含人为拼写错误的Web数据上进行训练。本文旨在研究这些模型是否对类似的真实世界噪声具有鲁棒性。我们评估了9个参数规模从0.2B到13B的语言模型在6种不同语言的3个NLP任务(自然语言推理NLI、命名实体识别NER和意图分类IC)上的性能,并使用维基百科编辑历史构建了真实世界噪声字典。实验结果表明,在所有数据集和语言上,模型在干净数据和噪声数据上的性能差距平均在2.3到4.3个百分点之间。此外,与BLOOM、Falcon和类BERT模型相比,mT5模型通常表现出更强的鲁棒性。特别是,mT5 (13B)在所有3个任务和6种语言中的4种语言上,总体平均表现最为稳健。
🔬 方法详解
问题定义:本文旨在研究大型语言模型(LLMs)在面对真实世界拼写错误等噪声数据时的鲁棒性。现有LLM虽然在大量文本数据上训练,但其对真实场景中普遍存在的拼写错误、语法错误等噪声的抵抗能力仍有待考察。现有研究较少关注LLM在多语言环境下对真实噪声的鲁棒性,缺乏系统的评估和分析。
核心思路:本文的核心思路是通过构建真实世界噪声字典,模拟真实场景中的噪声数据,并评估不同LLM在这些噪声数据上的性能表现。通过对比模型在干净数据和噪声数据上的性能差异,分析其鲁棒性。同时,比较不同模型架构和参数规模对鲁棒性的影响,从而找出更具鲁棒性的模型。
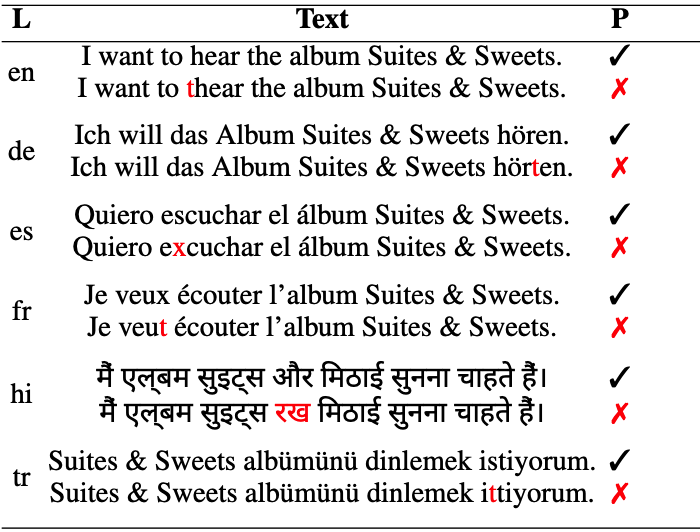
技术框架:本文的实验框架主要包括以下几个步骤:1) 数据集准备:选择涵盖多种语言和NLP任务的数据集(NLI, NER, IC)。2) 噪声字典构建:利用维基百科编辑历史,提取真实世界中常见的拼写错误和更正,构建噪声字典。3) 数据增强:使用噪声字典对原始数据集进行增强,生成包含噪声的测试数据。4) 模型评估:在干净和噪声测试数据上评估不同LLM的性能,并计算性能下降幅度。5) 结果分析:比较不同模型在不同语言和任务上的鲁棒性表现。
关键创新:本文的关键创新在于:1) 使用维基百科编辑历史构建真实世界噪声字典,更贴近实际应用场景。2) 系统评估了多种LLM在多语言环境下的鲁棒性,填补了相关研究的空白。3) 发现mT5模型在鲁棒性方面优于其他模型,为后续模型选择和优化提供了参考。
关键设计:本文的关键设计包括:1) 噪声字典的构建方法,确保噪声的真实性和多样性。2) 实验任务的选择,涵盖了不同类型的NLP任务,更全面地评估模型的鲁棒性。3) 模型的选择,涵盖了不同架构(如mT5, BLOOM, Falcon, BERT-like)和参数规模的模型,以便比较不同模型之间的差异。没有特别提到损失函数和网络结构等细节,因为主要关注的是模型对噪声的鲁棒性,而非模型本身的训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在噪声数据上的性能平均下降2.3到4.3个百分点。mT5模型,特别是13B参数的mT5,在所有任务和多种语言上表现出更强的鲁棒性,优于BLOOM、Falcon和类BERT模型。该发现为实际应用中选择合适的LLM提供了重要参考。
🎯 应用场景
该研究成果可应用于提升LLM在实际应用中的可靠性和稳定性,尤其是在处理用户生成内容、社交媒体文本等包含大量噪声的场景下。通过选择更具鲁棒性的模型或采用相应的噪声处理技术,可以提高LLM在信息抽取、情感分析、机器翻译等任务中的性能,从而提升用户体验和应用价值。未来的研究可以进一步探索更有效的噪声建模和鲁棒性训练方法。
📄 摘要(原文)
Large Language Models (LLMs) are trained on Web data that might contain spelling errors made by humans. But do they become robust to similar real-world noise? In this paper, we investigate the effect of real-world spelling mistakes on the performance of 9 language models, with parameters ranging from 0.2B to 13B, in 3 different NLP tasks, namely Natural Language Inference (NLI), Name Entity Recognition (NER), and Intent Classification (IC). We perform our experiments on 6 different languages and build a dictionary of real-world noise for them using the Wikipedia edit history. We show that the performance gap of the studied models on the clean and noisy test data averaged across all the datasets and languages ranges from 2.3 to 4.3 absolute percentage points. In addition, mT5 models, in general, show more robustness compared to BLOOM, Falcon, and BERT-like models. In particular, mT5 (13B), was the most robust on average overall, across the 3 tasks, and in 4 of the 6 languages.