Eliciting In-context Retrieval and Reasoning for Long-context Large Language Models
作者: Yifu Qiu, Varun Embar, Yizhe Zhang, Navdeep Jaitly, Shay B. Cohen, Benjamin Han
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-01-14 (更新: 2025-06-09)
💡 一句话要点
提出ICR^2基准与检索增强方法,提升长文本大模型在复杂上下文中的检索与推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本大模型 检索增强生成 上下文学习 信息检索 注意力机制
📋 核心要点
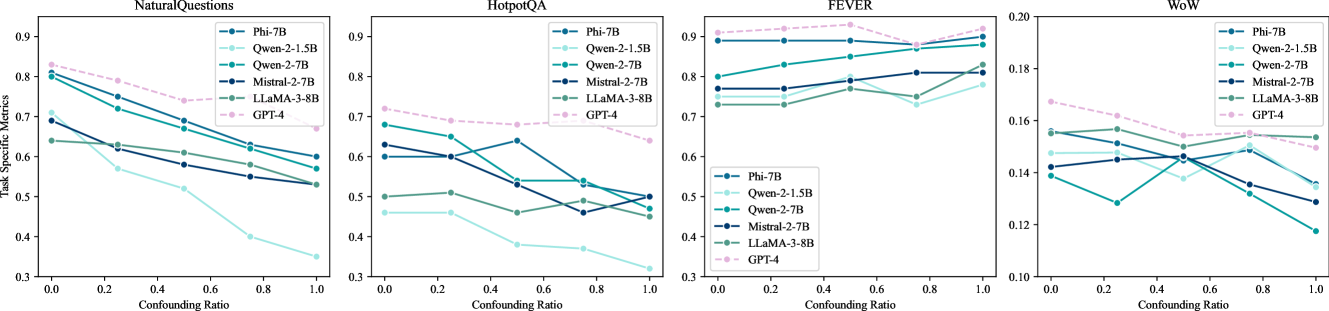
- 现有长文本大模型评测基准(如LOFT)提供的上下文过于简化,高估了模型在真实场景下的检索与推理能力。
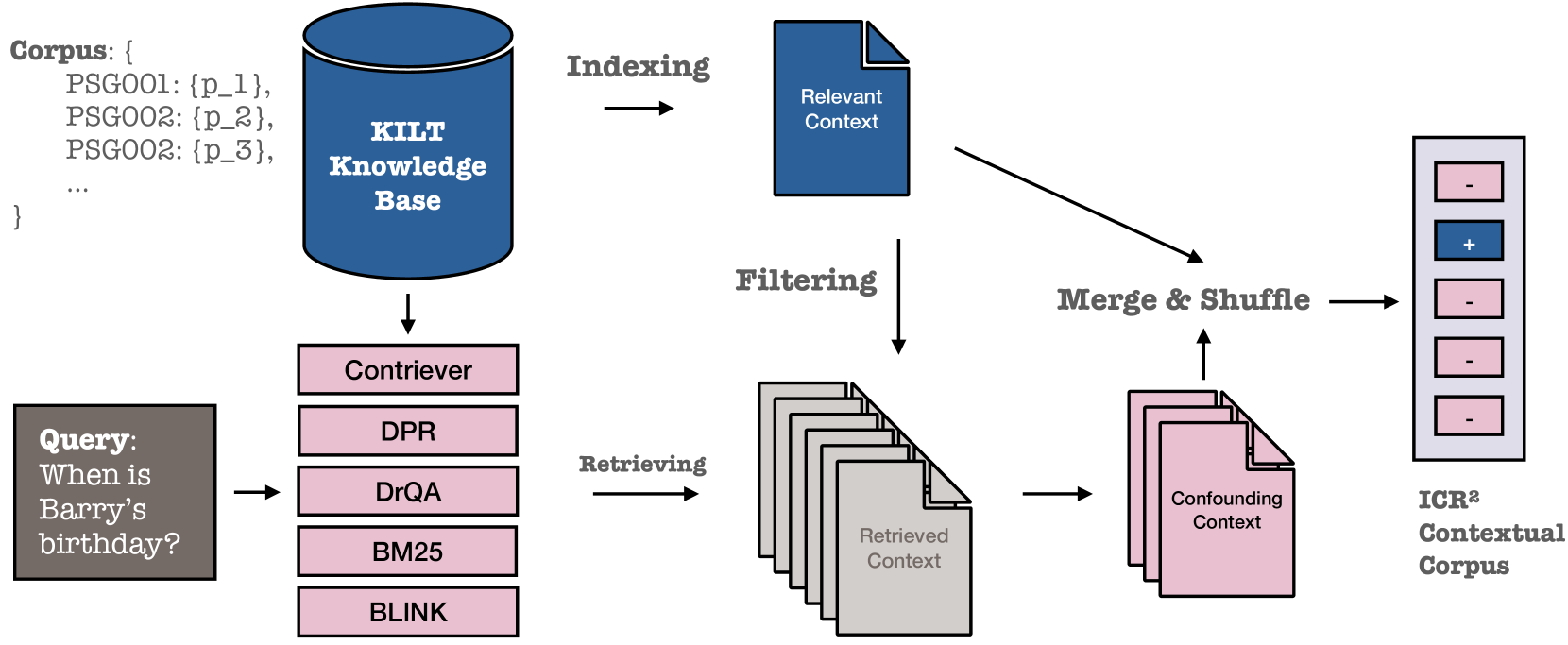
- 论文提出ICR^2基准,通过引入强检索器检索到的混淆段落,模拟更真实的复杂上下文环境,更准确地评估模型性能。
- 论文提出检索增强微调等方法,显著提升了长文本大模型在ICR^2基准上的性能,甚至超越了更大的GPT-4-Turbo模型。
📝 摘要(中文)
长文本大模型(LCLMs)的最新进展有望通过简化流程来改变检索增强生成(RAG)。凭借其扩展的上下文窗口,LCLMs可以直接处理整个知识库并执行检索和推理——我们将这种能力定义为上下文检索与推理(ICR^2)。然而,现有的基准测试(如LOFT)通常通过提供过于简化的上下文来高估LCLM的性能。为了解决这个问题,我们引入了ICR^2,该基准通过包含使用强检索器检索到的混淆段落,从而在更真实的场景中评估LCLM。然后,我们提出了三种方法来提高LCLM的性能:(1)检索-然后-生成微调,(2)检索-注意力-探测,其使用注意力头来过滤和去噪解码期间的长上下文,以及(3)与生成头联合训练检索头。我们对五个知名LCLM在LOFT和ICR^2上的评估表明,与vanilla RAG和监督微调相比,我们应用于Mistral-7B的最佳方法获得了显著的提升:在LOFT上Exact Match指标分别提升了+17和+15个点,在ICR^2上分别提升了+13和+2个点。即使是一个小得多的模型,它在大多数任务上也优于GPT-4-Turbo。
🔬 方法详解
问题定义:论文旨在解决长文本大模型在复杂上下文中的检索与推理能力不足的问题。现有方法,如直接使用长文本大模型进行检索增强生成(RAG),在面对包含混淆信息的长上下文时,性能会显著下降。现有的评测基准,如LOFT,无法真实反映这种性能下降,因为它们提供的上下文过于简化。
核心思路:论文的核心思路是构建更真实的评测基准ICR^2,并在此基础上,通过改进训练方法,提升长文本大模型在复杂上下文中的检索和推理能力。ICR^2通过引入强检索器检索到的混淆段落来模拟真实场景中的噪声信息。提出的训练方法旨在使模型能够更好地利用上下文信息,过滤噪声,并准确地进行检索和推理。
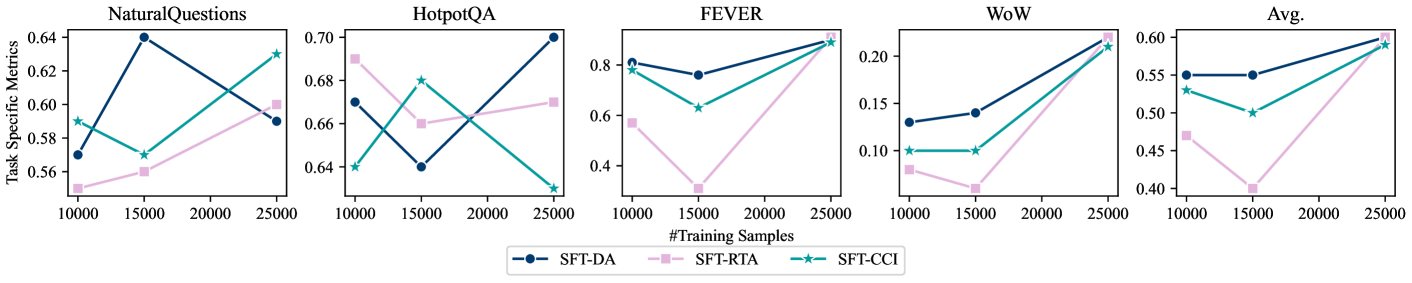
技术框架:论文的技术框架主要包含两个部分:ICR^2基准的构建和模型训练方法的改进。ICR^2基准的构建涉及使用强检索器检索与问题相关的段落,并加入混淆段落,形成包含噪声信息的长上下文。模型训练方法的改进包括:(1) 检索-然后-生成微调,(2) 检索-注意力-探测,(3) 联合训练检索头和生成头。
关键创新:论文的关键创新在于:(1) 提出了ICR^2基准,更真实地评估了长文本大模型在复杂上下文中的检索与推理能力;(2) 提出了检索-注意力-探测方法,通过注意力机制过滤和去噪长上下文,提升了模型的性能;(3) 提出了联合训练检索头和生成头的方法,使模型能够更好地进行检索和生成。
关键设计:检索-注意力-探测方法利用注意力头来识别和过滤掉长上下文中的噪声信息。具体来说,该方法首先使用注意力头计算每个上下文段落的权重,然后根据权重对段落进行过滤,最后将过滤后的上下文输入到生成模型中。联合训练检索头和生成头的方法通过共享参数或使用额外的损失函数来使检索头和生成头协同工作,从而提升模型的整体性能。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的方法在LOFT和ICR^2基准上均取得了显著的提升。在LOFT上,Exact Match指标提升了+17和+15个点,在ICR^2上提升了+13和+2个点。特别值得一提的是,应用该方法后的Mistral-7B模型在大多数任务上甚至优于GPT-4-Turbo,这表明该方法具有很强的竞争力。
🎯 应用场景
该研究成果可应用于问答系统、知识库检索、文档摘要等领域。通过提升长文本大模型在复杂上下文中的检索与推理能力,可以构建更智能、更准确的信息检索系统,帮助用户快速找到所需信息,并提高工作效率。未来,该技术有望应用于智能客服、智能助手等领域,为用户提供更优质的服务。
📄 摘要(原文)
Recent advancements in long-context language models (LCLMs) promise to transform Retrieval-Augmented Generation (RAG) by simplifying pipelines. With their expanded context windows, LCLMs can process entire knowledge bases and perform retrieval and reasoning directly -- a capability we define as In-Context Retrieval and Reasoning (ICR^2). However, existing benchmarks like LOFT often overestimate LCLM performance by providing overly simplified contexts. To address this, we introduce ICR^2, a benchmark that evaluates LCLMs in more realistic scenarios by including confounding passages retrieved with strong retrievers. We then propose three methods to enhance LCLM performance: (1) retrieve-then-generate fine-tuning, (2) retrieval-attention-probing, which uses attention heads to filter and de-noise long contexts during decoding, and (3) joint retrieval head training alongside the generation head. Our evaluation of five well-known LCLMs on LOFT and ICR^2 demonstrates significant gains with our best approach applied to Mistral-7B: +17 and +15 points by Exact Match on LOFT, and +13 and +2 points on ICR^2, compared to vanilla RAG and supervised fine-tuning, respectively. It even outperforms GPT-4-Turbo on most tasks despite being a much smaller model.