ArithmAttack: Evaluating Robustness of LLMs to Noisy Context in Math Problem Solving
作者: Zain Ul Abedin, Shahzeb Qamar, Lucie Flek, Akbar Karimi
分类: cs.CL
发布日期: 2025-01-14 (更新: 2025-07-04)
备注: Accepted to LLMSEC Workshop at ACL 2025
💡 一句话要点
ArithmAttack:评估LLM在数学问题求解中对噪声上下文的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 鲁棒性评估 数学问题求解 噪声攻击 ArithmAttack
📋 核心要点
- 大型语言模型在数学问题求解上表现出色,但其对噪声输入的抵抗能力有待考察。
- ArithmAttack通过在提示中引入标点符号噪声,评估模型在无信息损失情况下的鲁棒性。
- 实验结果表明,现有LLM对标点符号噪声敏感,噪声增加会导致性能显著下降。
📝 摘要(中文)
大型语言模型(LLM)在数学问题求解任务中表现出令人印象深刻的能力,但它们对噪声输入的鲁棒性尚未得到充分研究。我们提出了ArithmAttack,旨在检验LLM在遇到包含额外标点符号噪声的提示时的鲁棒性。ArithmAttack易于实现,且不会造成任何信息损失,因为它不会从上下文中添加或删除单词。我们评估了包括LLama3、Mistral、Mathstral和DeepSeek在内的八个LLM在含噪GSM8K和MultiArith数据集上的鲁棒性。实验表明,所有研究的模型都容易受到此类噪声的影响,并且噪声越多,性能越差。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在数学问题求解任务中,对上下文噪声的鲁棒性。现有方法缺乏对LLM在面对包含标点符号等噪声干扰时的性能评估,这限制了LLM在实际应用中的可靠性。
核心思路:论文的核心思路是通过引入一种名为ArithmAttack的噪声注入方法,系统性地评估LLM在数学问题求解任务中对噪声上下文的鲁棒性。该方法通过在输入提示中添加额外的标点符号,模拟真实场景中可能存在的噪声干扰,从而考察LLM的抗干扰能力。
技术框架:ArithmAttack的整体框架包括以下几个步骤:1)选择数学问题求解数据集(如GSM8K、MultiArith);2)针对数据集中的每个问题,生成包含不同程度标点符号噪声的提示;3)使用LLM对含噪提示进行推理,得到答案;4)将LLM的答案与标准答案进行比较,计算准确率等指标;5)分析不同噪声水平下LLM的性能变化,评估其鲁棒性。
关键创新:ArithmAttack的关键创新在于其噪声注入方式。与传统的添加或删除单词的噪声方法不同,ArithmAttack仅添加标点符号,从而保证了上下文的信息完整性,更真实地模拟了实际应用中可能遇到的噪声类型。这种方法能够更准确地评估LLM对细微噪声的敏感程度。
关键设计:ArithmAttack的关键设计包括:1)标点符号的选择:选择常见的标点符号,如逗号、句号、问号等;2)噪声水平的控制:通过调整标点符号的数量和位置,控制噪声的强度;3)评估指标的选择:采用准确率等常用指标,评估LLM的性能。
🖼️ 关键图片

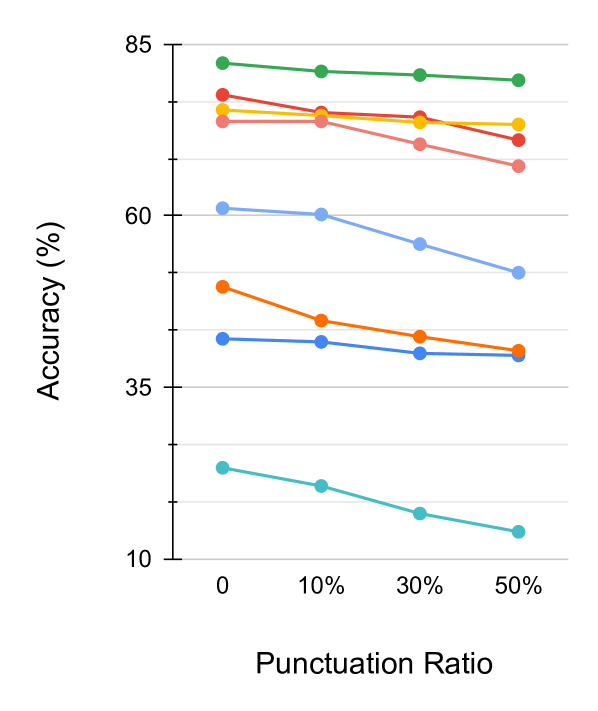

📊 实验亮点
实验结果表明,包括LLama3、Mistral、Mathstral和DeepSeek在内的多个LLM在ArithmAttack的攻击下,性能均出现显著下降。例如,在GSM8K数据集上,随着噪声水平的增加,模型的准确率下降幅度明显。这表明现有LLM对标点符号噪声非常敏感,需要进一步改进其鲁棒性。
🎯 应用场景
该研究成果可应用于提升LLM在实际应用场景中的可靠性和鲁棒性,例如在金融、医疗等领域,这些领域对模型的准确性和稳定性要求极高。通过评估和改进LLM对噪声的抵抗能力,可以提高其在复杂和不确定环境中的应用价值,并为未来的模型设计提供指导。
📄 摘要(原文)
While Large Language Models (LLMs) have shown impressive capabilities in math problem-solving tasks, their robustness to noisy inputs is not well-studied. We propose ArithmAttack to examine how robust the LLMs are when they encounter noisy prompts that contain extra noise in the form of punctuation marks. While being easy to implement, ArithmAttack does not cause any information loss since words are not added or deleted from the context. We evaluate the robustness of eight LLMs, including LLama3, Mistral, Mathstral, and DeepSeek on noisy GSM8K and MultiArith datasets. Our experiments suggest that all the studied models show vulnerability to such noise, with more noise leading to poorer performances.