A Multi-Modal AI Copilot for Single-Cell Analysis with Instruction Following
作者: Yin Fang, Xinle Deng, Kangwei Liu, Ningyu Zhang, Jingyang Qian, Penghui Yang, Xiaohui Fan, Huajun Chen
分类: cs.CL, cs.AI, cs.CE, cs.HC, cs.LG, q-bio.CB
发布日期: 2025-01-14 (更新: 2025-01-15)
备注: 37 pages; 13 figures; Code: https://github.com/zjunlp/Instructcell, Models: https://huggingface.co/zjunlp/Instructcell-chat, https://huggingface.co/zjunlp/InstructCell-instruct
💡 一句话要点
InstructCell:基于多模态AI Copilot的单细胞分析指令跟随框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单细胞分析 多模态学习 自然语言处理 AI Copilot scRNA-seq 指令跟随 细胞类型注释
📋 核心要点
- 现有单细胞分析工具交互方式效率低且不直观,难以充分利用scRNA-seq数据蕴含的生物学信息。
- InstructCell利用自然语言作为媒介,构建多模态AI Copilot,实现更直接和灵活的单细胞分析。
- InstructCell在细胞类型注释、条件伪细胞生成和药物敏感性预测等任务上表现优异,且适应性强。
📝 摘要(中文)
大型语言模型擅长解释复杂的自然语言指令,从而执行各种任务。在生命科学中,单细胞RNA测序(scRNA-seq)数据作为“细胞生物学语言”,捕获了单细胞水平上复杂的基因表达模式。然而,通过传统工具与这种“语言”交互通常效率低下且不直观,给研究人员带来了挑战。为了解决这些限制,我们提出了InstructCell,这是一种多模态AI Copilot,它利用自然语言作为更直接和灵活的单细胞分析媒介。我们构建了一个全面的多模态指令数据集,将基于文本的指令与来自不同组织和物种的scRNA-seq图谱配对。在此基础上,我们开发了一种能够同时解释和处理两种模态的多模态细胞语言架构。InstructCell使研究人员能够使用简单的自然语言命令来完成关键任务,如细胞类型注释、条件伪细胞生成和药物敏感性预测。广泛的评估表明,InstructCell始终达到或超过现有单细胞基础模型的性能,同时适应不同的实验条件。更重要的是,InstructCell提供了一种可访问且直观的工具来探索复杂的单细胞数据,降低了技术壁垒,并实现了更深入的生物学见解。
🔬 方法详解
问题定义:单细胞RNA测序(scRNA-seq)数据蕴含丰富的生物学信息,但现有分析工具通常需要专业知识和复杂的编程操作,导致研究人员难以高效地探索和利用这些数据。现有方法的痛点在于缺乏直观、灵活的交互方式,无法直接使用自然语言指令来完成分析任务。
核心思路:InstructCell的核心思路是将自然语言指令与scRNA-seq数据相结合,构建一个多模态的AI Copilot。通过训练一个能够理解和执行自然语言指令的模型,研究人员可以使用简单的语言命令来完成复杂的单细胞分析任务,从而降低技术门槛,提高研究效率。
技术框架:InstructCell的技术框架主要包括以下几个模块:1) 多模态指令数据集构建:收集并整理包含文本指令和scRNA-seq数据的配对数据集,涵盖多种组织、物种和实验条件。2) 多模态细胞语言架构:设计一个能够同时处理文本和scRNA-seq数据的模型,该模型能够理解自然语言指令,并将其转化为相应的分析操作。3) 任务执行模块:根据模型输出的分析操作,执行细胞类型注释、条件伪细胞生成和药物敏感性预测等任务。
关键创新:InstructCell的关键创新在于将自然语言指令引入单细胞分析领域,并构建了一个能够同时处理文本和scRNA-seq数据的多模态模型。与现有方法相比,InstructCell提供了一种更直观、灵活和高效的交互方式,使得研究人员可以使用自然语言指令来探索和分析单细胞数据。
关键设计:InstructCell的关键设计包括:1) 多模态数据融合策略:如何有效地将文本指令和scRNA-seq数据融合在一起,以便模型能够同时理解两种模态的信息。2) 模型架构设计:如何设计一个能够同时处理文本和scRNA-seq数据的模型,并使其能够理解自然语言指令的含义。3) 损失函数设计:如何设计合适的损失函数,以优化模型的性能,使其能够准确地执行各种单细胞分析任务。具体参数设置和网络结构等细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

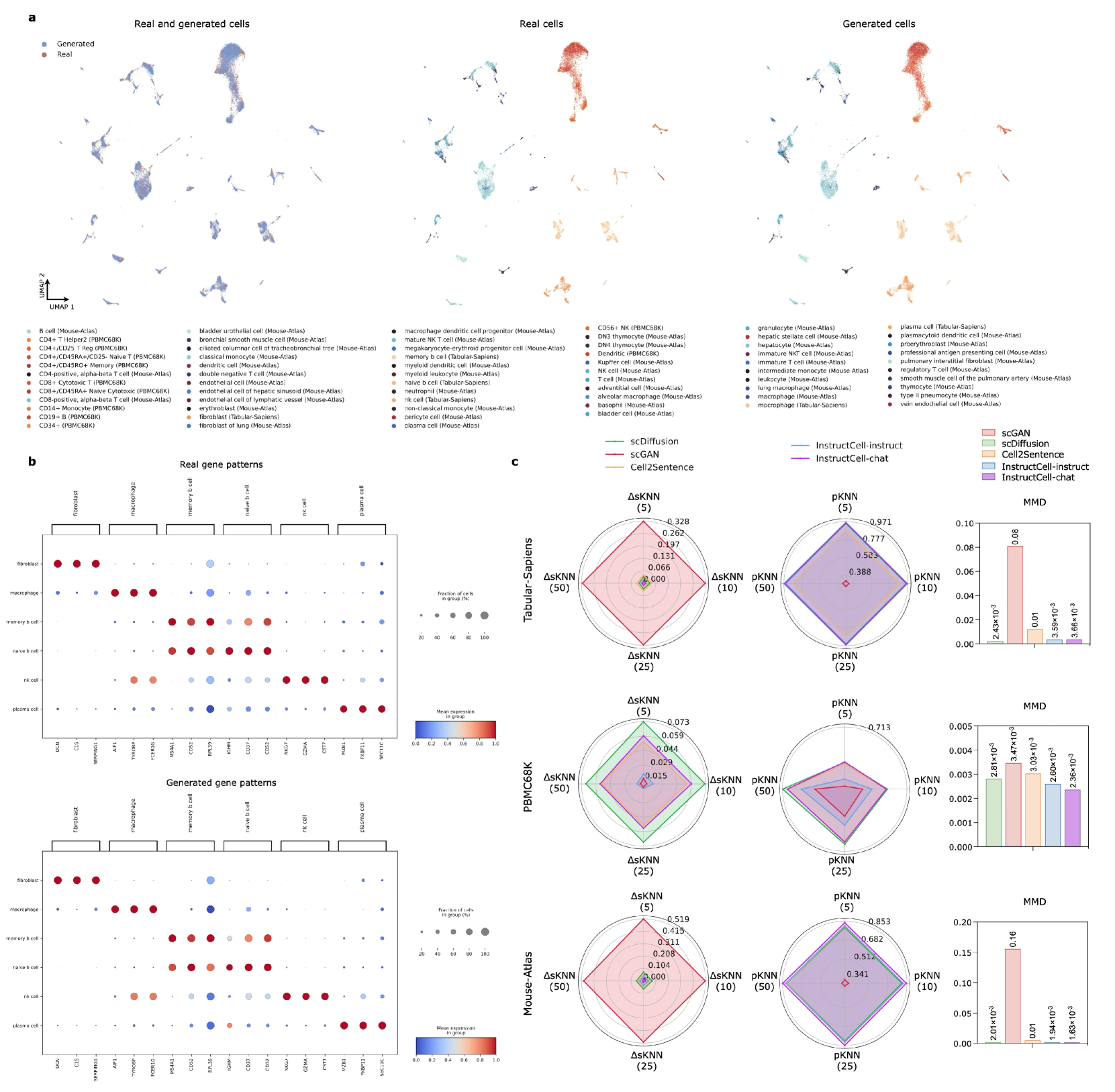
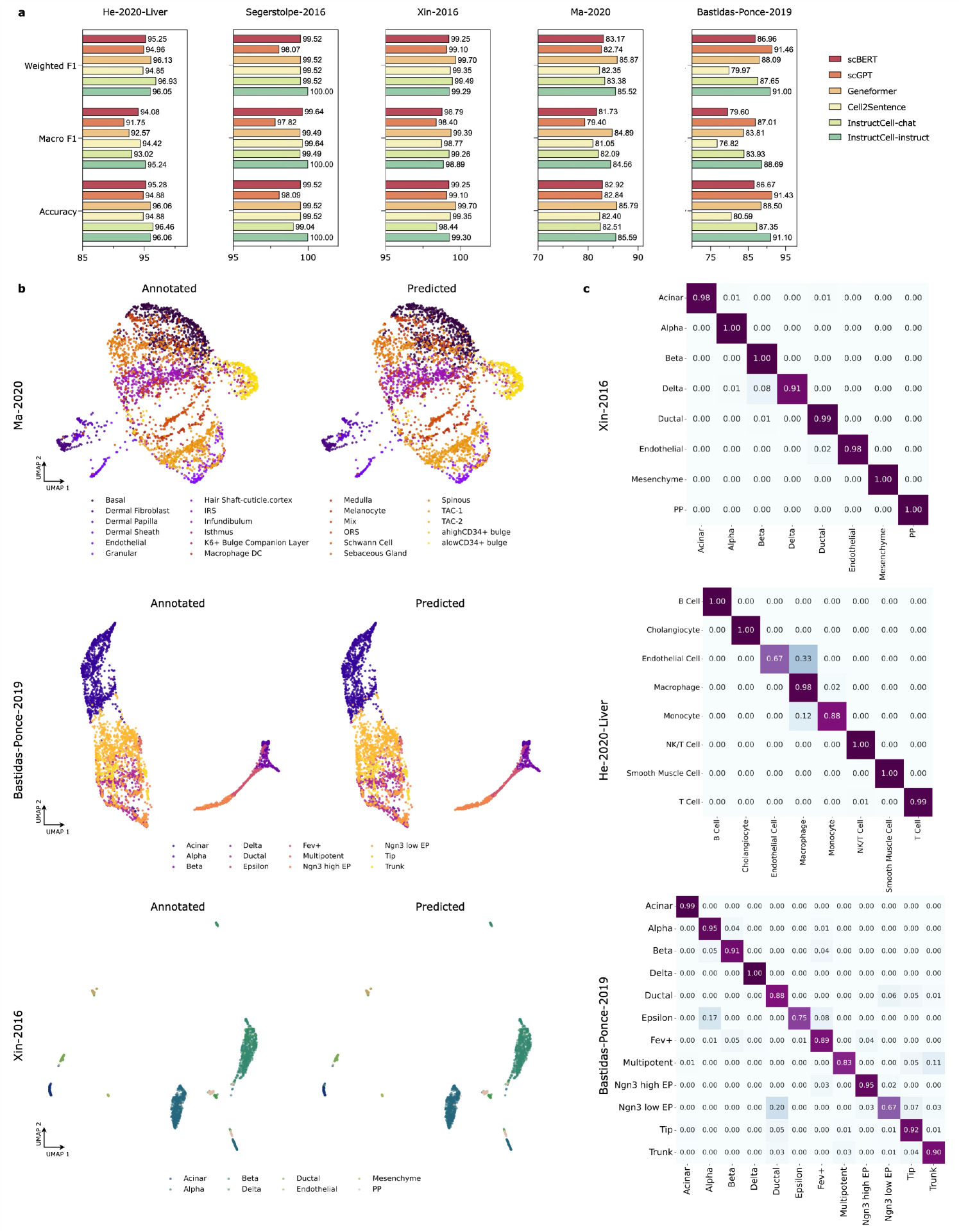
📊 实验亮点
InstructCell在细胞类型注释、条件伪细胞生成和药物敏感性预测等任务上取得了显著的成果。实验结果表明,InstructCell的性能达到或超过了现有的单细胞基础模型,并且能够适应不同的实验条件。这些结果表明,InstructCell具有很强的泛化能力和实用价值。具体的性能数据和提升幅度在论文中未明确给出,属于未知信息。
🎯 应用场景
InstructCell具有广泛的应用前景,可应用于细胞类型鉴定、疾病机制研究、药物研发等领域。通过降低单细胞分析的技术门槛,InstructCell能够帮助更多的研究人员探索和利用单细胞数据,从而加速生命科学研究的进展。未来,InstructCell有望成为单细胞分析领域的重要工具,推动个性化医疗和精准治疗的发展。
📄 摘要(原文)
Large language models excel at interpreting complex natural language instructions, enabling them to perform a wide range of tasks. In the life sciences, single-cell RNA sequencing (scRNA-seq) data serves as the "language of cellular biology", capturing intricate gene expression patterns at the single-cell level. However, interacting with this "language" through conventional tools is often inefficient and unintuitive, posing challenges for researchers. To address these limitations, we present InstructCell, a multi-modal AI copilot that leverages natural language as a medium for more direct and flexible single-cell analysis. We construct a comprehensive multi-modal instruction dataset that pairs text-based instructions with scRNA-seq profiles from diverse tissues and species. Building on this, we develop a multi-modal cell language architecture capable of simultaneously interpreting and processing both modalities. InstructCell empowers researchers to accomplish critical tasks-such as cell type annotation, conditional pseudo-cell generation, and drug sensitivity prediction-using straightforward natural language commands. Extensive evaluations demonstrate that InstructCell consistently meets or exceeds the performance of existing single-cell foundation models, while adapting to diverse experimental conditions. More importantly, InstructCell provides an accessible and intuitive tool for exploring complex single-cell data, lowering technical barriers and enabling deeper biological insights.