Consistency of Responses and Continuations Generated by Large Language Models on Social Media
作者: Wentao Xu, Wenlu Fan, Yuqi Zhu, Bin Wang
分类: cs.CL, cs.AI, cs.HC
发布日期: 2025-01-14 (更新: 2025-11-04)
备注: This paper has been accepted by the 20th International AAAI Conference on Web and Social Media (ICWSM 2026), sunny Los Angeles, California, U.S
💡 一句话要点
研究表明,大型语言模型在社交媒体文本生成中倾向于中和负面情绪。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社交媒体 情感分析 语义连贯性 文本生成
📋 核心要点
- 现有大型语言模型在社交媒体文本生成中,情感一致性和语义连贯性方面的表现尚不明确。
- 本研究通过分析LLM在延续和回应任务中的情感和语义变化,揭示其处理社交媒体文本的特点。
- 实验表明,LLM在保持语义连贯性的同时,倾向于缓和负面情绪,并降低回复的情感强度。
📝 摘要(中文)
本研究旨在深入理解大型语言模型(LLMs)在社交媒体环境中的情感一致性和语义连贯性。通过使用Gemma、Llama3、Llama3.3和Claude四个模型,分析来自Twitter和Reddit的气候变化讨论,考察LLMs在延续和回应任务中如何处理情感内容并维持语义关系。研究发现,虽然这些模型在语义上保持高度一致,但在情感模式上表现出显著差异:它们强烈倾向于缓和负面情绪。当输入文本带有愤怒、厌恶、恐惧或悲伤等负面情绪时,LLMs倾向于生成更中性甚至积极的内容。同时,与人类创作的内容相比,LLMs生成的回复在情感强度上有所降低,并且更偏好中性的理性情感。此外,这些模型都与原始文本保持了高度的语义相似性,尽管它们在延续任务和回应任务中的表现有所不同。这些发现为LLMs的情感和语义处理能力提供了深刻的见解,对于其在社交媒体环境中的部署和人机交互设计具有重要意义。
🔬 方法详解
问题定义:该论文旨在研究大型语言模型(LLMs)在社交媒体环境中生成文本时,情感表达的一致性和语义的连贯性问题。现有方法缺乏对LLM在处理社交媒体文本时情感变化的深入理解,尤其是在延续和回应任务中,LLM是否会改变或缓和原始文本的情感,以及这种改变是否会影响语义的连贯性。
核心思路:论文的核心思路是通过对比LLM生成文本与人类创作文本的情感和语义特征,来揭示LLM在社交媒体文本生成中的情感处理模式。具体来说,研究分析了LLM在延续和回应任务中,对带有不同情感色彩的文本的处理方式,以及生成文本的情感强度和语义相似度。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 数据收集:从Twitter和Reddit收集关于气候变化讨论的文本数据。2) 模型选择:选择Gemma、Llama3、Llama3.3和Claude四个LLM进行实验。3) 任务设置:设计延续任务和回应任务,让LLM基于原始文本生成新的文本。4) 情感分析:使用情感分析工具分析原始文本和LLM生成文本的情感极性和强度。5) 语义相似度计算:计算原始文本和LLM生成文本的语义相似度。6) 结果分析:对比分析LLM生成文本与人类创作文本的情感和语义特征。
关键创新:该研究的关键创新在于,它首次系统地研究了LLM在社交媒体文本生成中情感处理的倾向性,特别是LLM倾向于缓和负面情绪的现象。此外,该研究还对比了LLM在延续任务和回应任务中的表现差异,揭示了不同任务对LLM情感处理的影响。
关键设计:在任务设计方面,研究分别设计了延续任务和回应任务,以模拟社交媒体中常见的文本生成场景。在情感分析方面,研究使用了现有的情感分析工具来评估文本的情感极性和强度。在语义相似度计算方面,研究使用了余弦相似度等指标来衡量文本的语义相似度。研究没有特别提及损失函数和网络结构等技术细节,可能使用了模型自带的损失函数和预训练的网络结构。
🖼️ 关键图片
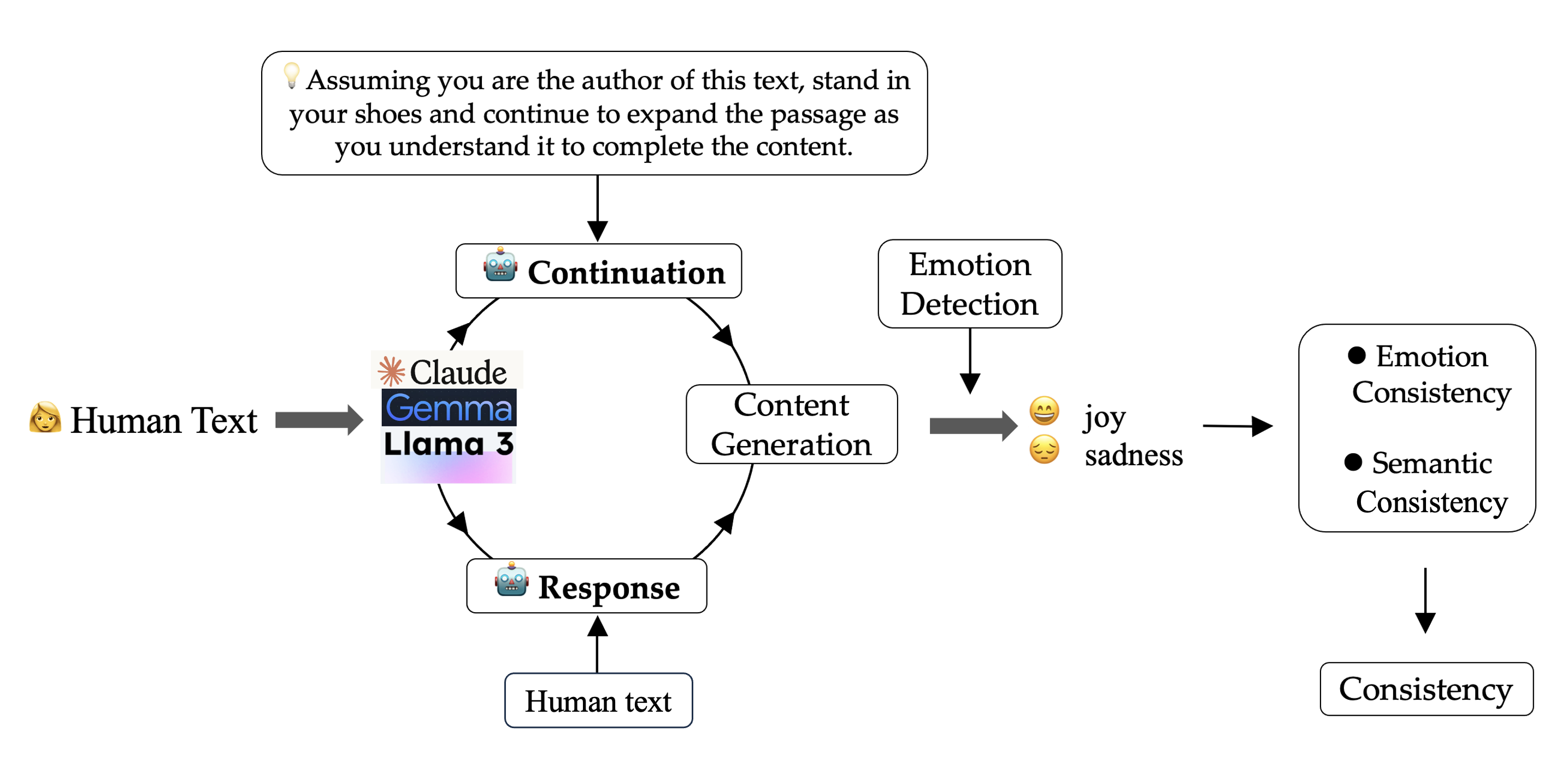
📊 实验亮点
实验结果表明,LLM在生成社交媒体文本时,普遍存在缓和负面情绪的倾向。具体来说,当输入文本带有负面情绪时,LLM倾向于生成更中性甚至积极的内容。同时,与人类创作的内容相比,LLM生成的回复在情感强度上有所降低,并且更偏好中性的理性情感。所有模型都与原始文本保持了高度的语义相似性,尽管它们在延续任务和回应任务中的表现有所不同。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、舆情分析、智能客服等领域。通过了解LLM在情感处理方面的特点,可以更好地利用LLM生成更符合人类情感需求的文本,同时也可以避免LLM生成带有不当情感倾向的内容。此外,该研究还可以为改进LLM的情感控制能力提供参考。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate remarkable capabilities in text generation, yet their emotional consistency and semantic coherence in social media contexts remain insufficiently understood. This study investigates how LLMs handle emotional content and maintain semantic relationships through continuation and response tasks using three open-source models: Gemma, Llama3 and Llama3.3 and one commercial Model:Claude. By analyzing climate change discussions from Twitter and Reddit, we examine emotional transitions, intensity patterns, and semantic consistency between human-authored and LLM-generated content. Our findings reveal that while both models maintain high semantic coherence, they exhibit distinct emotional patterns: these models show a strong tendency to moderate negative emotions. When the input text carries negative emotions such as anger, disgust, fear, or sadness, LLM tends to generate content with more neutral emotions, or even convert them into positive emotions such as joy or surprise. At the same time, we compared the LLM-generated content with human-authored content. The four models systematically generated responses with reduced emotional intensity and showed a preference for neutral rational emotions in the response task. In addition, these models all maintained a high semantic similarity with the original text, although their performance in the continuation task and the response task was different. These findings provide deep insights into the emotion and semantic processing capabilities of LLM, which are of great significance for its deployment in social media environments and human-computer interaction design.