Efficient Real-time Refinement of Language Model Text Generation
作者: Joonho Ko, Jinheon Baek, Sung Ju Hwang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-14 (更新: 2025-09-19)
备注: EMNLP 2025
💡 一句话要点
提出Streaming-VR,实现语言模型生成文本的实时高效修正。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 文本生成 实时修正 流式处理 事实准确性 错误纠正 大语言模型
📋 核心要点
- 现有语言模型修正方法需等待完整生成后才能进行,效率低下,且早期错误token易导致后续错误。
- Streaming-VR通过流式处理,在token生成过程中实时验证和修正,提升效率和准确性。
- 实验证明,Streaming-VR在多个数据集上提高了语言模型的事实准确性,且效率优于现有方法。
📝 摘要(中文)
大型语言模型(LLM)在各种自然语言任务中表现出卓越的性能。然而,一个关键的挑战仍然存在,即它们有时会生成不符合事实的答案。为了解决这个问题,虽然许多先前的工作都集中在识别其生成中的错误并进一步改进它们,但它们的部署速度很慢,因为它们被设计为仅在LLM完成整个生成(从第一个到最后一个token)之后才验证LLM的响应。此外,我们观察到,一旦LLM在早期生成了不正确的token,后续token也更有可能是不符合事实的。为此,在这项工作中,我们提出Streaming-VR(流式验证和修正),这是一种新颖的方法,旨在提高LLM输出的验证和修正效率。具体来说,所提出的Streaming-VR能够对正在生成的token进行实时验证和纠正,类似于流式处理,确保在LLM构建其响应时,每个token子集都由另一个LLM实时检查和修正。通过对多个数据集的全面评估,我们证明了我们的方法不仅提高了LLM的事实准确性,而且与先前的修正方法相比,还提供了一种更有效的解决方案。
🔬 方法详解
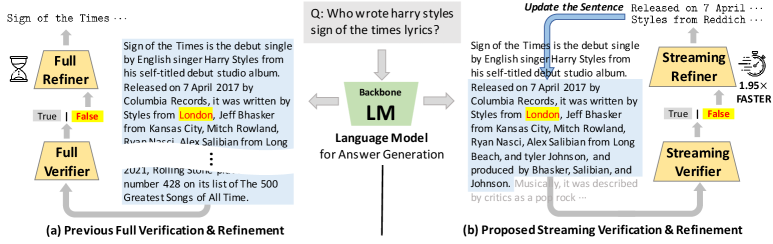
问题定义:现有的大型语言模型在生成文本时,虽然能力强大,但存在生成不符合事实内容的风险。传统的修正方法需要在整个文本生成完毕后才能进行验证和修正,导致效率低下,无法及时纠正早期出现的错误,使得后续生成的内容也可能受到影响,从而降低整体的准确性。
核心思路:Streaming-VR的核心思路是在语言模型生成文本的过程中,像流式处理一样,逐个token地进行实时验证和修正。通过尽早发现并纠正错误,避免错误信息的扩散,从而提高生成文本的整体质量和准确性。这种方法旨在实现更高效、更准确的语言模型输出。
技术框架:Streaming-VR包含两个主要模块:生成模块(Generator)和验证修正模块(Verifier & Refiner)。生成模块负责生成文本token,每生成一个或一组token,就将其传递给验证修正模块。验证修正模块使用另一个语言模型对接收到的token进行验证,如果发现错误,则进行修正。修正后的token被反馈回生成模块,用于指导后续token的生成。这个过程循环进行,直到生成完整的文本。
关键创新:Streaming-VR的关键创新在于其流式处理的验证和修正机制。与传统的后处理方法不同,Streaming-VR能够在生成过程中实时干预,及时纠正错误,从而避免错误信息的累积和扩散。这种方法能够更有效地提高生成文本的准确性和质量。
关键设计:Streaming-VR的关键设计包括:1) 如何选择合适的验证修正模型,使其能够准确地识别和修正错误;2) 如何平衡验证修正的计算成本和准确性,避免过度干预影响生成效率;3) 如何将修正后的token有效地反馈回生成模块,指导后续token的生成。具体的参数设置、损失函数和网络结构等细节取决于具体的应用场景和所使用的语言模型。
🖼️ 关键图片


📊 实验亮点
论文通过在多个数据集上的实验验证了Streaming-VR的有效性。实验结果表明,Streaming-VR不仅提高了语言模型生成文本的事实准确性,而且与传统的后处理方法相比,具有更高的效率。具体的性能提升数据在论文中进行了详细展示,证明了该方法的优越性。
🎯 应用场景
Streaming-VR可应用于各种需要高准确性和实时性的文本生成场景,例如:智能客服、新闻报道、金融分析等。通过实时验证和修正,可以有效减少错误信息的传播,提高用户信任度。未来,该技术有望与知识图谱等技术结合,进一步提升语言模型的生成质量和可靠性。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable performance across a wide range of natural language tasks. However, a critical challenge remains in that they sometimes generate factually incorrect answers. To address this, while many previous work has focused on identifying errors in their generation and further refining them, they are slow in deployment since they are designed to verify the response from LLMs only after their entire generation (from the first to last tokens) is done. Further, we observe that once LLMs generate incorrect tokens early on, there is a higher likelihood that subsequent tokens will also be factually incorrect. To this end, in this work, we propose Streaming-VR (Streaming Verification and Refinement), a novel approach designed to enhance the efficiency of verification and refinement of LLM outputs. Specifically, the proposed Streaming-VR enables on-the-fly verification and correction of tokens as they are being generated, similar to a streaming process, ensuring that each subset of tokens is checked and refined in real-time by another LLM as the LLM constructs its response. Through comprehensive evaluations on multiple datasets, we demonstrate that our approach not only enhances the factual accuracy of LLMs, but also offers a more efficient solution compared to prior refinement methods.