LLMic: Romanian Foundation Language Model
作者: Vlad-Andrei Bădoiu, Mihai-Valentin Dumitru, Alexandru M. Gherghescu, Alexandru Agache, Costin Raiciu
分类: cs.CL
发布日期: 2025-01-13
💡 一句话要点
LLMic:面向罗马尼亚语的开源基础语言模型,性能媲美大型模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低资源语言 罗马尼亚语 机器翻译 预训练 微调 Transformer模型
📋 核心要点
- 开源LLM在低资源语言上表现不佳,主要原因是训练数据中对这些语言的覆盖不足。
- LLMic通过构建专门针对罗马尼亚语的双语基础模型,并记录了完整的预训练流程来解决这一问题。
- 实验结果表明,LLMic在罗马尼亚语任务上可与其他大型开源模型媲美,并在英-罗翻译上优于现有方案。
📝 摘要(中文)
大型语言模型(LLM)的最新进展在各种任务中展现了卓越的能力,其中商业模型处于领先地位。虽然开源模型通常规模较小,但它们通过专业化和微调保持竞争力。然而,一个重要的挑战依然存在:由于训练语料库中的代表性有限,开源模型在低资源语言上的表现通常不佳。在本文中,我们提出了LLMic,一种专门为罗马尼亚语设计的双语基础语言模型。我们记录了为低资源语言预训练基础模型的完整过程,包括语料库构建、架构选择和超参数优化。我们的评估表明,LLMic可以专门用于目标语言的任务,达到与其他更大的开源模型相当的结果。我们表明,在初始预训练阶段之后,对LLMic进行语言翻译的微调优于现有的英语到罗马尼亚语翻译解决方案。这为罗马尼亚语社区使用更小的LLMic模型进行高效的大规模处理开辟了道路。
🔬 方法详解
问题定义:论文旨在解决低资源语言(特别是罗马尼亚语)在大型语言模型领域中表现不佳的问题。现有开源模型由于训练数据中罗马尼亚语的占比过低,无法有效处理该语言相关的任务。这限制了罗马尼亚语社区利用LLM进行大规模语言处理的能力。
核心思路:论文的核心思路是构建一个专门针对罗马尼亚语的双语基础语言模型(LLMic),并通过精心设计的预训练流程,使其能够有效地学习和处理罗马尼亚语。通过专注于目标语言,可以在模型规模较小的情况下,达到甚至超过大型通用模型在特定语言上的性能。
技术框架:LLMic的构建过程主要包括以下几个阶段:1) 语料库构建:收集和整理包含罗马尼亚语和英语的大规模文本数据。2) 架构选择:选择合适的Transformer模型架构作为LLMic的基础。3) 预训练:使用构建的语料库对LLMic进行预训练,使其学习语言的统计规律和语义信息。4) 微调:针对特定任务(如语言翻译)对预训练的LLMic进行微调,以提高其在该任务上的性能。
关键创新:LLMic的关键创新在于其专注于低资源语言,并提供了一个完整的、可复现的预训练流程。这包括详细的语料库构建方法、架构选择依据和超参数优化策略。此外,论文还展示了通过微调,LLMic可以在特定任务上超越现有解决方案,证明了其有效性和潜力。
关键设计:论文详细记录了语料库的构建过程,包括数据来源、清洗方法和数据量。架构方面,选择了Transformer模型,并可能根据计算资源和性能需求进行了调整。预训练过程中,采用了标准的语言建模目标,并优化了学习率、batch size等超参数。微调阶段,针对特定任务设计了相应的损失函数和训练策略。
🖼️ 关键图片
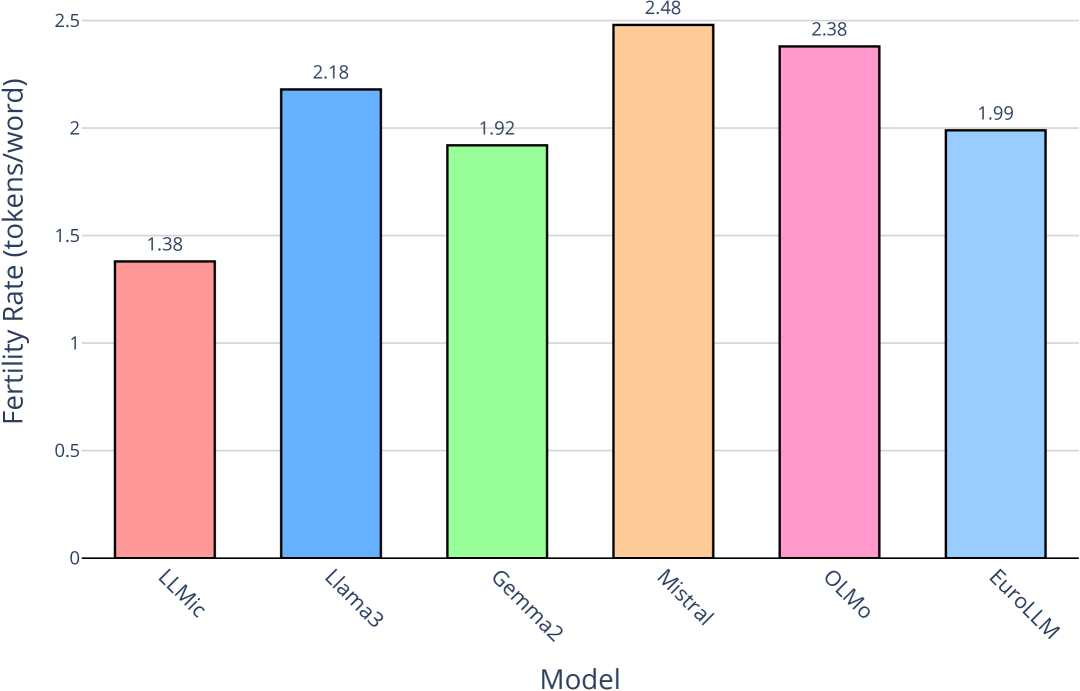
📊 实验亮点
实验结果表明,LLMic在罗马尼亚语任务上表现出色,可以与其他更大的开源模型相媲美。更重要的是,在英语到罗马尼亚语的翻译任务中,经过微调的LLMic优于现有的翻译解决方案,证明了其在低资源语言处理方面的优势。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
LLMic的潜在应用领域包括机器翻译、文本摘要、问答系统、情感分析等,特别是在罗马尼亚语相关的应用中。该模型可以为罗马尼亚语社区提供更高效、更准确的语言处理能力,促进该语言在数字世界的传播和应用。此外,LLMic的构建经验也可以为其他低资源语言的LLM研究提供借鉴。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks with commercial models leading the way. While open models usually operate at a smaller scale, they maintain competitiveness through specialization and fine-tuning. However, a significant challenge persists: open models often underperform in low-resource languages due to limited representation in the training corpus. In this paper, we present LLMic, a bilingual foundation language model designed specifically for the Romanian Language. We document the complete process of pretraining a foundation model for a low-resource language, including corpus construction, architecture selection, and hyper-parameter optimization. Our evaluation demonstrates that LLMic can be specialized for tasks in the target language, achieving results comparable to other much larger open models. We show that fine-tuning LLMic for language translation after the initial pretraining phase outperforms existing solutions in English-to-Romanian translation tasks. This opens the path for efficient large-scale processing for the Romanian language community, using the much smaller LLMic model