Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
作者: Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vulić, Furu Wei
分类: cs.CL, cs.CV, cs.LG
发布日期: 2025-01-13
备注: 11 pages, 6 figures, 4 tables (27 pages, 10 figures, 16 tables including references and appendices)
💡 一句话要点
提出多模态思维可视化(MVoT),增强MLLM在空间推理任务中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 空间推理 视觉思考 大型语言模型 思维可视化
📋 核心要点
- 大型语言模型在复杂推理中表现出色,但在空间推理任务中面临挑战。
- MVoT通过生成推理过程的图像,使MLLM能够进行视觉思考,弥补了语言推理的不足。
- 实验表明,MVoT在动态空间推理任务中表现出竞争力,尤其在CoT失败的场景下提升显著。
📝 摘要(中文)
本文提出了一种新的推理范式——多模态思维可视化(MVoT),旨在提升多模态大型语言模型(MLLM)在复杂空间推理任务中的能力。MVoT通过生成推理过程的图像可视化来实现视觉思考。为了保证高质量的可视化效果,本文在自回归MLLM中引入了token差异损失,显著提高了视觉连贯性和保真度。通过多个动态空间推理任务验证了该方法的有效性。实验结果表明,MVoT在各项任务中表现出强大的竞争力,尤其是在CoT失败的最具挑战性的场景中,展现出稳健可靠的改进。MVoT为复杂推理任务开辟了新的可能性,视觉思考可以有效地补充语言推理。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在复杂空间推理任务中表现不佳的问题。现有的Chain-of-Thought (CoT)方法虽然在语言推理方面表现出色,但在处理需要空间理解的任务时存在局限性,无法充分利用视觉信息进行推理。
核心思路:论文的核心思路是模仿人类同时进行语言和图像思考的能力,提出Multimodal Visualization-of-Thought (MVoT)方法。该方法通过让MLLM生成推理过程的图像可视化,从而实现视觉思考,并将其与语言推理相结合,以提升空间推理能力。这样设计的目的是为了让模型能够更直观地理解空间关系,从而做出更准确的判断。
技术框架:MVoT的技术框架主要包含以下几个阶段:首先,输入包含空间信息的文本描述;然后,MLLM根据文本描述生成推理步骤,并为每个步骤生成对应的图像可视化;最后,MLLM结合文本和图像信息进行最终的推理判断。整个过程是自回归的,即每一步的输出都会影响下一步的生成。
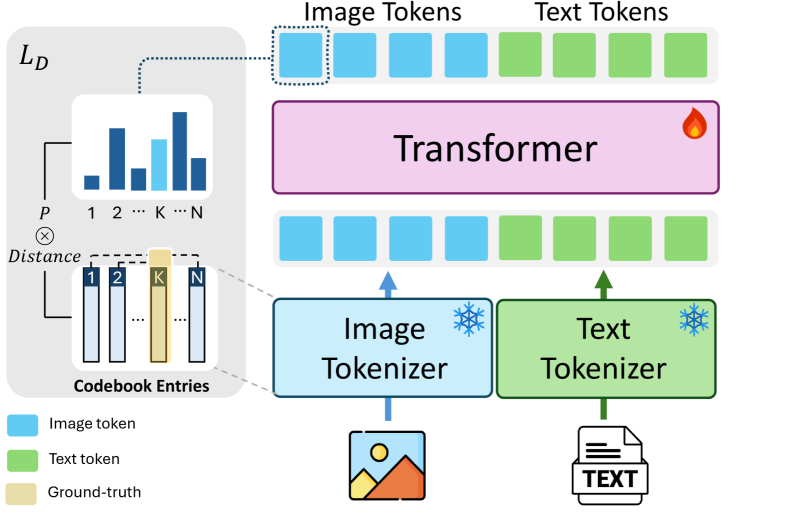
关键创新:论文最重要的技术创新点在于引入了token discrepancy loss。该损失函数用于训练MLLM生成高质量的图像可视化,具体来说,它鼓励生成的图像与预期的图像在token级别上保持一致,从而提高视觉连贯性和保真度。这与传统的图像生成方法不同,传统方法通常只关注像素级别的差异,而忽略了图像的语义信息。
关键设计:在训练过程中,论文使用了预训练的MLLM作为基础模型,并在此基础上进行微调。Token discrepancy loss的具体计算方式未知,但可以推测是基于某种图像tokenization方法(例如VQ-VAE)来计算生成图像和目标图像之间的差异。此外,论文可能还使用了其他正则化技术来防止过拟合,并提高模型的泛化能力。具体的网络结构和参数设置未知。
🖼️ 关键图片

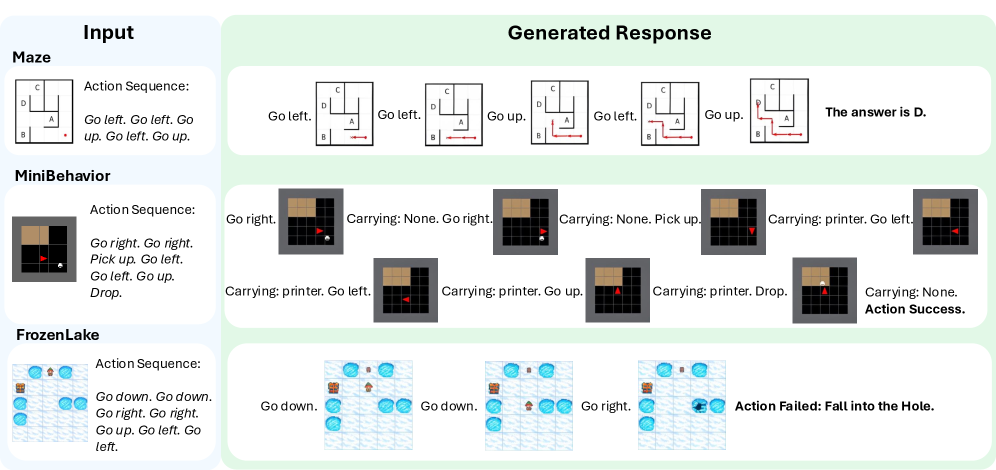
📊 实验亮点
实验结果表明,MVoT在多个动态空间推理任务中表现出强大的竞争力。尤其是在CoT方法失效的复杂场景下,MVoT展现出显著的性能提升,验证了视觉思考在空间推理中的有效性。具体的性能数据和提升幅度未知,但摘要强调了MVoT在最具挑战性的场景下的稳健性和可靠性。
🎯 应用场景
MVoT方法具有广泛的应用前景,例如机器人导航、自动驾驶、游戏AI、以及需要空间推理能力的虚拟现实应用。通过将视觉思考融入到机器的推理过程中,可以显著提升机器在复杂环境中的适应性和决策能力,从而实现更智能、更可靠的自动化系统。未来,该方法还可以扩展到其他需要多模态推理的任务中,例如医学图像诊断、视频内容理解等。
📄 摘要(原文)
Chain-of-Thought (CoT) prompting has proven highly effective for enhancing complex reasoning in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Yet, it struggles in complex spatial reasoning tasks. Nonetheless, human cognition extends beyond language alone, enabling the remarkable capability to think in both words and images. Inspired by this mechanism, we propose a new reasoning paradigm, Multimodal Visualization-of-Thought (MVoT). It enables visual thinking in MLLMs by generating image visualizations of their reasoning traces. To ensure high-quality visualization, we introduce token discrepancy loss into autoregressive MLLMs. This innovation significantly improves both visual coherence and fidelity. We validate this approach through several dynamic spatial reasoning tasks. Experimental results reveal that MVoT demonstrates competitive performance across tasks. Moreover, it exhibits robust and reliable improvements in the most challenging scenarios where CoT fails. Ultimately, MVoT establishes new possibilities for complex reasoning tasks where visual thinking can effectively complement verbal reasoning.