TiEBe: Tracking Language Model Recall of Notable Worldwide Events Through Time
作者: Thales Sales Almeida, Giovana Kerche Bonás, João Guilherme Alves Santos, Hugo Abonizio, Rodrigo Nogueira
分类: cs.CL, cs.AI
发布日期: 2025-01-13 (更新: 2025-05-20)
💡 一句话要点
TiEBe:通过时间追踪语言模型对全球重大事件的记忆能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识回忆 时间事件 地域差异 多语言评估
📋 核心要点
- 现有LLM基准测试缺乏对模型随时间和跨区域知识保持能力的深入评估,无法有效衡量其对时事和地域性事件的理解。
- TiEBe通过构建包含全球和区域事件的问答数据集,利用维基百科数据并结合外部事实证据,来评估LLM对不同时间和地域事件的记忆能力。
- 实验结果表明,LLM在不同地域的事实回忆方面存在显著差异,且性能与社会经济指标相关,低资源语言的表现明显落后。
📝 摘要(中文)
随着知识格局的演变和大型语言模型(LLM)的日益普及,保持这些模型与时俱进的需求日益增长。虽然现有的基准测试评估了一般的知识回忆,但很少有研究探讨LLM如何随时间或跨不同地区保持知识。为了解决这些差距,我们提出了时间事件基准(TiEBe),这是一个包含超过23,000个问答对的数据集,围绕着重要的全球和区域事件,跨越超过10年的事件,23个地区和13种语言。TiEBe利用维基百科的结构化回顾数据来识别随时间推移的重要事件。然后,这些事件被用于构建基准,以评估LLM对全球和区域发展的理解,这些理解基于维基百科之外的事实证据。我们的结果揭示了事实回忆中显著的地域差异,强调需要在LLM训练中实现更平衡的全球代表性。我们还观察到模型在TiEBe中的表现与各个国家的社会经济指标(如人类发展指数HDI)之间存在超过0.7的皮尔逊相关性。此外,我们通过以每个事件发生地区的母语提出问题来检验语言对事实回忆的影响,揭示了低资源语言的巨大性能差距。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)对全球重大事件的知识随时间和地域变化的记忆能力评估问题。现有方法主要集中在通用知识的评估,缺乏对LLM在特定时间和地点发生的事件的记忆能力进行细致评估的手段。此外,现有基准测试往往忽略了不同语言和文化背景下的知识差异,导致对LLM的全球知识覆盖范围评估不足。
核心思路:论文的核心思路是构建一个包含时间、地域和语言信息的多样化问答数据集,用于评估LLM对全球重大事件的记忆能力。通过分析LLM在不同时间段、不同地区和不同语言下的表现,揭示其知识的局限性和偏差,从而为改进LLM的训练和评估提供依据。
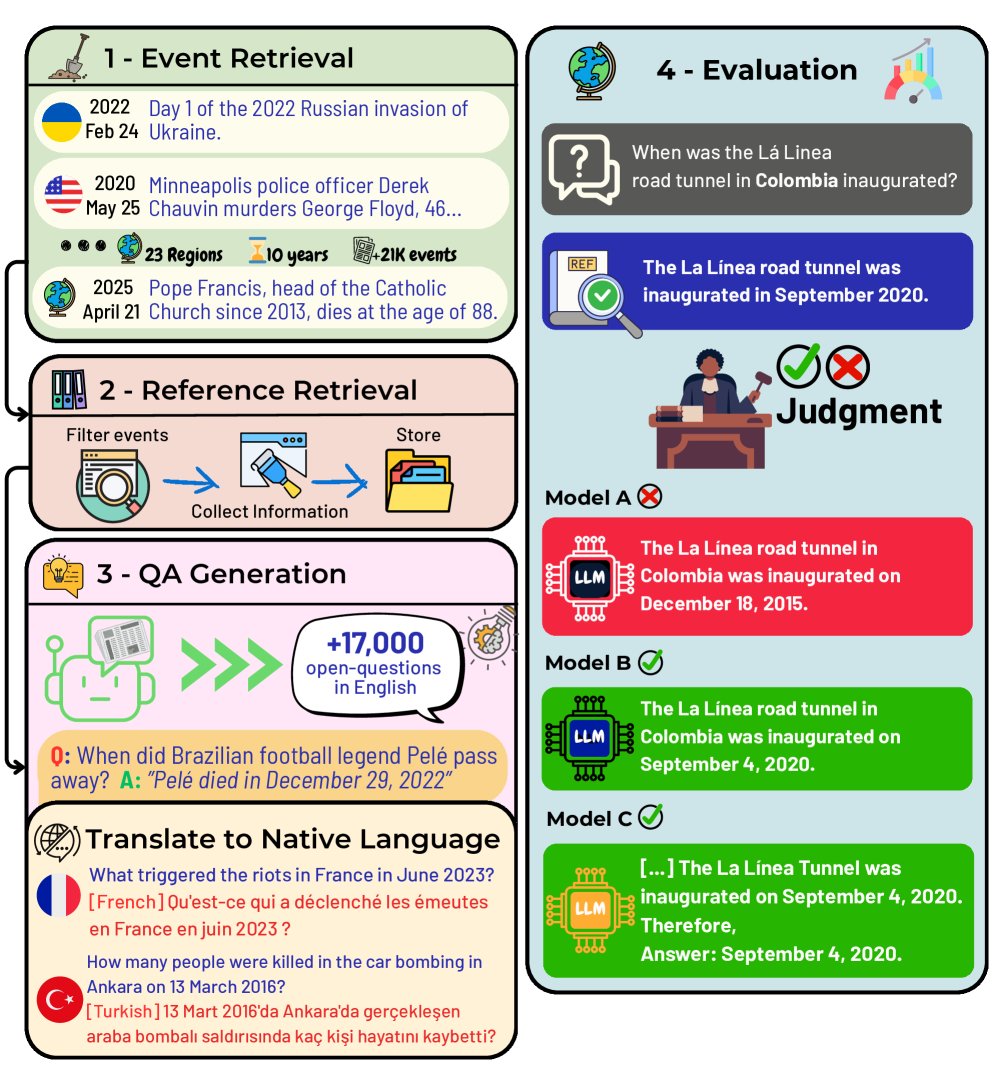
技术框架:TiEBe的构建流程主要包括以下几个阶段:1) 从维基百科中提取结构化的历史事件数据;2) 基于提取的事件数据,构建包含问题和答案的问答对;3) 将问答对按照时间和地域进行分类;4) 将问答对翻译成多种语言,以支持多语言评估。该框架利用维基百科作为知识来源,并结合人工验证,确保数据集的质量和可靠性。
关键创新:TiEBe的关键创新在于其对时间和地域因素的关注,以及对多语言的支持。与现有基准测试相比,TiEBe能够更全面地评估LLM对全球事件的记忆能力,并揭示其在不同时间和地域上的知识偏差。此外,TiEBe的多语言特性使其能够评估LLM在不同语言环境下的表现,从而促进LLM的全球化应用。
关键设计:TiEBe数据集包含超过23,000个问答对,涵盖超过10年的事件、23个地区和13种语言。数据集中的问题主要围绕事件的发生时间、地点、参与者和影响等方面展开。答案则基于维基百科和其他可靠来源的事实信息。为了保证数据集的质量,论文作者对问答对进行了人工验证,并对错误或不准确的信息进行了修正。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在TiEBe上的表现存在显著的地域差异,且与各国的社会经济指标(如HDI)存在超过0.7的皮尔逊相关性。此外,低资源语言的性能明显低于高资源语言,表明LLM在处理不同语言时存在不平衡性。这些发现强调了在LLM训练中需要更加关注全球代表性和语言多样性。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型对全球事件的理解和记忆能力,提升其在信息检索、新闻摘要、智能问答等领域的应用效果。同时,该数据集可用于分析LLM的知识偏差,促进更公平和包容的AI系统开发,并为跨文化交流和全球知识共享提供支持。
📄 摘要(原文)
As the knowledge landscape evolves and large language models (LLMs) become increasingly widespread, there is a growing need to keep these models updated with current events. While existing benchmarks assess general factual recall, few studies explore how LLMs retain knowledge over time or across different regions. To address these gaps, we present the Timely Events Benchmark (TiEBe), a dataset of over 23,000 question-answer pairs centered on notable global and regional events, spanning more than 10 years of events, 23 regions, and 13 languages. TiEBe leverages structured retrospective data from Wikipedia to identify notable events through time. These events are then used to construct a benchmark to evaluate LLMs' understanding of global and regional developments, grounded in factual evidence beyond Wikipedia itself. Our results reveal significant geographic disparities in factual recall, emphasizing the need for more balanced global representation in LLM training. We also observe a Pearson correlation of more than 0.7 between models' performance in TiEBe and various countries' socioeconomic indicators, such as HDI. In addition, we examine the impact of language on factual recall by posing questions in the native language of the region where each event occurred, uncovering substantial performance gaps for low-resource languages.