Boosting Text-To-Image Generation via Multilingual Prompting in Large Multimodal Models
作者: Yongyu Mu, Hengyu Li, Junxin Wang, Xiaoxuan Zhou, Chenglong Wang, Yingfeng Luo, Qiaozhi He, Tong Xiao, Guocheng Chen, Jingbo Zhu
分类: cs.CL
发布日期: 2025-01-13
备注: Accepted to ICASSP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出PMT2I,利用多语言提示增强大型多模态模型中的文本到图像生成能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 多语言提示 大型多模态模型 上下文学习 图像生成质量
📋 核心要点
- 现有文本到图像生成方法在上下文学习中,对输入文本的理解不足,限制了复杂图像描述的生成。
- 论文提出PMT2I方法,通过将输入文本翻译成多种语言,利用多语言提示增强模型对文本的理解。
- 实验表明,PMT2I在多个基准测试中表现优异,尤其在人类偏好对齐和图像多样性方面有显著提升。
📝 摘要(中文)
本文旨在通过构建并行多语言提示,利用大型多模态模型(LMMs)的多语言能力,从而提升文本到图像(T2I)生成效果。现有工作主要集中在丰富上下文学习(ICL)的输入空间,例如提供少量示例和优化图像描述,使其更详细和逻辑化。然而,随着对更复杂和灵活的图像描述的需求增长,增强ICL范式内对输入文本的理解仍然是一个关键但未被充分探索的领域。具体而言,我们将输入文本翻译成多种语言,并向模型提供原始文本和翻译文本。在两个LMM上进行的三个基准测试的实验表明,我们的方法PMT2I在通用、组合和细粒度评估中都取得了优异的性能,尤其是在人类偏好对齐方面。此外,凭借生成更多样化图像的优势,PMT2I在与重排序方法结合使用时,显著优于基线提示。
🔬 方法详解
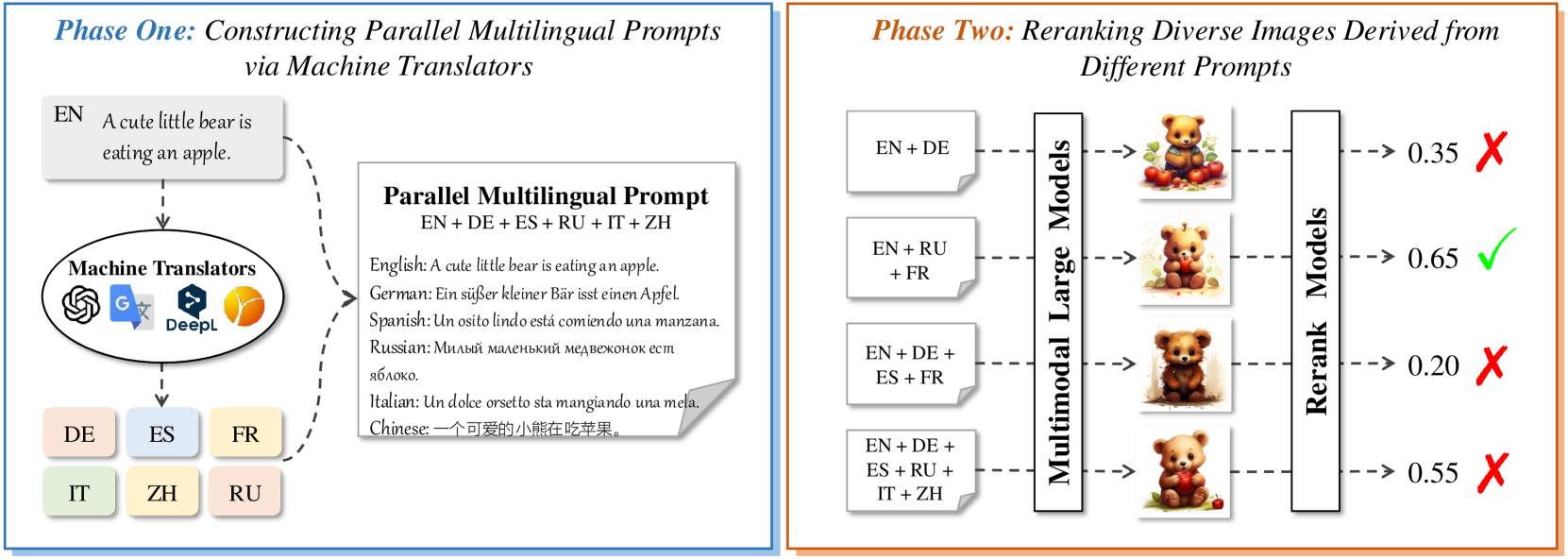
问题定义:现有的大型多模态模型在文本到图像生成任务中,虽然可以通过上下文学习提升性能,但对复杂和细粒度的文本描述的理解仍然不足。现有的方法主要集中在优化图像描述或提供更丰富的示例,而忽略了提升模型对输入文本本身的理解能力。这导致模型难以生成符合用户意图的复杂图像。
核心思路:论文的核心思路是利用大型多模态模型本身具备的多语言能力,通过提供输入文本的多语言翻译版本,来增强模型对原始文本的理解。作者认为,不同语言的翻译可以从不同角度诠释原始文本,从而帮助模型更全面地理解文本的含义,并生成更准确、更符合用户意图的图像。
技术框架:PMT2I方法的技术框架主要包括以下几个步骤:1) 将原始输入文本翻译成多种不同的语言。2) 将原始文本和所有翻译后的文本作为提示输入到大型多模态模型中。3) 模型基于这些多语言提示生成图像。4) (可选)使用重排序方法对生成的图像进行排序,选择最佳图像。
关键创新:该方法最重要的创新点在于利用了大型多模态模型的多语言能力来增强文本理解。与以往专注于优化图像描述或提供更多示例的方法不同,PMT2I直接从提升模型对输入文本的理解入手,从而更有效地提升了文本到图像的生成质量。
关键设计:关键设计包括:1) 选择合适的翻译语言:作者可能需要根据目标图像的特点和模型的语言能力选择合适的翻译语言。2) 提示的组织方式:如何将原始文本和翻译文本组合成有效的提示,可能需要进行实验和调整。3) 重排序方法:如果使用重排序方法,需要选择合适的排序指标和算法,以选择最佳图像。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PMT2I方法在通用、组合和细粒度评估中都取得了优异的性能。尤其是在人类偏好对齐方面,PMT2I显著优于基线方法,表明生成的图像更符合人类的审美和意图。此外,PMT2I还能够生成更多样化的图像,与重排序方法结合使用时,性能提升更加明显。
🎯 应用场景
该研究成果可应用于各种需要高质量文本到图像生成的场景,例如广告设计、艺术创作、游戏开发、虚拟现实等。通过提升生成图像的质量和多样性,可以更好地满足用户的需求,并为相关领域带来创新和发展。未来,该方法可以进一步扩展到其他多模态任务中,例如视频生成、3D模型生成等。
📄 摘要(原文)
Previous work on augmenting large multimodal models (LMMs) for text-to-image (T2I) generation has focused on enriching the input space of in-context learning (ICL). This includes providing a few demonstrations and optimizing image descriptions to be more detailed and logical. However, as demand for more complex and flexible image descriptions grows, enhancing comprehension of input text within the ICL paradigm remains a critical yet underexplored area. In this work, we extend this line of research by constructing parallel multilingual prompts aimed at harnessing the multilingual capabilities of LMMs. More specifically, we translate the input text into several languages and provide the models with both the original text and the translations. Experiments on two LMMs across 3 benchmarks show that our method, PMT2I, achieves superior performance in general, compositional, and fine-grained assessments, especially in human preference alignment. Additionally, with its advantage of generating more diverse images, PMT2I significantly outperforms baseline prompts when incorporated with reranking methods. Our code and parallel multilingual data can be found at https://github.com/takagi97/PMT2I.