Leveraging ASIC AI Chips for Homomorphic Encryption
作者: Jianming Tong, Tianhao Huang, Jingtian Dang, Leo de Castro, Anirudh Itagi, Anupam Golder, Asra Ali, Jeremy Kun, Jevin Jiang, Arvind, G. Edward Suh, Tushar Krishna
分类: cs.CR, cs.AR, cs.CL, cs.PL
发布日期: 2025-01-13 (更新: 2025-12-25)
备注: IEEE International Symposium on High-Performance Computer Architecture (HPCA) 2026; 18 pages, 16 figures, 5 algorithms, 10 tables. Leveraging Google TPUs for Homomorphic Encryption
🔗 代码/项目: GITHUB
💡 一句话要点
提出CROSS框架,利用AI芯片加速同态加密,实现ASIC级别的能效。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 同态加密 AI加速器 TPU 编译器优化 基对齐变换 内存对齐变换 低精度计算 数据隐私
📋 核心要点
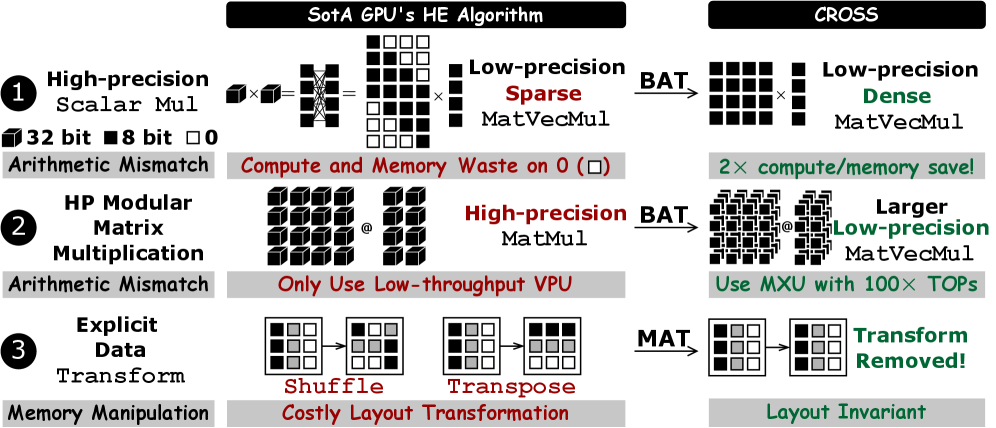
- 现有GPU加速的同态加密算法在高精度计算和细粒度数据置换方面存在瓶颈,无法有效利用AI芯片(如TPU)的低精度矩阵引擎和粗粒度内存架构。
- CROSS框架通过基对齐变换(BAT)将高精度模算术转换为低精度矩阵乘法,充分利用TPU的矩阵引擎,并通过内存对齐变换(MAT)消除运行时数据重排序。
- 实验结果表明,CROSS在TPU v6e上实现了比现有方案更高的每瓦吞吐量,证明了AI芯片在同态加密加速方面的潜力。
📝 摘要(中文)
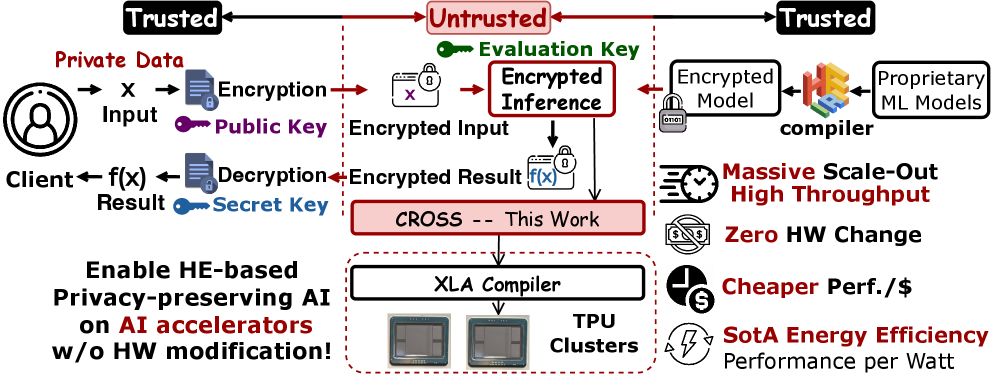
同态加密(HE)为云服务提供强大的数据隐私保护,但计算开销巨大。虽然GPU已成为加速HE的实用平台,但与专用HE ASIC相比,能效仍存在一个数量级的差距。本文探索了一种替代方案:利用现有的AI加速器,如谷歌的TPU,其具有粗粒度的计算和内存架构,为实现ASIC级别的HE能效提供了一条途径。然而,这种架构范式与为GPU设计的SoTA HE算法存在根本不匹配。这些算法严重依赖于:(1)高精度(32位)整数算术,现在只能在TPU的低吞吐量向量单元上运行,而其高吞吐量低精度(8位)矩阵引擎(MXU)处于空闲状态;(2)细粒度的数据置换,在TPU的粗粒度内存子系统上效率低下。因此,将GPU优化的HE库移植到TPU会导致严重的资源利用不足和性能下降。为了解决上述挑战,我们引入了CROSS,一个系统地转换HE工作负载以适应TPU架构的编译器框架。CROSS做出了两个关键贡献:(1)基对齐变换(BAT),一种将高精度模算术转换为密集、低精度(INT8)矩阵乘法的新技术,解锁并提高了TPU的MXU在HE中的利用率;(2)内存对齐变换(MAT),通过将重排序嵌入到计算内核中,消除了代价高昂的运行时数据重排序。CROSS (TPU v6e)在NTT和HE算子上实现了比WarpDrive、FIDESlib、FAB、HEAP和Cheddar更高的每瓦吞吐量,确立了AI ASIC作为HE算子的SotA高效平台。代码:https://github.com/EfficientPPML/CROSS
🔬 方法详解
问题定义:论文旨在解决同态加密算法在AI加速器(如TPU)上效率低下的问题。现有为GPU设计的HE算法依赖于高精度整数运算和细粒度数据置换,这与TPU的低精度矩阵运算单元(MXU)和粗粒度内存架构不匹配,导致资源利用率低和性能下降。
核心思路:论文的核心思路是将HE工作负载转换为更适合TPU架构的形式。具体来说,通过将高精度模算术转换为低精度矩阵乘法,充分利用TPU的MXU,并通过优化内存访问模式,减少数据重排的开销。这样可以提高TPU的利用率,从而提高HE的整体性能。
技术框架:CROSS是一个编译器框架,包含两个主要模块:基对齐变换(BAT)和内存对齐变换(MAT)。BAT负责将高精度模算术转换为低精度矩阵乘法,MAT负责优化内存访问模式,消除运行时数据重排。整个流程包括:输入HE工作负载 -> BAT变换 -> MAT变换 -> 生成TPU可执行代码 -> 在TPU上执行。
关键创新:论文的关键创新在于BAT和MAT两种变换。BAT通过将高精度模算术转换为低精度矩阵乘法,使得HE算法能够充分利用TPU的MXU,从而提高计算效率。MAT通过将数据重排操作嵌入到计算内核中,避免了昂贵的运行时数据重排,从而提高内存访问效率。
关键设计:BAT的关键设计在于选择合适的基,使得高精度模算术可以有效地转换为低精度矩阵乘法。MAT的关键设计在于分析数据依赖关系,将数据重排操作与计算操作融合,从而避免运行时数据重排的开销。具体的参数设置和网络结构取决于具体的HE算法和TPU架构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CROSS在TPU v6e上实现了比WarpDrive、FIDESlib、FAB、HEAP和Cheddar更高的每瓦吞吐量。具体来说,CROSS在NTT和HE算子上实现了显著的性能提升,证明了AI ASIC作为HE算子的高效平台。
🎯 应用场景
该研究成果可应用于云计算、联邦学习、安全多方计算等领域,在保护用户数据隐私的前提下,实现高效的同态加密计算。例如,云服务提供商可以使用该技术在不解密用户数据的情况下进行数据分析和处理,从而保护用户数据的隐私。联邦学习可以使用该技术在多个参与方之间安全地共享模型参数,而无需暴露本地数据。
📄 摘要(原文)
Homomorphic Encryption (HE) provides strong data privacy for cloud services but at the cost of prohibitive computational overhead. While GPUs have emerged as a practical platform for accelerating HE, there remains an order-of-magnitude energy-efficiency gap compared to specialized (but expensive) HE ASICs. This paper explores an alternate direction: leveraging existing AI accelerators, like Google's TPUs with coarse-grained compute and memory architectures, to offer a path toward ASIC-level energy efficiency for HE. However, this architectural paradigm creates a fundamental mismatch with SoTA HE algorithms designed for GPUs. These algorithms rely heavily on: (1) high-precision (32-bit) integer arithmetic to now run on a TPU's low-throughput vector unit, leaving its high-throughput low-precision (8-bit) matrix engine (MXU) idle, and (2) fine-grained data permutations that are inefficient on the TPU's coarse-grained memory subsystem. Consequently, porting GPU-optimized HE libraries to TPUs results in severe resource under-utilization and performance degradation. To tackle above challenges, we introduce CROSS, a compiler framework that systematically transforms HE workloads to align with the TPU's architecture. CROSS makes two key contributions: (1) Basis-Aligned Transformation (BAT), a novel technique that converts high-precision modular arithmetic into dense, low-precision (INT8) matrix multiplications, unlocking and improving the utilization of TPU's MXU for HE, and (2) Memory-Aligned Transformation (MAT), which eliminates costly runtime data reordering by embedding reordering into compute kernels through offline parameter transformation. CROSS (TPU v6e) achieves higher throughput per watt on NTT and HE operators than WarpDrive, FIDESlib, FAB, HEAP, and Cheddar, establishing AI ASIC as the SotA efficient platform for HE operators. Code: https://github.com/EfficientPPML/CROSS