Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages
作者: Jannik Brinkmann, Chris Wendler, Christian Bartelt, Aaron Mueller
分类: cs.CL
发布日期: 2025-01-10 (更新: 2025-05-23)
💡 一句话要点
大型语言模型在不同语系语言间共享潜在语法概念的表征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多语言学习 跨语言表征 稀疏自编码器 因果干预
📋 核心要点
- 人类双语者通常使用相似的大脑区域来处理多种语言,这取决于他们学习第二语言的时间和熟练程度,而LLM中多语言学习和编码方式尚不明确。
- 该研究的核心思想是探索LLM是否在不同语言间共享形态句法概念的表征,并利用稀疏自编码器和因果干预来验证。
- 实验结果表明,LLM能够学习到跨语言的抽象语法概念,并且可以通过干预特定特征来修改模型在机器翻译任务中的行为。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)如何在多种语言中学习和编码信息,探讨了LLMs在不同语言间共享形态句法概念(如语法数、性别和时态)表征的程度。作者在Llama-3-8B和Aya-23-8B上训练了稀疏自编码器,证明了抽象的语法概念通常被编码在跨多种语言共享的特征方向上。通过因果干预验证了这些表征的多语言性质;具体来说,仅消融多语言特征就会导致跨语言的分类器性能下降到接近随机水平。然后,作者使用这些特征来精确修改机器翻译任务中的模型行为,这证明了这些特征在网络中的作用具有通用性和选择性。研究结果表明,即使主要在英语数据上训练的模型也可以开发出形态句法概念的鲁棒的跨语言抽象。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)是否以及如何在不同语系的语言之间共享对抽象语法概念(如数、性别、时态)的表征。现有方法缺乏对LLM内部多语言表征机制的深入理解,难以解释模型如何处理和泛化不同语言的语法结构。
核心思路:核心思路是利用稀疏自编码器从LLM中提取潜在的语法特征,并分析这些特征在不同语言之间的共享程度。通过因果干预(特征消融)验证这些共享特征对模型性能的影响,并通过修改这些特征来控制模型的行为,从而揭示其在多语言处理中的作用。
技术框架:整体框架包括以下几个主要步骤:1) 在Llama-3-8B和Aya-23-8B等LLM上训练稀疏自编码器,以提取潜在的语法特征。2) 分析这些特征在不同语言之间的激活模式,确定共享的特征方向。3) 通过因果干预(消融)评估这些共享特征对模型在不同语言上的分类任务性能的影响。4) 利用这些特征来修改模型在机器翻译任务中的行为,验证其通用性和选择性。
关键创新:最重要的技术创新点在于发现并验证了LLM在不同语系语言之间共享的抽象语法概念表征。与以往研究主要关注词嵌入或句子嵌入的跨语言对齐不同,该研究深入到模型内部,揭示了更抽象的语法知识的共享。
关键设计:关键设计包括:1) 使用稀疏自编码器提取特征,保证特征的稀疏性和可解释性。2) 设计因果干预实验,通过消融特定特征来评估其对模型性能的因果影响。3) 在机器翻译任务中,通过修改提取的特征来控制模型的行为,验证特征的有效性和可控性。具体参数设置和损失函数等细节未在摘要中明确说明,属于未知信息。
🖼️ 关键图片

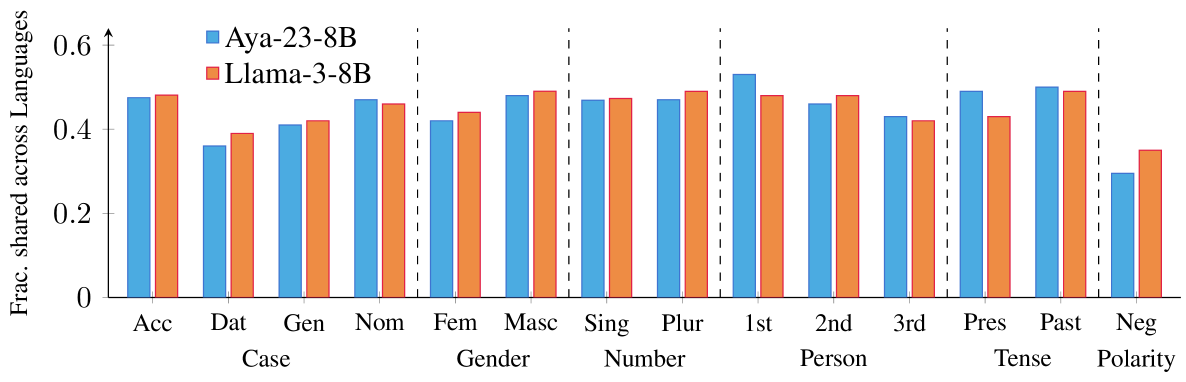
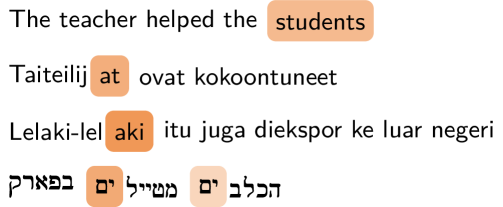
📊 实验亮点
实验结果表明,通过消融多语言共享的特征,可以显著降低模型在多种语言上的分类性能,使其接近随机水平。此外,通过精确修改这些特征,可以控制模型在机器翻译任务中的行为,证明了这些特征在网络中的重要性和可操作性。具体的性能提升幅度未在摘要中明确说明,属于未知信息。
🎯 应用场景
该研究成果可应用于提升多语言自然语言处理系统的性能,例如机器翻译、跨语言信息检索等。通过理解LLM内部的跨语言表征机制,可以设计更有效的多语言学习算法,并提高模型在低资源语言上的泛化能力。此外,该研究也有助于开发更可控、更安全的LLM,避免模型产生不符合预期的行为。
📄 摘要(原文)
Human bilinguals often use similar brain regions to process multiple languages, depending on when they learned their second language and their proficiency. In large language models (LLMs), how are multiple languages learned and encoded? In this work, we explore the extent to which LLMs share representations of morphsyntactic concepts such as grammatical number, gender, and tense across languages. We train sparse autoencoders on Llama-3-8B and Aya-23-8B, and demonstrate that abstract grammatical concepts are often encoded in feature directions shared across many languages. We use causal interventions to verify the multilingual nature of these representations; specifically, we show that ablating only multilingual features decreases classifier performance to near-chance across languages. We then use these features to precisely modify model behavior in a machine translation task; this demonstrates both the generality and selectivity of these feature's roles in the network. Our findings suggest that even models trained predominantly on English data can develop robust, cross-lingual abstractions of morphosyntactic concepts.