Navigating Tomorrow: Reliably Assessing Large Language Models Performance on Future Event Prediction
作者: Petraq Nako, Adam Jatowt
分类: cs.CL, cs.IR
发布日期: 2025-01-10
💡 一句话要点
评估大语言模型在未来事件预测中的可靠性,揭示其潜力和局限
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 未来事件预测 预测建模 新闻文章分析 反事实分析
📋 核心要点
- 现有预测方法在处理复杂、非结构化信息时存在不足,难以有效预测未来事件。
- 本文利用大型语言模型(LLM)的强大能力,探索其在未来事件预测任务中的潜力。
- 通过构建数据集并进行多场景评估,揭示了LLM在预测建模中的优势与不足。
📝 摘要(中文)
预测未来事件在多个领域具有重要应用。本文评估了几种大型语言模型(LLM)在支持未来预测任务方面的性能,这是一个尚未充分探索的领域。我们通过三种场景评估模型:肯定式与可能性提问、推理和反事实分析。为此,我们创建了一个数据集,通过查找和分类基于实体类型及其受欢迎程度的新闻文章。我们收集了LLM训练截止日期之前和之后的新闻文章,以便彻底测试和比较模型性能。我们的研究强调了LLM在预测建模中的潜力和局限性,为未来的改进奠定了基础。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在预测未来事件方面的能力。现有方法,如预测分析、时间序列预测和模拟,在处理复杂和非结构化的信息时存在局限性,难以有效利用海量文本数据进行未来事件的预测。因此,如何利用LLM的强大语言理解和生成能力,可靠地预测未来事件,是一个重要的研究问题。
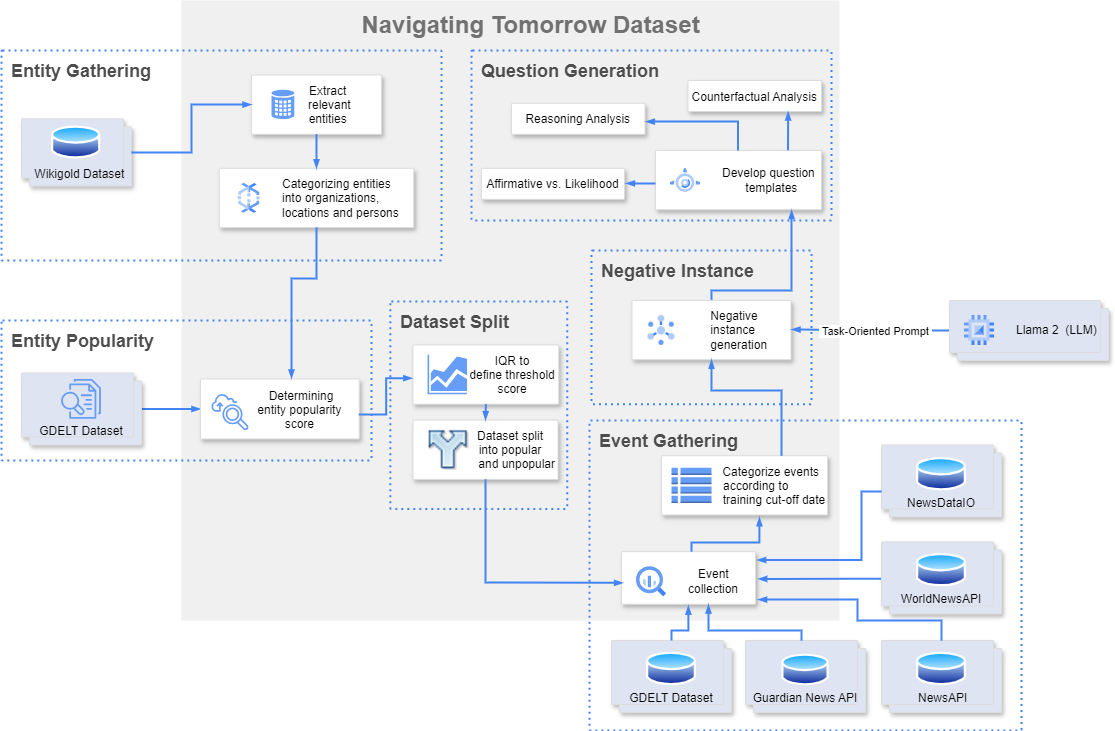
核心思路:论文的核心思路是利用LLM对新闻文章进行分析,提取与未来事件相关的信息,并评估LLM在不同场景下的预测能力。通过构建包含训练截止日期前后新闻文章的数据集,可以测试LLM是否能够泛化到未见过的数据,并评估其预测的准确性和可靠性。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集与构建:收集新闻文章,并根据实体类型和受欢迎程度进行分类,构建包含训练截止日期前后新闻文章的数据集。2) 场景设计:设计三种评估场景,包括肯定式与可能性提问、推理和反事实分析,以全面评估LLM的预测能力。3) 模型评估:使用不同的LLM,在构建的数据集和设计的场景下进行实验,评估其预测的准确性和可靠性。4) 结果分析:分析实验结果,总结LLM在未来事件预测方面的潜力和局限性。
关键创新:论文的关键创新在于:1) 提出了利用LLM进行未来事件预测的新思路,探索了LLM在这一领域的潜力。2) 构建了一个包含训练截止日期前后新闻文章的数据集,为评估LLM的泛化能力提供了基础。3) 设计了多种评估场景,全面评估了LLM在不同情况下的预测能力。
关键设计:论文的关键设计包括:1) 数据集的构建方式,确保包含足够的信息量和多样性,以支持LLM的训练和评估。2) 评估场景的设计,涵盖了不同的预测类型和难度,以全面评估LLM的预测能力。3) 评估指标的选择,能够准确反映LLM的预测准确性和可靠性。具体参数设置、损失函数和网络结构等细节未知。
🖼️ 关键图片

📊 实验亮点
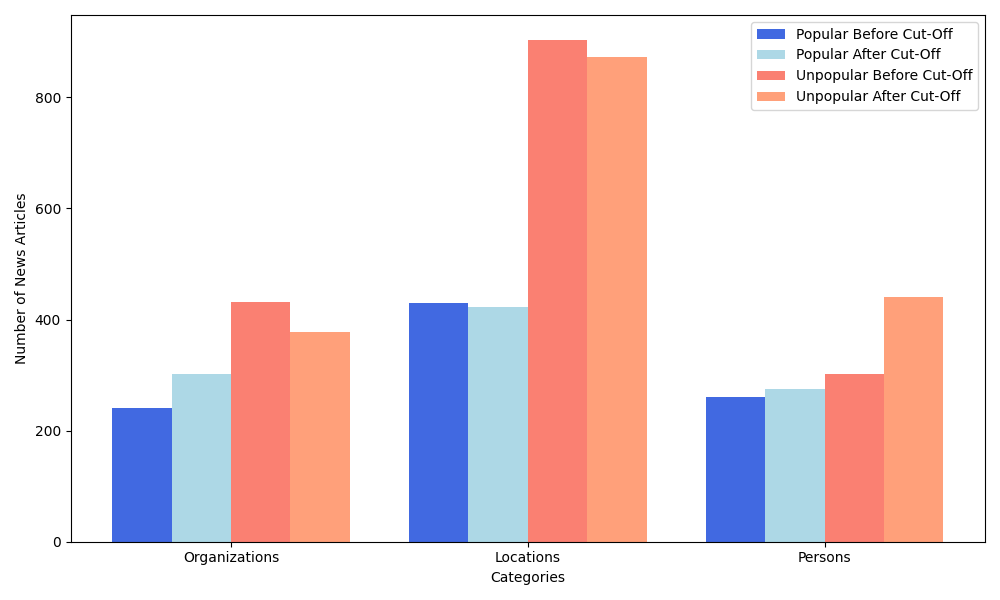
该研究通过构建包含训练截止日期前后新闻文章的数据集,并设计了肯定式与可能性提问、推理和反事实分析三种场景,全面评估了LLM在未来事件预测方面的性能。实验结果揭示了LLM在预测建模中的潜力和局限性,为未来的改进奠定了基础。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于金融市场预测、自然灾害预警、商业趋势分析和政治事件预测等领域。通过利用LLM预测未来事件,可以帮助决策者提前采取预防措施,抓住新的机遇,从而降低风险,提高效率。未来的研究可以进一步探索LLM在更复杂和动态环境下的预测能力,并开发更有效的预测模型。
📄 摘要(原文)
Predicting future events is an important activity with applications across multiple fields and domains. For example, the capacity to foresee stock market trends, natural disasters, business developments, or political events can facilitate early preventive measures and uncover new opportunities. Multiple diverse computational methods for attempting future predictions, including predictive analysis, time series forecasting, and simulations have been proposed. This study evaluates the performance of several large language models (LLMs) in supporting future prediction tasks, an under-explored domain. We assess the models across three scenarios: Affirmative vs. Likelihood questioning, Reasoning, and Counterfactual analysis. For this, we create a dataset1 by finding and categorizing news articles based on entity type and its popularity. We gather news articles before and after the LLMs training cutoff date in order to thoroughly test and compare model performance. Our research highlights LLMs potential and limitations in predictive modeling, providing a foundation for future improvements.