Migician: Revealing the Magic of Free-Form Multi-Image Grounding in Multimodal Large Language Models
作者: You Li, Heyu Huang, Chi Chen, Kaiyu Huang, Chao Huang, Zonghao Guo, Zhiyuan Liu, Jinan Xu, Yuhua Li, Ruixuan Li, Maosong Sun
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-01-10 (更新: 2025-02-18)
备注: 21 pages, 8 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Migician,实现多模态大语言模型中自由形式的多图像精准定位。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 多图定位 自由形式定位 端到端学习 视觉 grounding
📋 核心要点
- 现有多模态大语言模型在复杂多图场景下,难以实现精准的自由形式定位,缺乏端到端训练。
- Migician模型通过端到端训练,实现了跨多图的自由形式精准定位,提升了模型对抽象视觉信息的捕捉能力。
- 实验表明,Migician在多图定位能力上显著优于现有模型,性能提升24.94%,甚至超越了70B参数规模的模型。
📝 摘要(中文)
多模态大语言模型(MLLM)的最新进展显著提高了其对单张图像的细粒度感知和对多张图像的通用理解。然而,现有的MLLM在复杂的多图像场景中实现精确的定位仍然面临挑战。为了解决这个问题,我们首先探索了一个思维链(CoT)框架,该框架集成了单图像定位和多图像理解。虽然部分有效,但由于其非端到端的性质,它仍然不稳定,难以捕捉抽象的视觉信息。因此,我们推出了Migician,这是第一个能够跨多个图像执行自由形式和精确的定位的多图像定位模型。为了支持这一点,我们提出了MGrounding-630k数据集,该数据集包含来自现有数据集的多个多图像定位任务的数据,以及新生成的自由形式定位指令跟随数据。此外,我们提出了MIG-Bench,这是一个专门为评估多图像定位能力而设计的综合基准。实验结果表明,我们的模型实现了显著优越的多图像定位能力,优于现有的最佳MLLM 24.94%,甚至超过了更大的70B模型。我们的代码、模型、数据集和基准已在https://migician-vg.github.io/完全开源。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型在多图场景下,难以进行自由形式的精准定位的问题。现有方法,如基于思维链(CoT)的方法,虽然能部分解决问题,但由于其非端到端的特性,存在训练不稳定、难以捕捉抽象视觉信息等痛点。
核心思路:论文的核心思路是设计一个端到端的多图定位模型Migician,使其能够直接学习从多图输入到自由形式定位的映射关系。通过端到端训练,模型能够更好地整合视觉信息和语言信息,从而提升定位的准确性和鲁棒性。
技术框架:Migician的技术框架主要包括以下几个部分:1) 多图输入编码:使用视觉编码器(如CLIP)提取多张图像的视觉特征。2) 特征融合:设计特征融合模块,将多张图像的视觉特征进行有效融合,捕捉图像之间的关系。3) 指令跟随:利用语言模型(如LLaMA)根据用户指令,在融合后的视觉特征上进行定位推理。4) 定位输出:生成最终的定位结果,可以是图像区域的坐标或者其他形式的描述。
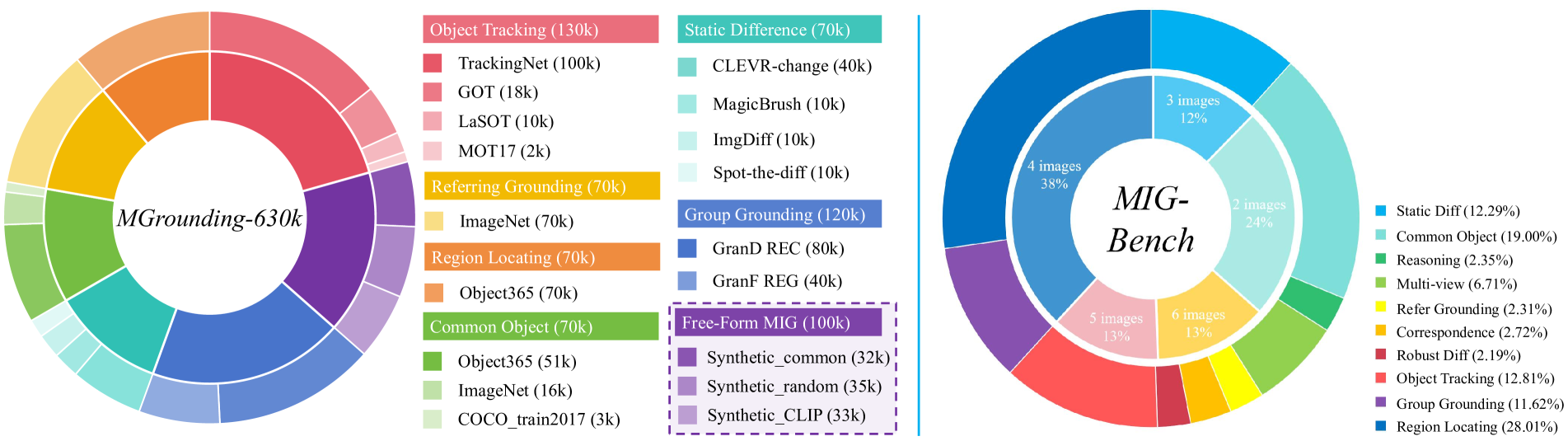
关键创新:论文最重要的技术创新点在于提出了一个端到端的多图自由形式定位模型Migician,并构建了大规模的多图定位数据集MGrounding-630k和评估基准MIG-Bench。与现有方法相比,Migician能够直接学习多图输入到定位输出的映射,避免了中间步骤带来的误差累积,从而提升了定位的准确性。
关键设计:论文的关键设计包括:1) MGrounding-630k数据集:包含多种多图定位任务和自由形式定位指令,为模型的训练提供了丰富的数据。2) 特征融合模块:设计了有效的特征融合模块,用于捕捉图像之间的关系。3) 损失函数:采用了合适的损失函数,用于优化模型的定位性能。具体参数设置和网络结构细节在论文中有详细描述,此处不再赘述。
🖼️ 关键图片


📊 实验亮点
Migician在MIG-Bench基准测试中,显著优于现有最佳的多模态大语言模型,性能提升高达24.94%,甚至超越了参数量更大的70B模型。这表明Migician在多图自由形式定位任务上具有显著的优势。
🎯 应用场景
该研究成果可应用于智能图像编辑、视觉问答、机器人导航等领域。例如,在智能图像编辑中,用户可以通过自然语言指令,对多张图像中的特定对象进行编辑。在机器人导航中,机器人可以根据多张摄像头拍摄的图像,定位目标物体的位置,从而实现自主导航。
📄 摘要(原文)
The recent advancement of Multimodal Large Language Models (MLLMs) has significantly improved their fine-grained perception of single images and general comprehension across multiple images. However, existing MLLMs still face challenges in achieving precise grounding in complex multi-image scenarios. To address this, we first explore a Chain-of-Thought (CoT) framework that integrates single-image grounding with multi-image comprehension. While partially effective, it remains unstable and struggles to capture abstract visual information due to its non-end-to-end nature. Therefore, we introduce Migician, the first multi-image grounding model capable of performing free-form and accurate grounding across multiple images. To support this, we present the MGrounding-630k dataset, which comprises data for several multi-image grounding tasks derived from existing datasets, along with newly generated free-form grounding instruction-following data. Furthermore, we propose MIG-Bench, a comprehensive benchmark specifically designed for evaluating multi-image grounding capabilities. Experimental results demonstrate that our model achieves significantly superior multi-image grounding capabilities, outperforming the best existing MLLMs by 24.94% and even surpassing much larger 70B models. Our code, model, dataset, and benchmark are fully open-sourced at https://migician-vg.github.io/.