Self-Evolving Critique Abilities in Large Language Models
作者: Zhengyang Tang, Ziniu Li, Zhenyang Xiao, Tian Ding, Ruoyu Sun, Benyou Wang, Dayiheng Liu, Fei Huang, Tianyu Liu, Bowen Yu, Junyang Lin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-10 (更新: 2025-08-04)
备注: Accepted by COLM 2025
💡 一句话要点
提出SCRIT框架,利用自生成数据提升大语言模型的自进化评判能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自进化学习 评判能力 对比学习 自监督学习 数据质量 数学推理 科学推理
📋 核心要点
- 现有LLM评判能力提升依赖人工标注或更强模型,缺乏无外部监督的自进化方案。
- SCRIT框架通过自生成数据训练LLM,利用对比评判和自验证提升数据质量。
- 实验表明,SCRIT在数学和科学推理任务上显著提升了评判和纠错能力。
📝 摘要(中文)
大型语言模型(LLMs)面临一个关键挑战:在人类难以评估或LLMs可能优于人类的任务中提供反馈。在这些情况下,利用LLMs自身的评判能力——识别和纠正缺陷——显示出巨大的潜力。本文探讨了增强LLMs的评判能力,注意到当前的方法依赖于人工标注或更强大的模型,使得在没有外部监督的情况下提高评判能力这一挑战仍未解决。我们引入了SCRIT(自进化CRITic),一个使用自生成数据训练LLMs以进化其评判能力的框架。为了解决原始生成数据的低质量问题,我们提出了一种对比评判方法,该方法在数据合成期间使用参考解决方案来增强模型对关键概念的理解,并结合了一种自验证方案来确保数据质量。最终训练的模型在推理时不依赖任何参考解决方案。SCRIT使用领先的LLM Qwen2.5-72B-Instruct实现,在涵盖数学和科学推理的广泛基准测试中表现出持续的改进:在评判-纠正准确率方面实现了10.0%的相对增益,在错误识别F1分数方面实现了19.0%的相对改进。我们的分析表明,SCRIT的性能随着数据和模型规模的增加而呈正相关,并且可以通过多轮迭代实现持续改进。
🔬 方法详解
问题定义:现有的大语言模型在需要自我评估和改进的场景中,缺乏有效的评判能力。尤其是在人类难以提供有效反馈,或者模型本身能力超越人类的情况下,如何让模型自我发现错误并进行修正是一个难题。现有的方法依赖于人工标注数据或更强大的模型进行监督学习,成本高昂且泛化性有限,无法实现真正的自进化。
核心思路:SCRIT的核心思路是利用大语言模型自身生成数据,并在此基础上进行训练,从而提升其评判能力。为了解决直接生成数据质量不高的问题,引入对比评判机制,通过参考解决方案来引导模型学习关键概念,并采用自验证方案来过滤低质量数据。最终目标是训练出一个无需外部参考即可独立进行评判和纠错的模型。
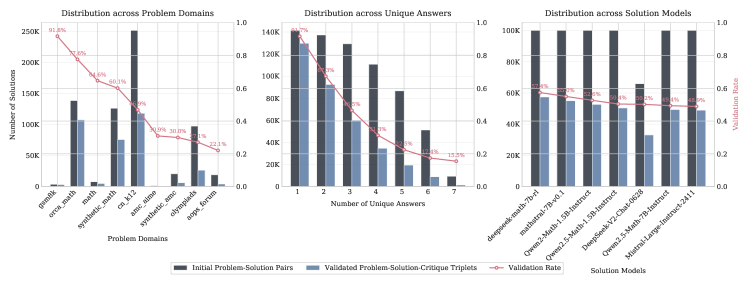
技术框架:SCRIT框架主要包含以下几个阶段:1) 数据生成阶段:利用LLM生成问题和对应的解决方案;2) 对比评判阶段:引入参考解决方案,让LLM对比生成方案和参考方案,识别生成方案中的错误;3) 自验证阶段:利用LLM评估生成数据的质量,过滤掉低质量数据;4) 模型训练阶段:使用高质量的自生成数据训练LLM,提升其评判和纠错能力。在推理阶段,训练好的模型可以直接对新的问题和解决方案进行评判,无需参考解决方案。
关键创新:SCRIT最重要的创新点在于其完全依赖自生成数据进行训练,摆脱了对人工标注数据或更强大模型的依赖,实现了LLM评判能力的自进化。对比评判和自验证机制是保证自生成数据质量的关键,使得模型能够有效地学习到评判和纠错的知识。
关键设计:对比评判机制的关键在于如何有效地利用参考解决方案。论文中可能采用了特定的prompting策略,引导LLM对比生成方案和参考方案,并明确指出生成方案中的错误。自验证阶段可能使用了基于LLM的打分机制,对生成数据的质量进行评估,并设定阈值来过滤低质量数据。具体的损失函数和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
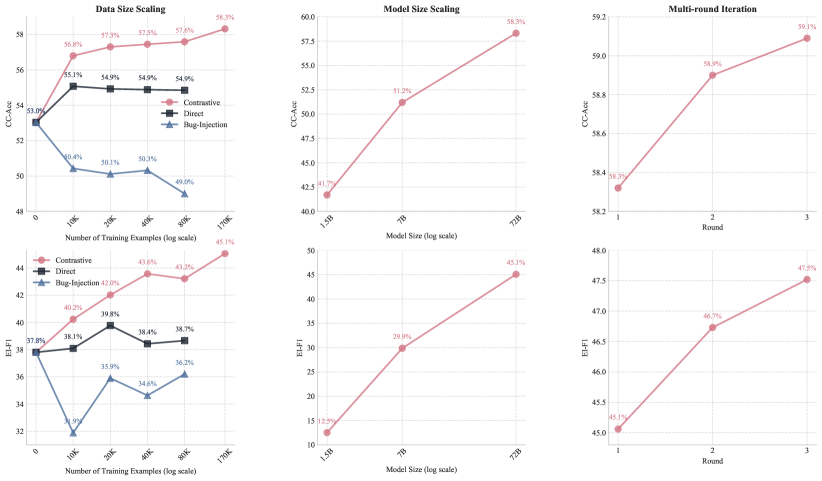
SCRIT在数学和科学推理任务上取得了显著的性能提升。使用Qwen2.5-72B-Instruct模型,SCRIT在评判-纠正准确率方面实现了10.0%的相对增益,在错误识别F1分数方面实现了19.0%的相对改进。实验结果表明,SCRIT的性能随着数据和模型规模的增加而呈正相关,并且可以通过多轮迭代实现持续改进。
🎯 应用场景
SCRIT框架可应用于各种需要LLM自我评估和改进的场景,例如自动代码生成、科学研究、教育辅导等。通过提升LLM的评判能力,可以减少人工干预,提高LLM的自主性和可靠性,加速AI在各个领域的应用。
📄 摘要(原文)
Despite their remarkable performance, Large Language Models (LLMs) face a critical challenge: providing feedback for tasks where human evaluation is difficult or where LLMs potentially outperform humans. In such scenarios, leveraging the critique ability of LLMs themselves - identifying and correcting flaws - shows considerable promise. This paper explores enhancing critique abilities of LLMs, noting that current approaches rely on human annotations or more powerful models, leaving the challenge of improving critique abilities without external supervision unresolved. We introduce SCRIT (Self-evolving CRITic), a framework that trains LLMs with self-generated data to evolve their critique abilities. To address the low quality of naively generated data, we propose a contrastive-critic approach that uses reference solutions during data synthesis to enhance the model's understanding of key concepts, and incorporates a self-validation scheme to ensure data quality. The final trained model operates without any reference solutions at inference time. Implemented with Qwen2.5-72B-Instruct, a leading LLM, SCRIT demonstrates consistent improvements across a wide range of benchmarks spanning both mathematical and scientific reasoning: achieving a 10.0\% relative gain in critique-correction accuracy and a 19.0\% relative improvement in error identification F1-score. Our analysis reveals that SCRIT's performance scales positively with data and model size and enables continuous improvement through multi-round iterations.