Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
作者: Vighnesh Subramaniam, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba, Shuang Li, Igor Mordatch
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-10 (更新: 2025-03-03)
备注: ICLR 2025; 22 pages, 13 figures, 7 tables; Project page at https://llm-multiagent-ft.github.io/
💡 一句话要点
提出多智能体微调方法,通过多样化推理链实现LLM的自主改进。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体学习 语言模型微调 自主改进 多样化推理 强化学习
📋 核心要点
- 现有LLM的自主改进方法受限于训练数据,且连续改进易出现收益递减。
- 论文提出多智能体微调,通过智能体间的交互数据独立微调,实现模型专业化和多样化。
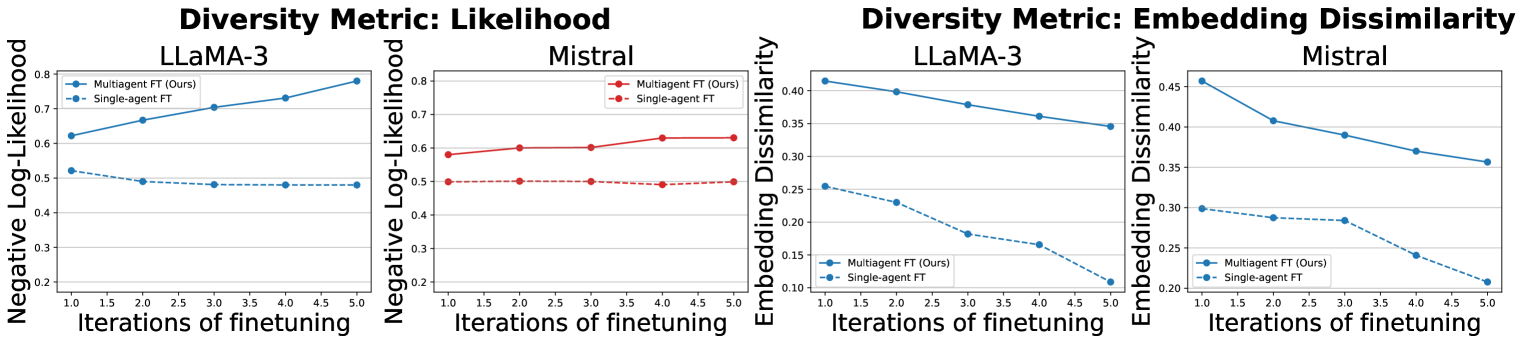
- 实验表明,该方法能保留多样推理链,并在多轮微调中实现超越单智能体方法的性能提升。
📝 摘要(中文)
大型语言模型(LLMs)近年来取得了显著的性能,但受到底层训练数据的根本限制。为了使模型超越训练数据,最近的研究探索了如何使用LLM生成合成数据以进行自主改进。然而,连续的自我改进步骤可能会达到收益递减的程度。本文提出了一种互补的自我改进方法,将微调应用于语言模型的多智能体社会。一组语言模型,全部从相同的基本模型开始,通过使用模型之间多智能体交互生成的数据独立地进行专门化更新。通过在独立的数据集上训练每个模型,我们展示了这种方法如何实现模型之间的专业化和模型集的多样化。因此,我们的整体系统能够保留多样化的推理链,并且比单智能体自我改进方法自主地改进更多轮次的微调。我们在广泛的推理任务中定量地说明了该方法的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在自主改进过程中,由于训练数据限制和连续微调导致的收益递减问题。现有的单智能体自我改进方法容易陷入局部最优,难以探索更广阔的解空间,从而限制了模型的泛化能力和推理能力。
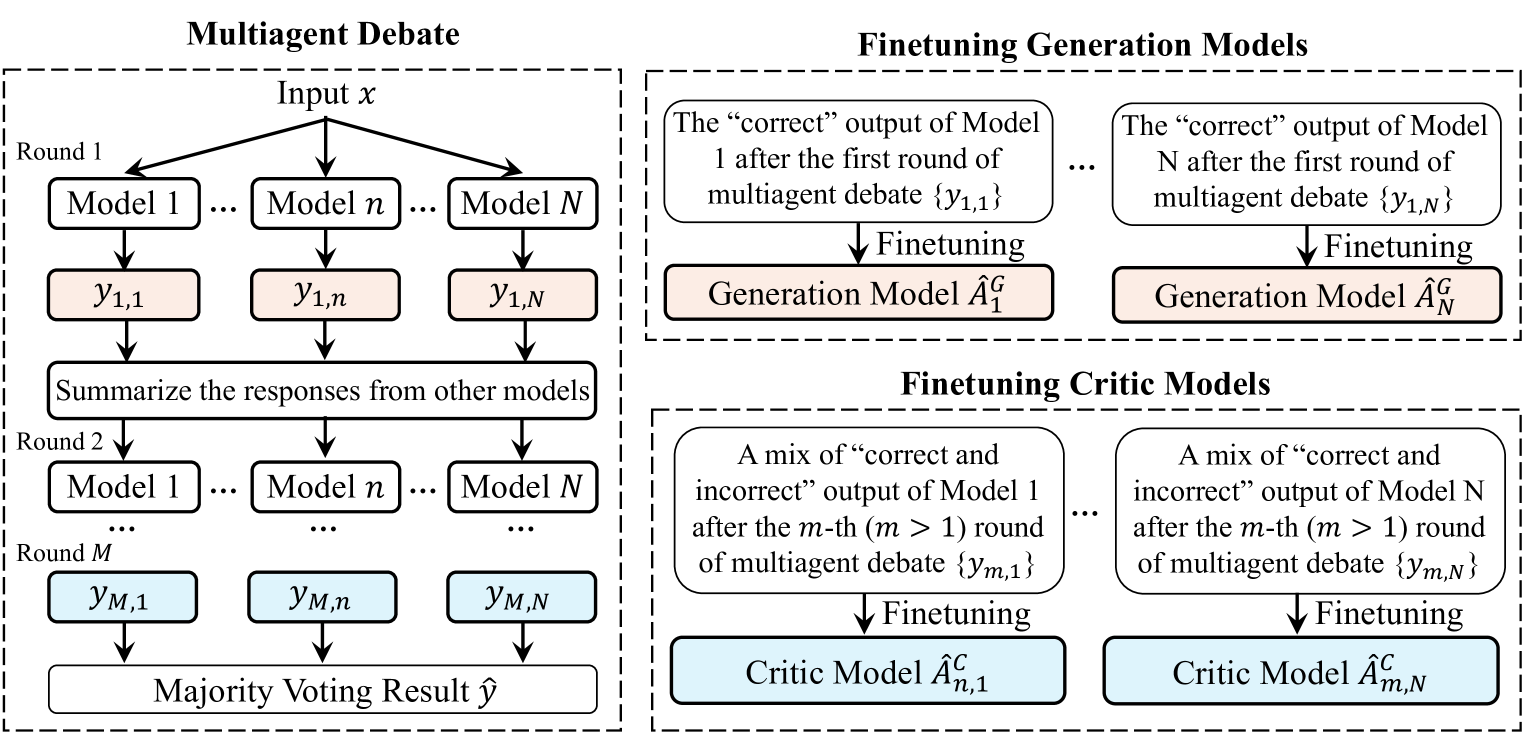
核心思路:论文的核心思路是引入多智能体系统,通过多个LLM智能体之间的交互和独立微调,鼓励模型专业化和多样化。每个智能体基于相同的初始模型,但通过不同的交互数据进行训练,从而形成不同的推理链和知识表示。这种多样性有助于模型跳出局部最优,探索更有效的改进方向。
技术框架:整体框架包含以下几个主要阶段:1) 初始化:多个LLM智能体从相同的预训练模型开始。2) 交互:智能体之间进行交互,例如通过互相提问、互相评估等方式生成数据。3) 微调:每个智能体使用其独立生成的交互数据进行微调,从而实现专业化。4) 集成:将多个微调后的智能体进行集成,例如通过投票或加权平均等方式,以获得最终的改进模型。
关键创新:最重要的技术创新点在于利用多智能体系统来促进LLM的自主改进。与传统的单智能体方法相比,多智能体方法能够更好地探索解空间,保留多样化的推理链,并避免陷入局部最优。这种方法能够有效地提高模型的泛化能力和推理能力。
关键设计:论文的关键设计包括:1) 智能体之间的交互方式,例如使用不同的prompt策略或奖励机制来鼓励多样性。2) 微调数据的生成方式,例如使用不同的采样策略或数据增强方法来提高数据的质量和多样性。3) 智能体的集成方式,例如使用不同的权重分配策略或模型选择方法来优化最终模型的性能。
🖼️ 关键图片
📊 实验亮点
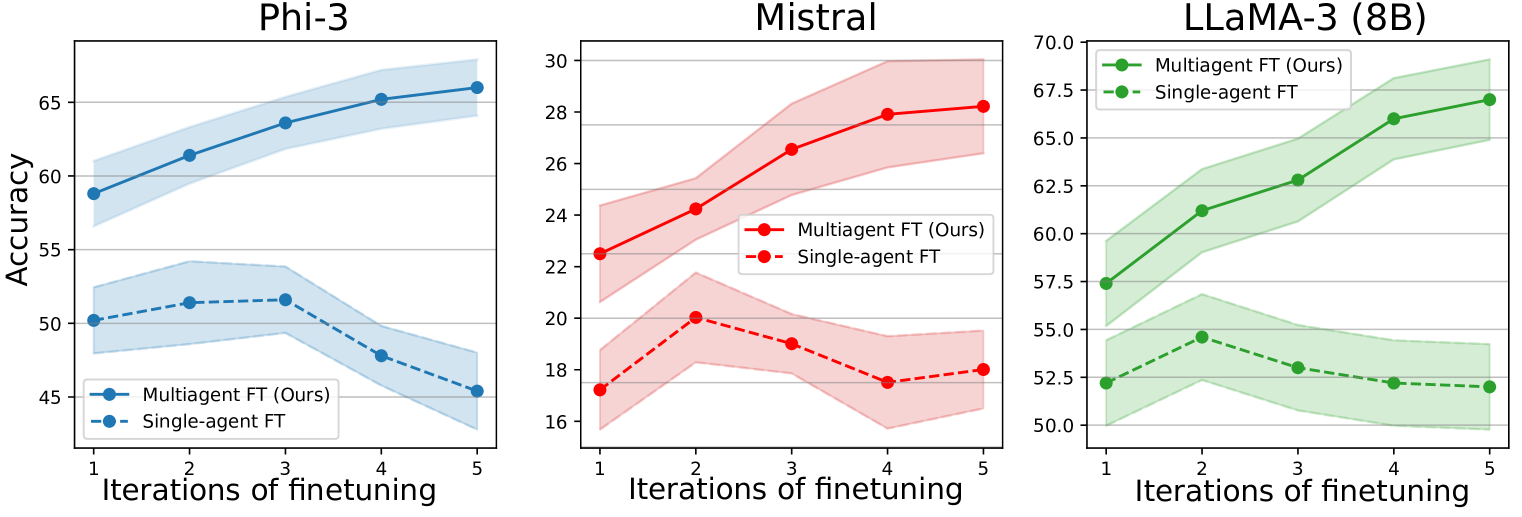
论文在多个推理任务上进行了实验,结果表明,多智能体微调方法能够显著提升LLM的性能。例如,在某些任务上,该方法能够比单智能体自我改进方法提高10%以上的准确率。此外,实验还表明,多智能体微调方法能够有效地保留多样化的推理链,从而提高模型的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于各种需要持续自主改进的LLM应用场景,例如智能客服、自动问答、代码生成等。通过多智能体微调,可以提升LLM在复杂任务中的性能和鲁棒性,并降低对人工标注数据的依赖。未来,该方法有望应用于更广泛的AI领域,例如机器人学习、强化学习等。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable performance in recent years but are fundamentally limited by the underlying training data. To improve models beyond the training data, recent works have explored how LLMs can be used to generate synthetic data for autonomous self-improvement. However, successive steps of self-improvement can reach a point of diminishing returns. In this work, we propose a complementary approach towards self-improvement where finetuning is applied to a multiagent society of language models. A group of language models, all starting from the same base model, are independently specialized by updating each one using data generated through multiagent interactions among the models. By training each model on independent sets of data, we illustrate how this approach enables specialization across models and diversification over the set of models. As a result, our overall system is able to preserve diverse reasoning chains and autonomously improve over many more rounds of fine-tuning than single-agent self-improvement methods. We quantitatively illustrate the efficacy of the approach across a wide suite of reasoning tasks.