Unlocking In-Context Learning for Natural Datasets Beyond Language Modelling
作者: Jelena Bratulić, Sudhanshu Mittal, David T. Hoffmann, Samuel Böhm, Robin Tibor Schirrmeister, Tonio Ball, Christian Rupprecht, Thomas Brox
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-09 (更新: 2025-10-06)
备注: Best Paper Honorable Mention at GCPR 2025 (German Conference on Pattern Recognition). This is the updated version submitted to the conference, not the official conference proceedings
💡 一句话要点
揭示并促进自回归模型上下文学习能力,拓展至视觉和脑电数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 自回归模型 视觉数据集 脑电分类 token重复 任务难度 迁移学习
📋 核心要点
- 现有方法在文本以外模态上,上下文学习能力不明显,限制了模型在更广泛领域的应用。
- 通过分析大型语言模型,发现token重复和任务难度是影响上下文学习能力的关键因素。
- 通过调整训练策略,成功将上下文学习能力扩展到视觉和脑电数据集,提升了模型性能。
📝 摘要(中文)
大型语言模型(LLMs)展现出上下文学习(ICL)能力,仅通过上下文中提供的示例即可执行新任务,无需更新模型权重。虽然ICL为自然语言任务和领域提供了快速适应性,但对于文本以外的模态,其出现并不那么直接。本文系统地揭示了LLMs中支持自回归模型和各种模态ICL出现的属性,通过促进ICL所需机制的学习来实现。我们发现训练数据序列中精确的token重复是ICL的一个重要因素。这种重复进一步提高了ICL性能的稳定性并减少了瞬态性。此外,我们强调了训练任务难度对于ICL出现的重要性。最后,通过将我们对ICL出现的新见解应用于各种视觉数据集和一个更具挑战性的脑电分类任务,我们解锁了ICL能力。
🔬 方法详解
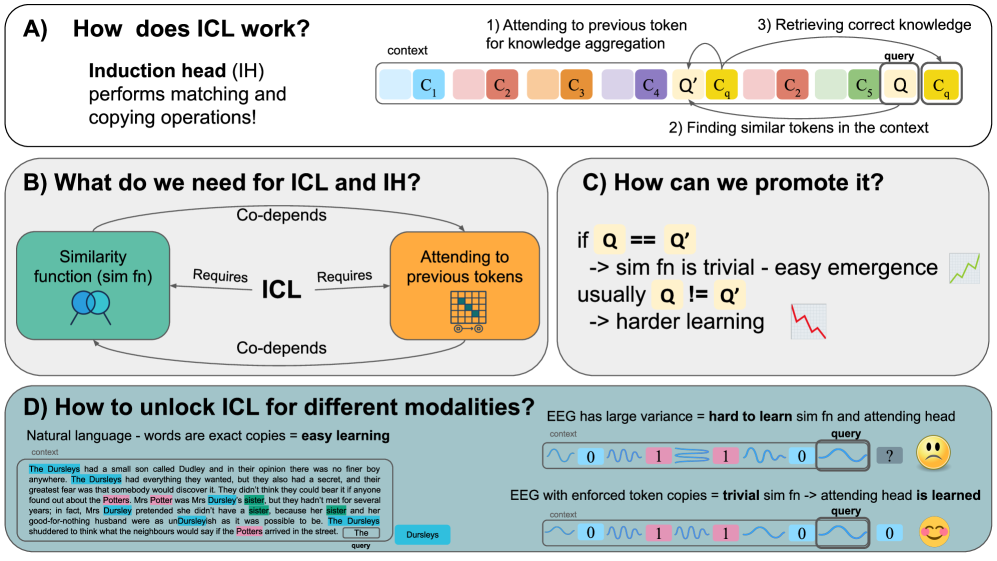
问题定义:论文旨在解决大型语言模型(LLMs)的上下文学习(ICL)能力在自然语言以外的数据集上表现不佳的问题。现有方法在将ICL应用于视觉和脑电等非语言模态时面临挑战,因为这些模态的数据特性与语言数据差异较大,导致模型难以泛化和适应。
核心思路:论文的核心思路是识别并促进LLMs中支持ICL的关键属性的学习,从而解锁ICL在非语言模态上的潜力。具体来说,论文强调了训练数据中token重复的重要性,以及训练任务难度对ICL能力的影响。通过控制这些因素,可以提高模型在非语言数据集上的ICL性能。
技术框架:论文没有提出一个全新的架构,而是侧重于分析和改进现有自回归模型的训练方式。其主要流程包括:1) 分析LLMs中影响ICL的因素;2) 设计实验验证这些因素的重要性;3) 基于分析结果,调整训练数据和任务难度,以促进ICL在非语言模态上的出现;4) 在视觉和脑电数据集上评估改进后的模型的ICL性能。
关键创新:论文的关键创新在于揭示了token重复和训练任务难度对ICL的重要性,并提出了相应的训练策略来促进ICL在非语言模态上的应用。与现有方法相比,该论文更注重理解ICL的内在机制,并基于这些理解来改进模型的训练方式,而不是简单地将LLMs应用于非语言数据。
关键设计:论文的关键设计包括:1) 在训练数据中引入精确的token重复,以提高ICL的稳定性;2) 调整训练任务的难度,使其更适合ICL的学习;3) 使用标准的自回归模型结构,但通过改进训练数据和任务来提升ICL性能;4) 采用标准的分类和回归损失函数,但重点关注如何通过ICL来提高模型的预测精度。
🖼️ 关键图片


📊 实验亮点
论文通过实验证明,在视觉和脑电数据集上,通过引入token重复和调整训练任务难度,可以显著提高模型的上下文学习能力。例如,在脑电分类任务上,改进后的模型在ICL设置下取得了显著的性能提升,证明了该方法的有效性。具体的性能数据提升幅度在论文中有详细展示。
🎯 应用场景
该研究成果可应用于各种需要快速适应新任务的场景,例如医疗诊断、工业检测和机器人控制。通过上下文学习,模型可以根据少量示例快速适应新的数据分布和任务要求,无需重新训练,从而降低了部署成本和时间。未来,该技术有望推动人工智能在更广泛领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) exhibit In-Context Learning (ICL), which enables the model to perform new tasks conditioning only on the examples provided in the context without updating the model's weights. While ICL offers fast adaptation across natural language tasks and domains, its emergence is less straightforward for modalities beyond text. In this work, we systematically uncover properties present in LLMs that support the emergence of ICL for autoregressive models and various modalities by promoting the learning of the needed mechanisms for ICL. We identify exact token repetitions in the training data sequences as an important factor for ICL. Such repetitions further improve stability and reduce transiency in ICL performance. Moreover, we emphasise the significance of training task difficulty for the emergence of ICL. Finally, by applying our novel insights on ICL emergence, we unlock ICL capabilities for various visual datasets and a more challenging EEG classification task.