Optimizing Estonian TV Subtitles with Semi-supervised Learning and LLMs
作者: Artem Fedorchenko, Tanel Alumäe
分类: cs.CL, cs.AI, cs.LG, eess.AS
发布日期: 2025-01-09
💡 一句话要点
利用半监督学习和LLM优化爱沙尼亚语电视字幕生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 爱沙尼亚语字幕生成 半监督学习 大型语言模型 伪标签 Whisper模型
📋 核心要点
- 现有爱沙尼亚语电视字幕生成质量不高,难以满足用户需求,需要提升字幕的准确性和流畅性。
- 该方法的核心是利用微调的 Whisper 模型结合半监督学习和 LLM 后编辑,从而提升字幕质量。
- 实验结果表明,伪标签和 LLM 后编辑能够显著提升字幕质量,有望达到接近人工的标准。
📝 摘要(中文)
本文提出了一种为爱沙尼亚语电视内容生成高质量同语言字幕的方法。该方法首先在人工生成的爱沙尼亚语字幕上微调 Whisper 模型,然后通过迭代伪标签和基于大型语言模型(LLM)的后编辑来增强其性能。实验表明,通过使用未标记数据集进行伪标签,字幕质量得到了显著提高。研究发现,在测试时应用基于 LLM 的编辑可以提高字幕的准确性,但在训练期间使用 LLM 并不能带来进一步的增益。该方法有望生成接近人工标准的字幕质量,并可以扩展到实时应用。
🔬 方法详解
问题定义:本文旨在解决爱沙尼亚语电视节目字幕生成质量不高的问题。现有的自动语音识别(ASR)模型在处理爱沙尼亚语时,由于数据稀缺等问题,生成的字幕质量往往难以满足实际需求,存在准确率低、流畅性差等问题。因此,如何提高爱沙尼亚语电视节目字幕的生成质量是本文要解决的核心问题。
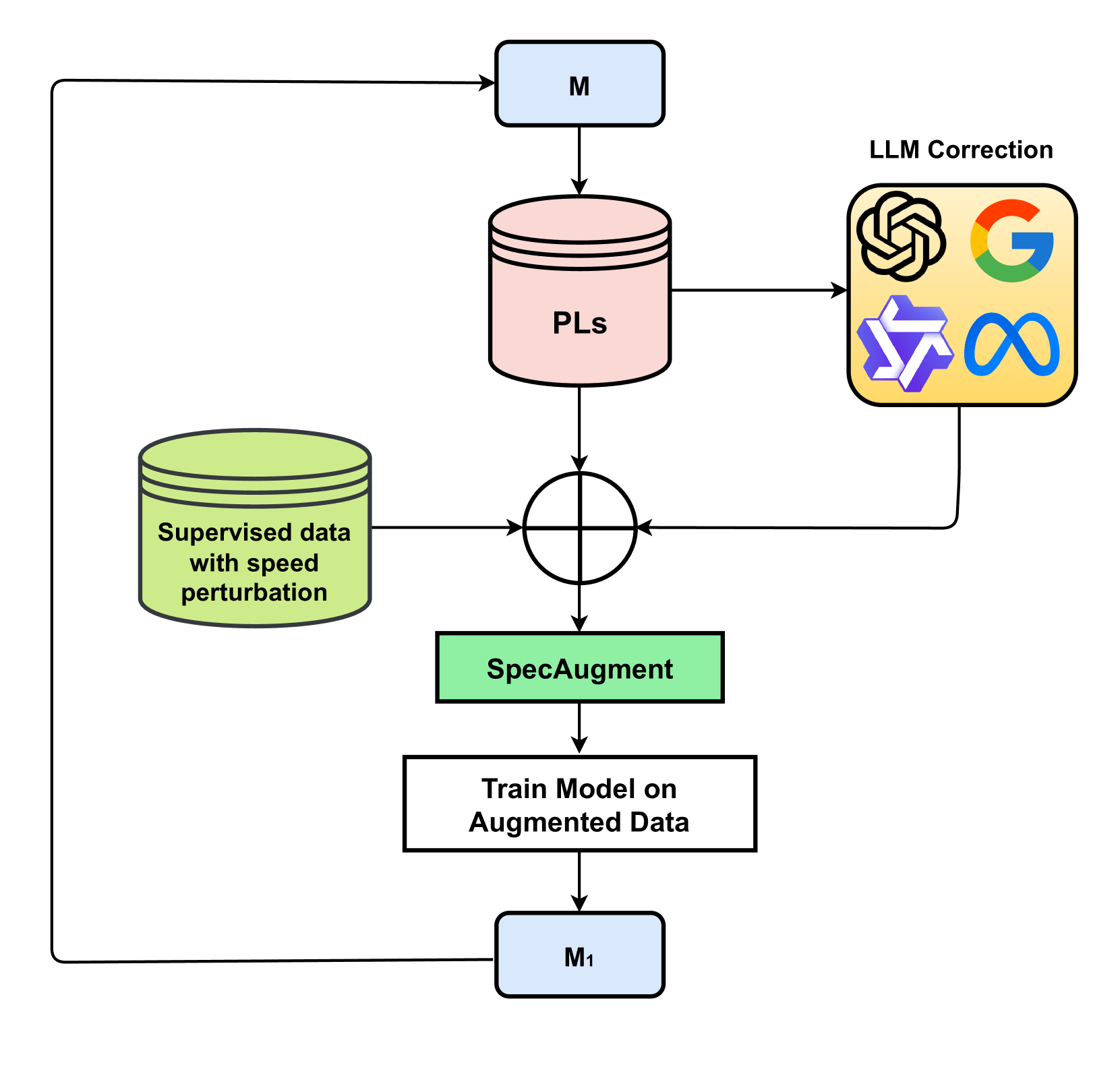
核心思路:本文的核心思路是利用半监督学习和大型语言模型(LLM)的强大能力来提升字幕质量。首先,利用少量人工标注的爱沙尼亚语字幕数据微调 Whisper 模型,使其具备初步的字幕生成能力。然后,通过伪标签技术,利用大量的未标注数据进一步提升模型的泛化能力。最后,利用 LLM 对生成的字幕进行后编辑,纠正错误、提升流畅性。
技术框架:整体框架包含三个主要阶段:1) 基于人工标注数据微调 Whisper 模型;2) 利用微调后的模型对未标注数据进行伪标签,并用伪标签数据再次训练模型;3) 使用 LLM 对生成的字幕进行后编辑。具体流程是,首先使用 Whisper 模型生成字幕,然后使用 LLM 对字幕进行润色和纠错,最终得到高质量的字幕。
关键创新:本文的关键创新在于将半监督学习和 LLM 后编辑相结合,用于爱沙尼亚语电视字幕生成。传统的字幕生成方法往往依赖于大量的标注数据,而本文通过伪标签技术,有效利用了未标注数据,降低了对标注数据的依赖。同时,利用 LLM 的强大语言理解和生成能力,对字幕进行后编辑,进一步提升了字幕质量。
关键设计:在伪标签阶段,选择置信度高的预测结果作为伪标签,以减少噪声数据对模型训练的影响。在 LLM 后编辑阶段,使用提示工程(prompt engineering)来指导 LLM 进行字幕润色和纠错。具体的提示词设计需要根据实际情况进行调整,以达到最佳的编辑效果。此外,还探索了在训练阶段使用 LLM 进行数据增强的方法,但实验结果表明效果不明显。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过伪标签技术,字幕质量得到了显著提高。与基线 Whisper 模型相比,经过伪标签训练的模型在字幕准确率方面取得了显著提升。此外,在测试时应用 LLM 后编辑,进一步提高了字幕的准确性。虽然在训练阶段使用 LLM 进行数据增强没有带来明显的增益,但为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于爱沙尼亚语电视节目的自动字幕生成,提高字幕质量,提升用户观看体验。此外,该方法也可推广到其他低资源语言的字幕生成任务中,具有广泛的应用前景。未来,该技术有望应用于实时字幕生成,为听力障碍人士提供更好的服务。
📄 摘要(原文)
This paper presents an approach for generating high-quality, same-language subtitles for Estonian TV content. We fine-tune the Whisper model on human-generated Estonian subtitles and enhance it with iterative pseudo-labeling and large language model (LLM) based post-editing. Our experiments demonstrate notable subtitle quality improvement through pseudo-labeling with an unlabeled dataset. We find that applying LLM-based editing at test time enhances subtitle accuracy, while its use during training does not yield further gains. This approach holds promise for creating subtitle quality close to human standard and could be extended to real-time applications.