Leveraging Large Language Models for Zero-shot Lay Summarisation in Biomedicine and Beyond
作者: Tomas Goldsack, Carolina Scarton, Chenghua Lin
分类: cs.CL
发布日期: 2025-01-09
备注: Preprint
💡 一句话要点
提出基于大语言模型的两阶段零样本生物医学领域摘要生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 零样本学习 领域摘要生成 生物医学 自然语言处理
📋 核心要点
- 现有领域摘要生成方法依赖大量标注数据,缺乏在低资源领域的泛化能力,本文旨在探索零样本领域摘要生成。
- 论文提出一种模拟人类写作过程的两阶段框架,利用大语言模型直接生成领域摘要,无需特定领域的训练数据。
- 实验表明,该方法生成的摘要更受人类评估者青睐,且大语言模型可有效评估摘要质量,并能推广到新的NLP领域。
📝 摘要(中文)
本文探索了大语言模型在零样本领域摘要生成中的应用。我们提出了一种新颖的、基于现实过程的两阶段领域摘要生成框架,并发现对于更大的模型,通过该方法生成的摘要越来越受到人类评估者的青睐。为了帮助建立在零样本设置中使用大语言模型的最佳实践,我们还评估了大语言模型作为评估者的能力,发现它们能够复现人类评估者的偏好。最后,我们朝着自然语言处理(NLP)文章的领域摘要生成迈出了初步的步伐,发现大语言模型能够推广到这个新的领域,并通过深入的人工评估进一步突出了我们提出的方法生成的摘要的更大效用。
🔬 方法详解
问题定义:本文旨在解决生物医学领域以及其他领域(如NLP)的零样本领域摘要生成问题。现有方法通常需要大量的标注数据进行训练,这在数据稀缺的领域是不可行的。因此,如何在没有特定领域训练数据的情况下,利用大语言模型生成高质量的领域摘要是一个关键挑战。
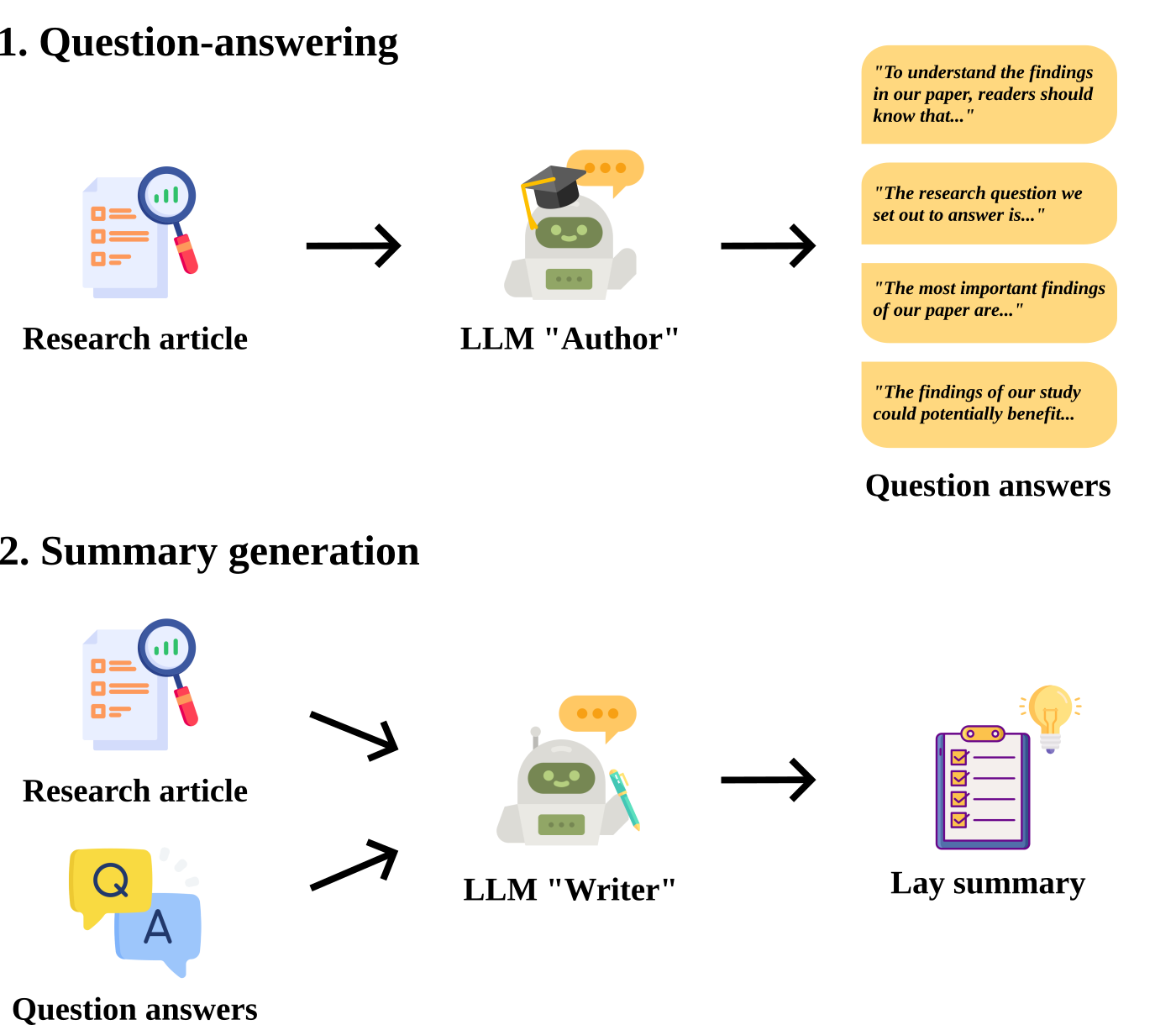
核心思路:论文的核心思路是模拟人类撰写领域摘要的过程,将其分解为两个阶段:首先,理解原始文档的关键信息;然后,用通俗易懂的语言重新表达这些信息。这种分解使得大语言模型能够更好地利用其预训练的知识,从而在零样本设置下生成高质量的摘要。
技术框架:该方法采用两阶段框架。第一阶段,利用大语言模型提取原始文档的关键信息,可以理解为生成一个初步的、技术性的摘要。第二阶段,将第一阶段生成的摘要作为输入,再次利用大语言模型将其改写成面向非专业人士的通俗易懂的领域摘要。整个流程无需任何领域特定的训练数据。
关键创新:该方法的主要创新在于其两阶段的框架设计,它模拟了人类的写作过程,使得大语言模型能够更好地利用其预训练的知识,从而在零样本设置下生成高质量的领域摘要。与直接使用大语言模型生成摘要相比,该方法能够更好地控制摘要的质量和可读性。
关键设计:论文的关键设计包括:(1) 使用特定prompt引导大语言模型进行信息提取和改写;(2) 探索不同大小的大语言模型对摘要生成质量的影响;(3) 设计人工评估方案,评估摘要的质量和可读性;(4) 评估大语言模型作为评估者的能力,验证其是否能够复现人类评估者的偏好。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法生成的摘要更受人类评估者青睐,尤其是在使用更大的大语言模型时。此外,研究发现大语言模型能够有效地评估摘要质量,与人类评估者的偏好具有较高的一致性。该方法成功地推广到NLP领域,进一步验证了其泛化能力。
🎯 应用场景
该研究成果可广泛应用于生物医学、自然语言处理等领域,帮助科研人员和公众快速理解专业文献。该方法降低了领域摘要生成的成本,促进了知识的传播和应用,未来可应用于更多低资源领域,例如法律、金融等。
📄 摘要(原文)
In this work, we explore the application of Large Language Models to zero-shot Lay Summarisation. We propose a novel two-stage framework for Lay Summarisation based on real-life processes, and find that summaries generated with this method are increasingly preferred by human judges for larger models. To help establish best practices for employing LLMs in zero-shot settings, we also assess the ability of LLMs as judges, finding that they are able to replicate the preferences of human judges. Finally, we take the initial steps towards Lay Summarisation for Natural Language Processing (NLP) articles, finding that LLMs are able to generalise to this new domain, and further highlighting the greater utility of summaries generated by our proposed approach via an in-depth human evaluation.