Comparison of Feature Learning Methods for Metadata Extraction from PDF Scholarly Documents
作者: Zeyd Boukhers, Cong Yang
分类: cs.IR, cs.CL, cs.DL, cs.LG
发布日期: 2025-01-09
💡 一句话要点
评估NLP、CV和多模态特征学习方法,提升PDF学术文档元数据提取性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 元数据提取 PDF文档 自然语言处理 计算机视觉 多模态学习 特征学习 学术文档
📋 核心要点
- 现有方法在处理模板多样性高的PDF文档时,元数据提取效果不佳,尤其是在小众出版物和特定学科中。
- 论文核心在于对比NLP、CV和多模态特征学习方法,探索它们在元数据提取任务中的性能差异和适用性。
- 实验结果全面分析了各种方法的准确性和效率,为未来研究提供了有价值的参考和指导。
📝 摘要(中文)
科学文档元数据的可用性对于推动科学知识进步和遵守研究成果的FAIR原则至关重要。然而,已发表文档中元数据不足,特别是来自中小型出版商的文档,阻碍了其可访问性。这个问题在某些学科中很普遍,例如德国社会科学,其出版物通常采用不同的模板。为了应对这一挑战,本研究评估了各种特征学习和预测方法,包括自然语言处理(NLP)、计算机视觉(CV)和多模态方法,用于从具有高模板方差的文档中提取元数据。我们的目标是提高科学文档的可访问性,并促进其更广泛的使用。为了支持我们对这些方法的比较,我们提供了全面的实验结果,分析了它们在提取元数据方面的准确性和效率。此外,我们还深入了解了各种特征学习和预测方法的优缺点,这可以指导该领域的未来研究。
🔬 方法详解
问题定义:论文旨在解决PDF学术文档元数据提取的问题,特别是针对那些模板多样性高、元数据信息不完整的文档。现有方法在处理这些文档时,由于缺乏对文档结构和内容的有效理解,导致提取准确率较低,无法满足FAIR原则的要求。
核心思路:论文的核心思路是探索和比较不同的特征学习方法,包括自然语言处理(NLP)、计算机视觉(CV)以及多模态方法,以找到最适合从复杂PDF文档中提取元数据的方法。通过综合利用文本、图像和布局信息,提高元数据提取的准确性和鲁棒性。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据预处理:对PDF文档进行解析,提取文本、图像和布局信息;2) 特征学习:使用NLP、CV和多模态方法学习文档的特征表示;3) 元数据预测:基于学习到的特征,预测文档的元数据信息,如标题、作者、摘要等;4) 性能评估:使用准确率、召回率等指标评估不同方法的性能。
关键创新:论文的关键创新在于对多种特征学习方法进行了全面的比较和分析,并探讨了它们在元数据提取任务中的优缺点。通过实验结果,为研究者提供了选择合适方法的指导,并为未来的研究方向提供了参考。
关键设计:论文的关键设计包括:1) 针对不同的元数据类型,选择合适的特征学习方法;2) 设计有效的多模态融合策略,将文本、图像和布局信息进行整合;3) 采用合适的损失函数和优化算法,训练特征学习模型;4) 使用标准化的评估指标,对不同方法的性能进行客观的比较。
🖼️ 关键图片


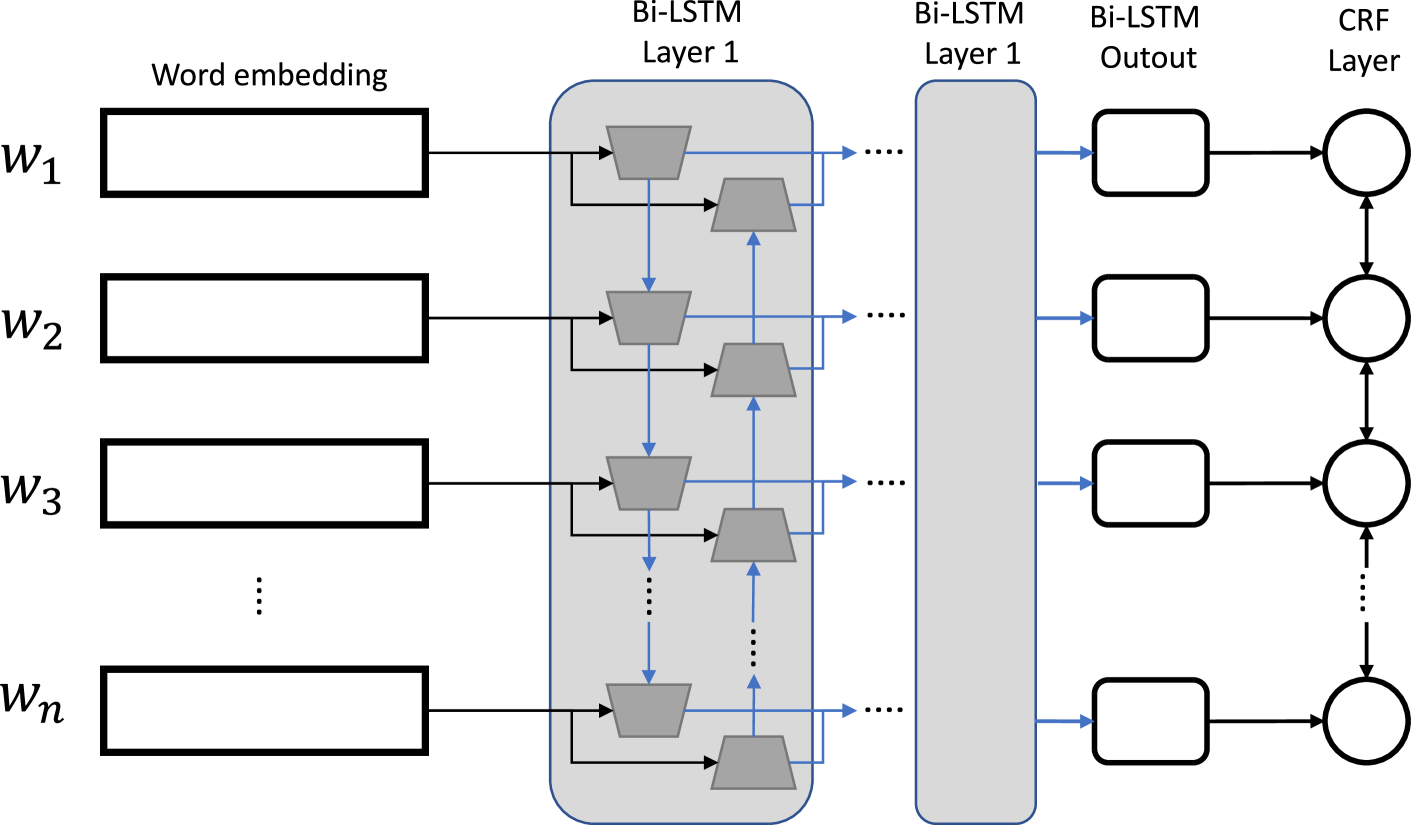
📊 实验亮点
论文通过实验对比了NLP、CV和多模态方法在元数据提取任务中的性能。实验结果表明,多模态方法通常能够取得更好的效果,因为它能够综合利用文本、图像和布局信息。具体的性能数据和对比基线在论文中进行了详细的展示,为研究者提供了有价值的参考。
🎯 应用场景
该研究成果可应用于数字图书馆、学术搜索引擎、知识管理系统等领域,提高学术文档的可发现性、可访问性和互操作性。通过自动提取元数据,可以减少人工标注的工作量,提高数据质量,促进科学知识的传播和利用。未来,该技术可进一步应用于其他类型的文档,如专利、报告等。
📄 摘要(原文)
The availability of metadata for scientific documents is pivotal in propelling scientific knowledge forward and for adhering to the FAIR principles (i.e. Findability, Accessibility, Interoperability, and Reusability) of research findings. However, the lack of sufficient metadata in published documents, particularly those from smaller and mid-sized publishers, hinders their accessibility. This issue is widespread in some disciplines, such as the German Social Sciences, where publications often employ diverse templates. To address this challenge, our study evaluates various feature learning and prediction methods, including natural language processing (NLP), computer vision (CV), and multimodal approaches, for extracting metadata from documents with high template variance. We aim to improve the accessibility of scientific documents and facilitate their wider use. To support our comparison of these methods, we provide comprehensive experimental results, analyzing their accuracy and efficiency in extracting metadata. Additionally, we provide valuable insights into the strengths and weaknesses of various feature learning and prediction methods, which can guide future research in this field.