TreeKV: Smooth Key-Value Cache Compression with Tree Structures
作者: Ziwei He, Jian Yuan, Haoli Bai, Jingwen Leng, Bo Jiang
分类: cs.CL
发布日期: 2025-01-09 (更新: 2025-05-16)
💡 一句话要点
提出TreeKV:一种基于树结构的平滑Key-Value缓存压缩方法,适用于长序列LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Key-Value缓存压缩 大型语言模型 长序列建模 树结构 Transformer 缓存优化 语言建模
📋 核心要点
- 现有KV缓存压缩方法在长序列LLM中存在局限,基于位置的方法易丢失关键信息,基于重要性的方法则存在区域偏差。
- TreeKV利用树结构进行平滑缓存压缩,无需训练,适用于生成和预填充阶段,并能保持固定缓存大小。
- 实验表明,TreeKV在语言建模和长文本基准测试中均优于现有方法,能以更小的缓存实现更好的性能。
📝 摘要(中文)
高效的键值(KV)缓存压缩对于扩展基于Transformer的大型语言模型(LLM)在长序列和资源受限环境下的应用至关重要。现有方法基于位置或重要性分数驱逐token,但前者可能错过预定义区域之外的关键信息,后者则导致强烈的区域偏差,限制了KV缓存的整体上下文保留能力,并可能损害LLM在复杂任务上的性能。我们的 wavelet 分析表明,随着token接近序列末尾,它们对生成的贡献逐渐增加,并且往往与相邻token的差异更大,表明从远到近的上下文存在一个平滑过渡,其复杂性和可变性不断增加。受此启发,我们提出TreeKV,一种直观、免训练的方法,它采用树结构进行平滑缓存压缩。TreeKV保持固定的缓存大小,使LLM即使在长文本场景中也能提供高质量的输出。与大多数压缩方法不同,TreeKV适用于生成和预填充阶段。在PG19和OpenWebText2上的语言建模任务中,TreeKV始终优于所有基线模型,使使用短上下文窗口训练的LLM能够推广到具有16倍缓存减少的更长窗口。在Longbench基准测试中,TreeKV以最佳效率仅用6%的预算实现了最佳性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在长序列处理中,KV缓存压缩效率低下的问题。现有方法,如基于位置的驱逐策略,无法有效保留全局重要信息;而基于重要性分数的策略,则容易产生区域偏差,导致上下文信息丢失,最终影响LLM的性能。
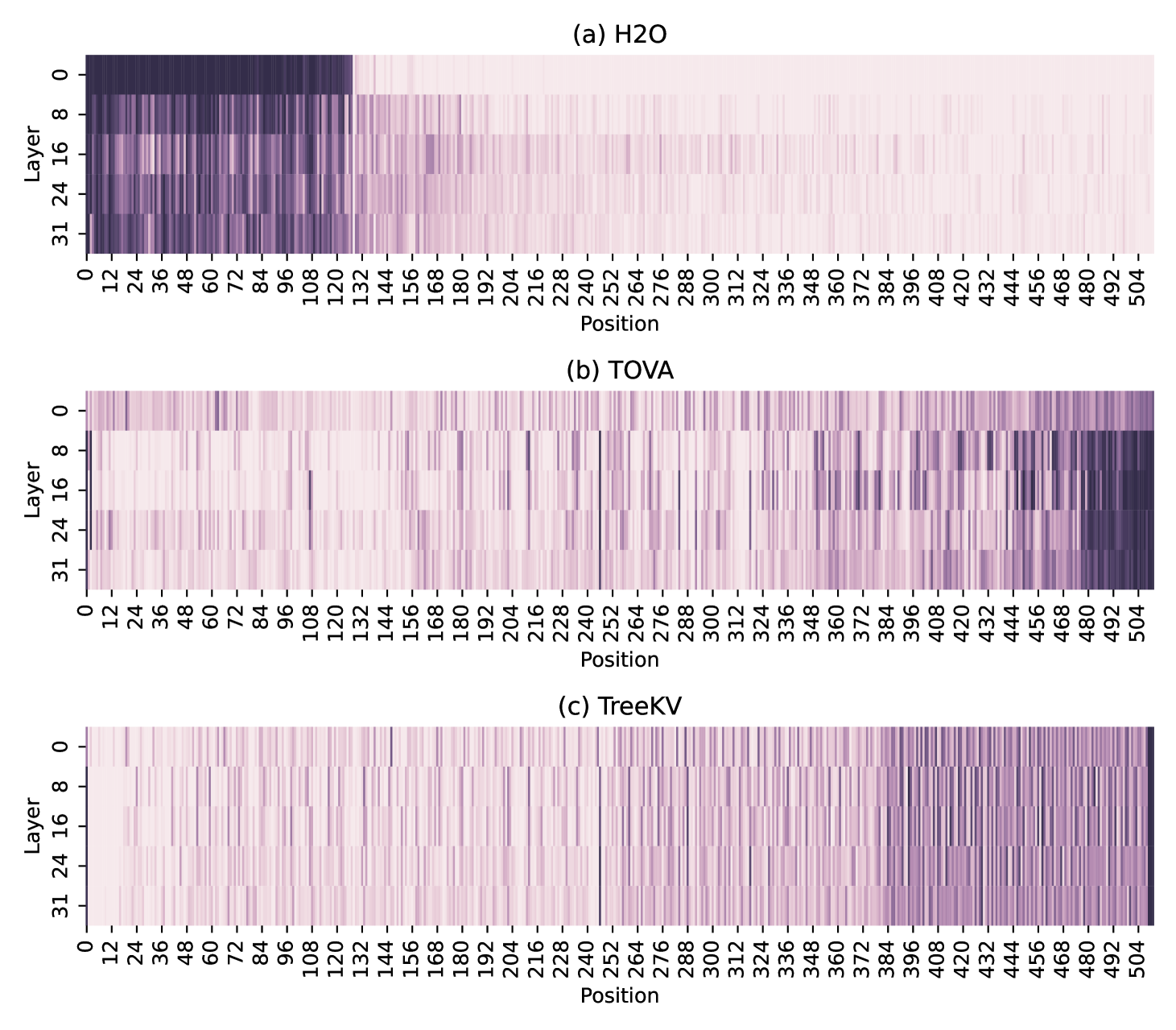
核心思路:论文的核心思路是利用树结构来模拟token贡献度随序列位置变化的平滑过渡特性。通过 wavelet 分析发现,序列末尾的token对生成结果的贡献更大,且与相邻token的差异性也更大。因此,采用树结构可以更好地捕捉这种平滑变化,从而实现更有效的缓存压缩。
技术框架:TreeKV方法主要包含以下几个阶段:1)构建树结构:根据序列长度构建一个树结构,每个节点代表一个token或一组token的聚合信息。2)重要性评估:评估每个节点的重要性,例如基于token的注意力权重或梯度信息。3)缓存压缩:根据树结构和节点的重要性,自底向上地进行缓存压缩,保留重要的节点,并丢弃不重要的节点。4)KV缓存更新:将压缩后的KV缓存用于LLM的推理或训练。
关键创新:TreeKV的关键创新在于其利用树结构进行平滑缓存压缩。与现有方法相比,TreeKV能够更好地捕捉token贡献度随序列位置变化的平滑过渡特性,从而实现更有效的缓存压缩,同时避免了区域偏差问题。此外,TreeKV是一种免训练的方法,可以直接应用于现有的LLM。
关键设计:TreeKV的关键设计包括:1)树结构的构建方式,例如二叉树或多叉树;2)节点重要性的评估指标,例如注意力权重或梯度信息;3)缓存压缩的策略,例如基于阈值的剪枝或基于比例的采样;4)树结构的更新频率,例如每隔一定数量的token进行更新。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TreeKV在PG19和OpenWebText2数据集上优于所有基线模型,实现了16倍的缓存减少。在Longbench基准测试中,TreeKV仅使用6%的缓存预算就达到了最佳性能。这些结果表明,TreeKV能够有效地压缩KV缓存,同时保持LLM的性能,使其能够处理更长的序列。
🎯 应用场景
TreeKV具有广泛的应用前景,尤其是在资源受限的环境下部署长序列LLM。例如,它可以应用于移动设备上的智能助手、边缘计算设备上的自然语言处理应用,以及需要处理长文档的文本摘要和机器翻译等任务。通过减少KV缓存的大小,TreeKV可以显著降低LLM的内存占用和计算成本,从而提高其部署效率和可扩展性。
📄 摘要(原文)
Efficient key-value (KV) cache compression is critical for scaling transformer-based Large Language Models (LLMs) in long sequences and resource-limited settings. Existing methods evict tokens based on their positions or importance scores, but position-based strategies can miss crucial information outside predefined regions, while those relying on global importance scores resulting in strong regional biases, limiting the KV cache's overall context retention and potentially impairing the performance of LLMs on complex tasks. Our wavelet analysis reveals that as tokens approach the end of sequence, their contributions to generation gradually increase and tends to diverge more from neighboring tokens, indicating a smooth transition with increasing complexity and variability from distant to nearby context. Motivated by this observation, we propose TreeKV, an intuitive, training-free method that employs a tree structure for smooth cache compression. TreeKV maintains a fixed cache size, allowing LLMs to deliver high-quality output even in long text scenarios. Unlike most compression methods, TreeKV is applicable to both the generation and prefilling stages. TreeKV consistently surpasses all baseline models in language modeling tasks on PG19 and OpenWebText2, allowing LLMs trained with short context window to generalize to longer window with a 16x cache reduction. On the Longbench benchmark, TreeKV achieves the best performance with only 6\% of the budget at optimal efficiency.