Unlocking Multimodal Mathematical Reasoning via Process Reward Model
作者: Ruilin Luo, Zhuofan Zheng, Yifan Wang, Xinzhe Ni, Zicheng Lin, Songtao Jiang, Yiyao Yu, Chufan Shi, Lei Wang, Ruihang Chu, Jin Zeng, Yujiu Yang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-08 (更新: 2025-10-05)
备注: NeurIPS 2025 Main Track
💡 一句话要点
提出URSA框架,通过过程奖励模型解锁多模态数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数学推理 过程奖励模型 强化学习 思维链 数据集构建 自动标注
📋 核心要点
- 现有MLLM在多模态数学推理中面临数据稀缺、过程标注困难和奖励机制易受攻击等挑战。
- URSA框架通过构建大规模数据集、自动合成过程监督数据和改进强化学习算法来解决上述问题。
- 实验表明,URSA框架显著提升了MLLM在多模态数学推理任务上的性能,超越了现有先进模型。
📝 摘要(中文)
过程奖励模型(PRMs)已显示出通过测试时缩放(TTS)增强大型语言模型(LLMs)数学推理能力的潜力。然而,它们在多模态推理中的集成在很大程度上仍未被探索。本文旨在初步探索PRMs在多模态数学推理中的潜力。研究识别了三个关键挑战:(1)高质量推理数据的稀缺限制了基础多模态大型语言模型(MLLMs)的能力,进一步限制了TTS和强化学习(RL)的上限;(2)多模态环境中缺乏自动化的过程标注方法;(3)在单模态RL中使用过程奖励面临奖励黑客等问题,这些问题可能延伸到多模态场景。为了解决这些问题,我们引入了URSA,一个三阶段的展开式多模态过程监督辅助训练框架。我们首先构建了MMathCoT-1M,一个高质量的大规模多模态思维链(CoT)推理数据集,以构建更强大的数学推理基础MLLM,URSA-8B。随后,我们通过一个自动过程来合成过程监督数据,强调逻辑正确性和感知一致性。我们引入DualMath-1.1M来促进URSA-8B-RM的训练。最后,我们提出了过程监督的组相对策略优化(PS-GRPO),开创了一种多模态PRM辅助的在线RL方法,该方法优于vanilla GRPO。通过PS-GRPO的应用,URSA-8B-PS-GRPO在6个基准测试中平均优于Gemma3-12B和GPT-4o 8.4%和2.7%。代码、数据和检查点可在https://github.com/URSA-MATH找到。
🔬 方法详解
问题定义:论文旨在解决多模态数学推理中,由于高质量数据匮乏、缺乏自动过程标注方法以及过程奖励模型在多模态场景下的奖励利用问题,导致现有MLLM推理能力受限的问题。现有方法难以有效利用多模态信息进行复杂数学推理,且容易受到奖励机制的攻击。
核心思路:论文的核心思路是通过构建大规模高质量数据集,并结合自动过程监督和改进的强化学习算法,来提升MLLM在多模态数学推理任务上的性能。通过显式地建模推理过程,并对每一步进行监督和奖励,从而引导模型学习更可靠的推理路径。
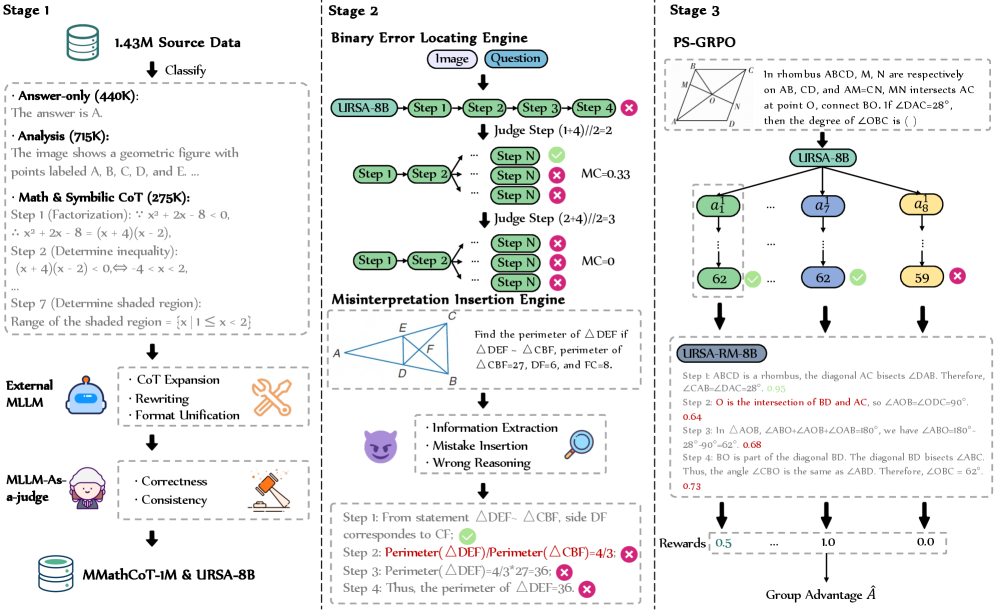
技术框架:URSA框架包含三个主要阶段: 1. MMathCoT-1M数据集构建:构建大规模多模态思维链数据集,用于训练基础MLLM。 2. DualMath-1.1M数据集合成:通过自动过程合成过程监督数据,强调逻辑正确性和感知一致性,用于训练奖励模型。 3. PS-GRPO强化学习:提出过程监督的组相对策略优化算法,利用奖励模型指导在线强化学习。
关键创新:论文的关键创新在于: 1. 多模态过程监督:将过程奖励模型引入多模态数学推理领域,显式地建模推理过程。 2. 自动过程标注:提出自动合成过程监督数据的方法,解决了多模态场景下人工标注成本高的问题。 3. PS-GRPO算法:改进了组相对策略优化算法,使其更适用于多模态过程奖励学习,降低了奖励利用的风险。
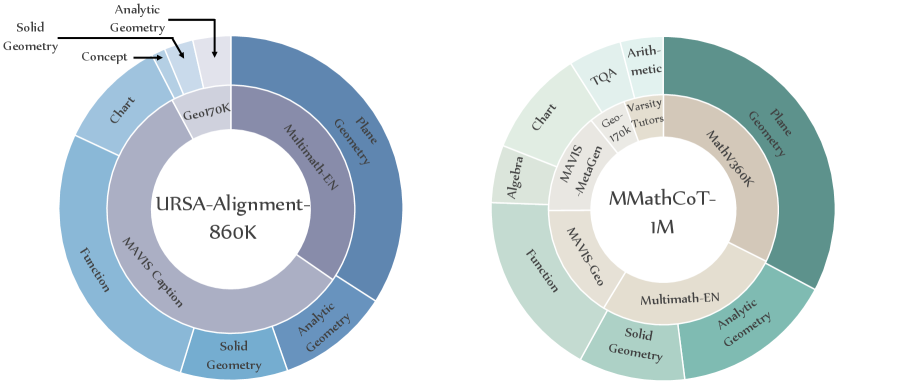
关键设计: 1. MMathCoT-1M数据集:包含100万个多模态数学推理问题,覆盖多种题型和场景。 2. DualMath-1.1M数据集:包含110万个过程监督样本,通过规则和模型生成,保证逻辑和感知一致性。 3. PS-GRPO算法:采用组相对策略优化,避免单一策略的过度优化;引入过程监督信号,约束策略学习方向。
🖼️ 关键图片
📊 实验亮点
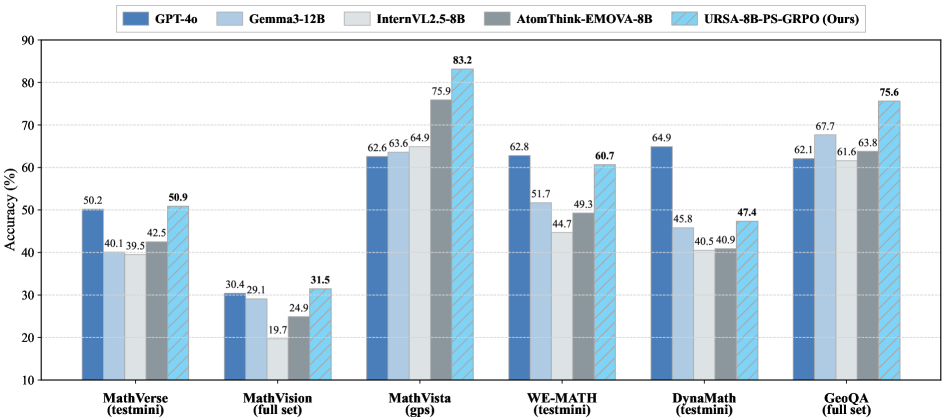
实验结果表明,URSA-8B-PS-GRPO模型在6个多模态数学推理基准测试中,平均超越Gemma3-12B模型8.4%,超越GPT-4o模型2.7%。这表明URSA框架能够有效提升MLLM在多模态数学推理任务上的性能,并达到甚至超越了现有最先进的模型。
🎯 应用场景
该研究成果可应用于智能教育、数学辅助工具、科学研究等领域。例如,可以开发更智能的数学辅导系统,帮助学生理解和解决复杂的数学问题。此外,该技术还可以应用于科学图像分析、数据可视化等领域,辅助科研人员进行更深入的研究。
📄 摘要(原文)
Process Reward Models (PRMs) have shown promise in enhancing the mathematical reasoning capabilities of Large Language Models (LLMs) through Test-Time Scaling (TTS). However, their integration into multimodal reasoning remains largely unexplored. In this work, we take the first step toward unlocking the potential of PRMs in multimodal mathematical reasoning. We identify three key challenges: (1) the scarcity of high-quality reasoning data constrains the capabilities of foundation Multimodal Large Language Models (MLLMs), which imposes further limitations on the upper bounds of TTS and reinforcement learning (RL); (2) a lack of automated methods for process labeling within multimodal contexts persists; (3) the employment of process rewards in unimodal RL faces issues like reward hacking, which may extend to multimodal scenarios. To address these issues, we introduce URSA, a three-stage Unfolding multimodal Process-Supervision Aided training framework. We first construct MMathCoT-1M, a high-quality large-scale multimodal Chain-of-Thought (CoT) reasoning dataset, to build a stronger math reasoning foundation MLLM, URSA-8B. Subsequently, we go through an automatic process to synthesize process supervision data, which emphasizes both logical correctness and perceptual consistency. We introduce DualMath-1.1M to facilitate the training of URSA-8B-RM. Finally, we propose Process-Supervised Group-Relative-Policy-Optimization (PS-GRPO), pioneering a multimodal PRM-aided online RL method that outperforms vanilla GRPO. With PS-GRPO application, URSA-8B-PS-GRPO outperforms Gemma3-12B and GPT-4o by 8.4% and 2.7% on average across 6 benchmarks. Code, data and checkpoint can be found at https://github.com/URSA-MATH.