Multi-task retriever fine-tuning for domain-specific and efficient RAG
作者: Patrice Béchard, Orlando Marquez Ayala
分类: cs.CL, cs.IR, cs.LG
发布日期: 2025-01-08 (更新: 2025-07-16)
备注: 7 pages, 2 figures. Accepted at Workshop on Structured Knowledge for Large Language Models (SKnowLLM) at KDD 2025
💡 一句话要点
提出多任务检索器微调方法,提升领域特定RAG效率与泛化性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多任务学习 指令微调 领域特定 检索器 大型语言模型 RAG 企业应用
📋 核心要点
- 现有RAG系统在领域特定场景中检索质量不高,且为每个应用部署单独检索器成本高昂。
- 通过指令微调小型检索器编码器,使其能够处理多个领域特定任务,实现单编码器服务多用例。
- 实验表明,该方法在领域外设置和未见过的检索任务中具有良好的泛化能力,适用于实际企业用例。
📝 摘要(中文)
检索增强生成(RAG)已成为部署大型语言模型(LLM)的常用方法,因为它能够解决生成幻觉或过时信息等典型限制。然而,在构建实际的RAG应用时,会出现一些实际问题。首先,检索到的信息通常是领域特定的。由于微调LLM的计算成本很高,因此微调检索器以提高LLM输入中包含的数据质量更为可行。其次,随着越来越多的应用程序部署在同一实际系统中,无法负担部署单独的检索器。此外,这些RAG应用程序通常检索不同类型的数据。我们的解决方案是指令微调一个小型检索器编码器,使其能够处理各种领域特定的任务,从而部署一个可以服务于多个用例的编码器,从而实现低成本、可扩展性和速度。我们展示了该编码器如何推广到领域外设置以及实际企业用例中未见过的检索任务。
🔬 方法详解
问题定义:论文旨在解决RAG系统中,针对领域特定数据检索质量不高,以及为每个RAG应用单独部署检索器所带来的高成本和低效率问题。现有方法通常需要为每个领域或任务训练单独的检索器,这在实际部署中难以扩展,且计算资源消耗巨大。
核心思路:论文的核心思路是通过多任务指令微调,训练一个通用的检索器编码器,使其能够处理多个领域和任务的检索需求。这样,只需要部署一个检索器,即可服务于多个RAG应用,从而降低成本,提高效率。
技术框架:该方法主要包含以下几个阶段:1) 构建多任务指令数据集,涵盖多个领域和任务的检索需求。2) 选择一个预训练的小型检索器编码器作为基础模型。3) 使用多任务指令数据集对检索器编码器进行微调,使其能够理解和执行不同任务的检索指令。4) 将微调后的检索器编码器部署到RAG系统中,用于检索相关文档。
关键创新:该方法最重要的创新点在于提出了多任务指令微调的检索器训练方法。与传统的单任务检索器训练方法相比,该方法能够显著提高检索器的泛化能力,使其能够适应不同的领域和任务。此外,通过指令微调,可以更灵活地控制检索器的行为,使其能够更好地满足不同RAG应用的需求。
关键设计:论文中,指令数据集的设计至关重要,需要涵盖不同领域和任务的检索需求,并提供清晰的指令,指导检索器进行检索。损失函数方面,可以使用对比学习损失或交叉熵损失,以优化检索器的检索效果。此外,选择合适的预训练模型和微调策略也对最终性能有重要影响。
🖼️ 关键图片
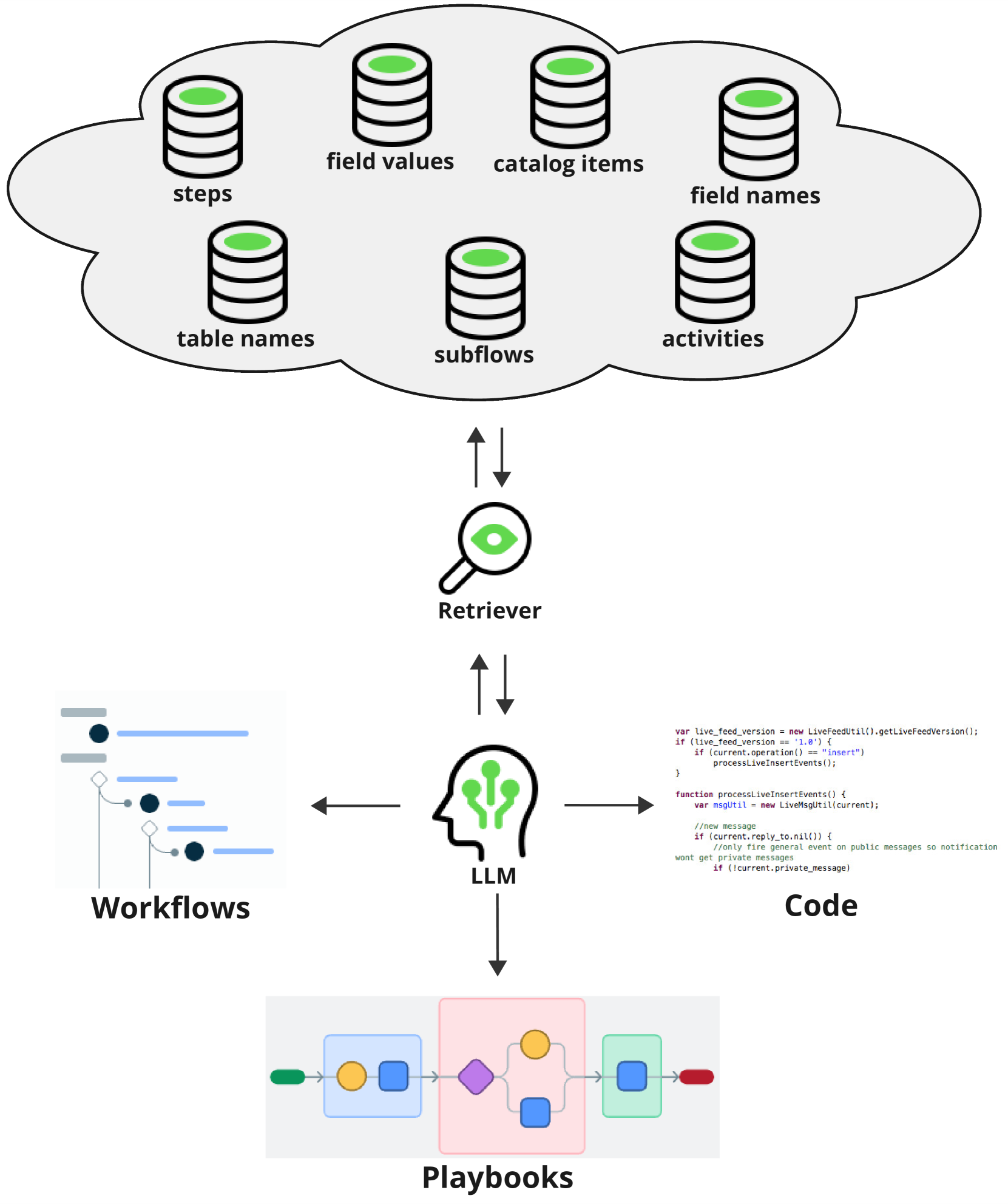

📊 实验亮点
论文展示了该方法在实际企业用例中的有效性,证明了其在领域外设置和未见过的检索任务中的泛化能力。虽然具体性能数据未知,但结论表明,相较于为每个任务单独训练检索器,该方法在保证检索质量的同时,显著降低了部署和维护成本,提升了RAG系统的可扩展性。
🎯 应用场景
该研究成果可广泛应用于企业级RAG系统,例如智能客服、知识库问答、文档检索等。通过部署一个通用的多任务检索器,可以降低RAG系统的部署和维护成本,提高检索效率和准确性,从而提升用户体验和企业效率。未来,该方法还可以扩展到更多领域和任务,例如多模态检索、跨语言检索等。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) has become ubiquitous when deploying Large Language Models (LLMs), as it can address typical limitations such as generating hallucinated or outdated information. However, when building real-world RAG applications, practical issues arise. First, the retrieved information is generally domain-specific. Since it is computationally expensive to fine-tune LLMs, it is more feasible to fine-tune the retriever to improve the quality of the data included in the LLM input. Second, as more applications are deployed in the same real-world system, one cannot afford to deploy separate retrievers. Moreover, these RAG applications normally retrieve different kinds of data. Our solution is to instruction fine-tune a small retriever encoder on a variety of domain-specific tasks to allow us to deploy one encoder that can serve many use cases, thereby achieving low-cost, scalability, and speed. We show how this encoder generalizes to out-of-domain settings as well as to an unseen retrieval task on real-world enterprise use cases.