Quantum-inspired Embeddings Projection and Similarity Metrics for Representation Learning
作者: Ivan Kankeu, Stefan Gerd Fritsch, Gunnar Schönhoff, Elie Mounzer, Paul Lukowicz, Maximilian Kiefer-Emmanouilidis
分类: cs.CL, cond-mat.dis-nn, quant-ph
发布日期: 2025-01-08
💡 一句话要点
提出一种量子启发的嵌入投影和相似性度量方法,用于表征学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表征学习 量子启发 嵌入压缩 量子电路 信息检索
📋 核心要点
- 表征学习中的投影头是关键组件,但传统方法可能参数量大,效率较低。
- 本文提出量子启发的投影头,将经典嵌入映射到量子态,并利用量子电路进行降维。
- 实验结果表明,该方法在参数量大幅减少的情况下,性能与经典方法相当,甚至在小数据集上更优。
📝 摘要(中文)
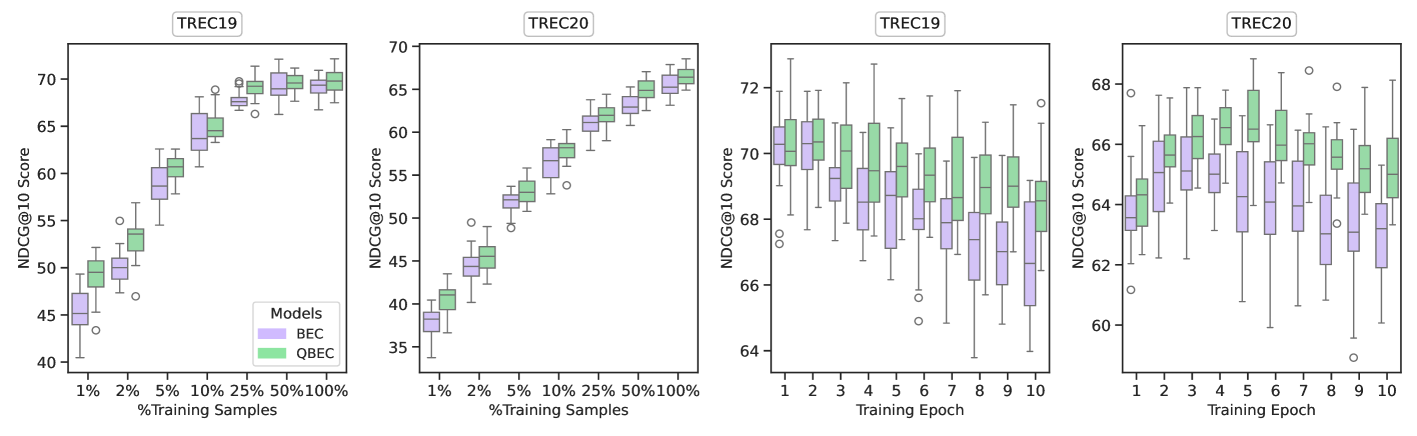
本文提出了一种量子启发的投影头,以及相应的量子启发的相似性度量,用于表征学习。该方法将经典嵌入映射到希尔伯特空间的量子态,并引入基于量子电路的投影头来降低嵌入维度。为了评估该方法的有效性,我们将提出的投影头集成到BERT语言模型中,用于嵌入压缩。通过TREC 2019和TREC 2020深度学习基准测试,在信息检索任务上,比较了使用量子启发投影头压缩的嵌入与使用经典投影头压缩的嵌入的性能。结果表明,我们的量子启发方法在参数量减少32倍的情况下,实现了与经典方法相当的性能。此外,从头开始训练时,该方法表现出色,尤其是在较小的数据集上。这项工作不仅突出了量子启发方法的有效性,还强调了神经网络中高效的、专门的低纠缠电路模拟作为一种强大的量子启发技术的实用性。
🔬 方法详解
问题定义:论文旨在解决表征学习中嵌入向量维度过高的问题,尤其是在大型语言模型和计算机视觉系统中。现有的投影头通常需要大量的参数,增加了计算负担和存储需求。
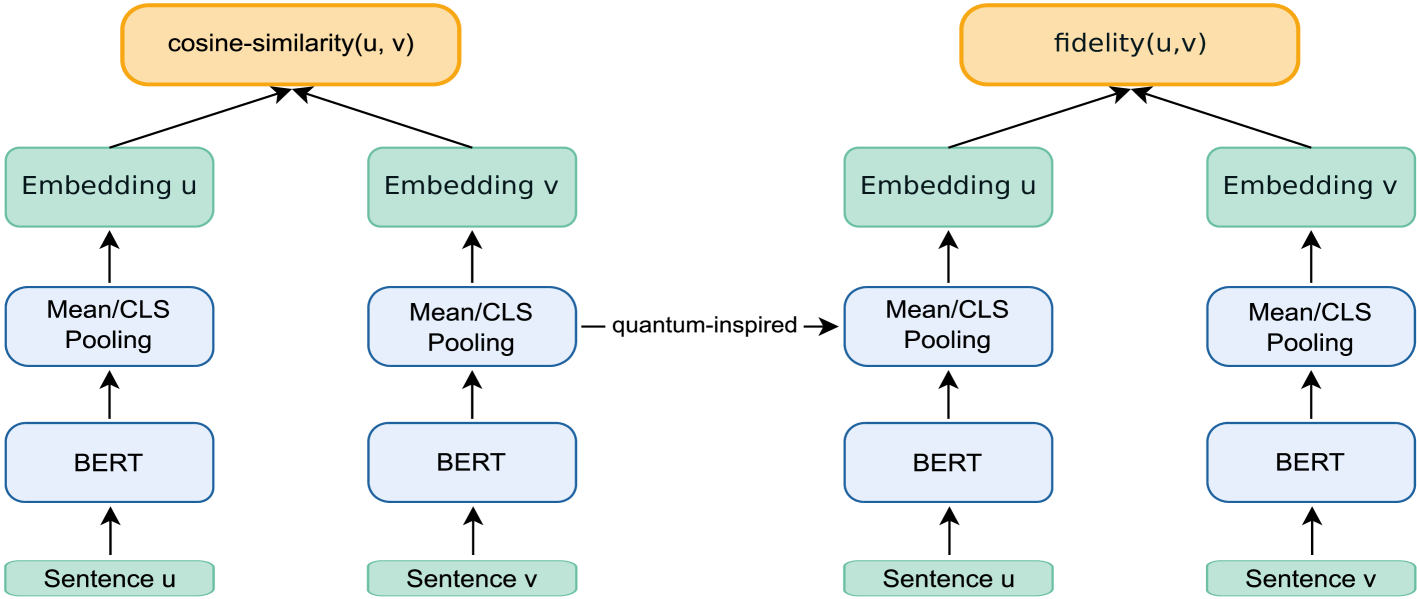
核心思路:论文的核心思路是将经典嵌入向量映射到量子态,并利用量子电路的特性进行降维。通过模拟量子电路,可以实现高效的嵌入压缩,同时保留向量之间的相似性关系。这种方法借鉴了量子计算的优势,旨在降低参数量,提高计算效率。
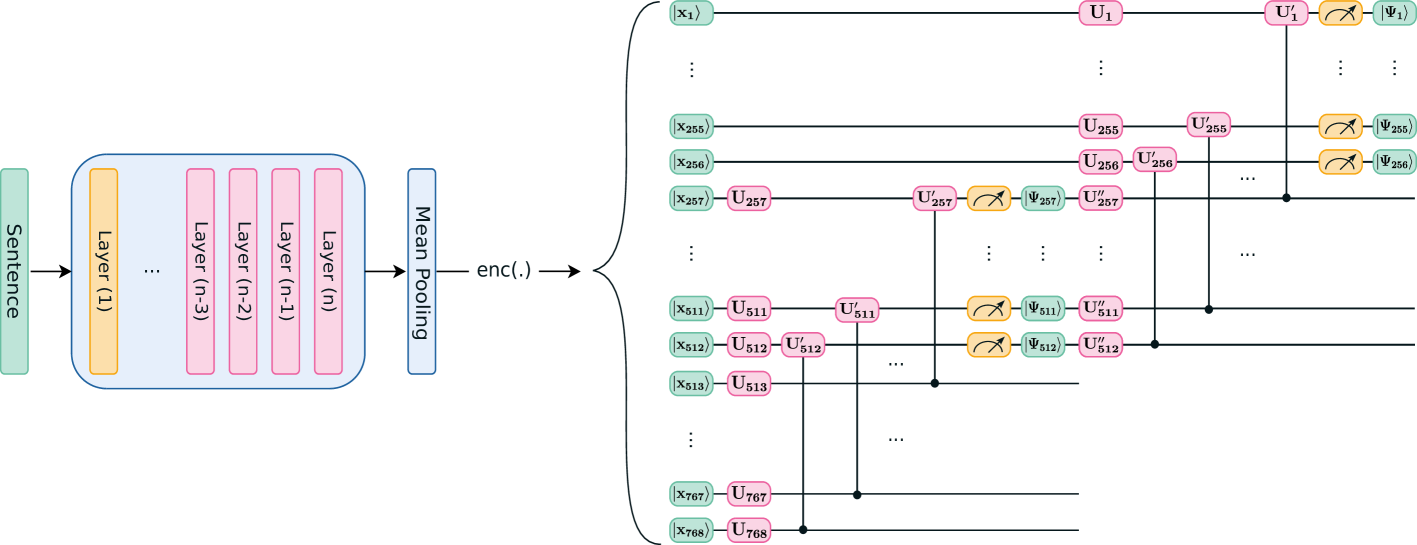
技术框架:该方法主要包含以下几个阶段:1) 将经典嵌入向量编码为希尔伯特空间的量子态;2) 使用量子电路作为投影头,对量子态进行变换,降低维度;3) 使用量子启发的相似性度量来衡量降维后的向量之间的相似度。整体架构是将量子电路集成到现有的神经网络结构中,例如BERT。
关键创新:最重要的技术创新点在于利用量子电路进行嵌入压缩。与传统的线性或非线性投影方法不同,量子电路可以通过调整量子门的参数来实现复杂的变换,从而更有效地降低维度,同时保留关键信息。此外,量子启发的相似性度量也能够更好地反映降维后向量之间的关系。
关键设计:论文中使用了低纠缠的量子电路,以便在经典计算机上进行高效的模拟。具体的电路结构和量子门的参数需要根据具体的任务进行调整。损失函数的设计需要考虑如何最大程度地保留原始嵌入向量的相似性关系。此外,论文还探讨了不同的量子编码方式对性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,量子启发的投影头在TREC 2019和TREC 2020深度学习基准测试中,实现了与经典方法相当的性能,同时参数量减少了32倍。在小数据集上从头开始训练时,该方法表现更优。这些结果表明,该方法在降低计算成本和提高效率方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要高效表征学习的领域,例如自然语言处理、计算机视觉和推荐系统。通过降低嵌入维度,可以减少计算资源消耗,提高模型训练和推理速度,尤其是在资源受限的设备上。此外,该方法还可以用于保护隐私,通过降维来隐藏原始数据的敏感信息。
📄 摘要(原文)
Over the last decade, representation learning, which embeds complex information extracted from large amounts of data into dense vector spaces, has emerged as a key technique in machine learning. Among other applications, it has been a key building block for large language models and advanced computer vision systems based on contrastive learning. A core component of representation learning systems is the projection head, which maps the original embeddings into different, often compressed spaces, while preserving the similarity relationship between vectors. In this paper, we propose a quantum-inspired projection head that includes a corresponding quantum-inspired similarity metric. Specifically, we map classical embeddings onto quantum states in Hilbert space and introduce a quantum circuit-based projection head to reduce embedding dimensionality. To evaluate the effectiveness of this approach, we extended the BERT language model by integrating our projection head for embedding compression. We compared the performance of embeddings, which were compressed using our quantum-inspired projection head, with those compressed using a classical projection head on information retrieval tasks using the TREC 2019 and TREC 2020 Deep Learning benchmarks. The results demonstrate that our quantum-inspired method achieves competitive performance relative to the classical method while utilizing 32 times fewer parameters. Furthermore, when trained from scratch, it notably excels, particularly on smaller datasets. This work not only highlights the effectiveness of the quantum-inspired approach but also emphasizes the utility of efficient, ad hoc low-entanglement circuit simulations within neural networks as a powerful quantum-inspired technique.