OpenOmni: Advancing Open-Source Omnimodal Large Language Models with Progressive Multimodal Alignment and Real-Time Self-Aware Emotional Speech Synthesis
作者: Run Luo, Ting-En Lin, Haonan Zhang, Yuchuan Wu, Xiong Liu, Min Yang, Yongbin Li, Longze Chen, Jiaming Li, Lei Zhang, Xiaobo Xia, Hamid Alinejad-Rokny, Fei Huang
分类: cs.CL, cs.CV
发布日期: 2025-01-08 (更新: 2025-09-23)
💡 一句话要点
OpenOmni:通过渐进式多模态对齐和实时情感语音合成,推进开源全模态大语言模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全模态学习 大语言模型 语音合成 情感识别 跨模态对齐
📋 核心要点
- 现有全模态大语言模型主要为专有模型,缺乏高质量数据集和实时情感语音合成技术是开源研究的瓶颈。
- OpenOmni通过两阶段训练框架,整合全模态对齐和语音生成,实现高性能的开源全模态大语言模型。
- 实验结果表明,OpenOmni在多个基准测试中超越现有模型,并在推理速度和情感分类准确率上有所提升。
📝 摘要(中文)
全模态学习的最新进展显著提升了图像、文本和语音的理解与生成能力,但这些进展主要局限于专有模型。缺乏高质量的全模态数据集以及实时情感语音合成的挑战,显著阻碍了开源研究的进展。为了解决这些限制,我们提出了OpenOmni,一个两阶段训练框架,它整合了全模态对齐和语音生成,以开发最先进的全模态大语言模型。在对齐阶段,预训练的语音模型在文本-图像任务上进行进一步训练,从而实现从视觉到语音的(近)零样本泛化,优于在三模态数据集上训练的模型。在语音生成阶段,一个轻量级解码器在语音任务上进行训练,采用直接偏好优化,从而实现高保真度的实时情感语音合成。实验表明,OpenOmni在全模态、视觉-语言和语音-语言基准测试中超越了最先进的模型。在OmniBench上,它比领先的开源模型VITA取得了4个百分点的绝对提升,尽管使用的训练样本少了5倍,模型尺寸也更小(7B vs. 7x8B)。此外,OpenOmni实现了非自回归模式下的实时语音生成,延迟小于1秒,与自回归方法相比,推理时间减少了5倍,并将情感分类准确率提高了7.7%。
🔬 方法详解
问题定义:现有全模态大语言模型的研究主要集中在闭源模型中,开源领域缺乏高性能的模型。同时,高质量全模态数据集的匮乏以及实时情感语音合成的挑战限制了开源全模态大语言模型的发展。现有方法在跨模态对齐和语音合成方面存在不足,难以实现高效且高质量的语音生成。
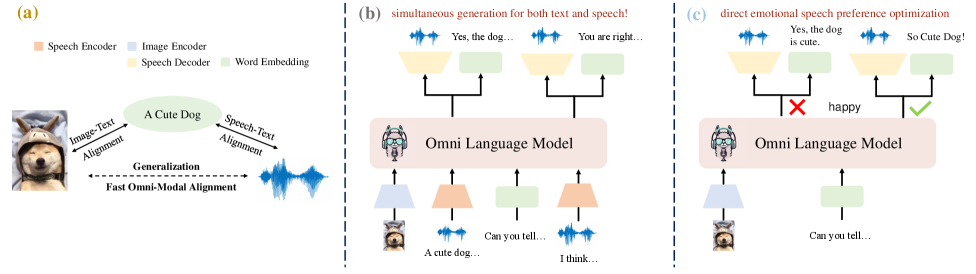
核心思路:OpenOmni的核心思路是通过两阶段训练框架,首先进行全模态对齐,然后进行语音生成。在对齐阶段,利用预训练的语音模型在文本-图像任务上进行训练,实现视觉到语音的零样本泛化。在语音生成阶段,采用轻量级解码器和直接偏好优化,实现实时情感语音合成。
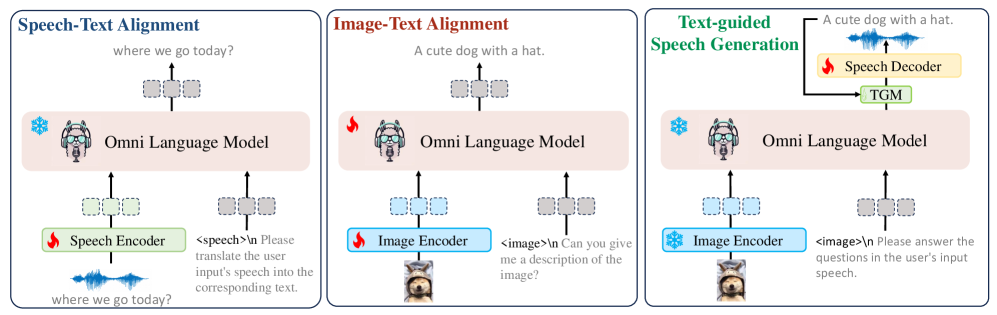
技术框架:OpenOmni的整体框架包含两个主要阶段:全模态对齐阶段和语音生成阶段。在全模态对齐阶段,使用预训练的语音模型,并在文本-图像数据集上进行微调,使其具备视觉理解能力。在语音生成阶段,训练一个轻量级的解码器,并使用直接偏好优化方法,使其能够生成高质量的情感语音。
关键创新:OpenOmni的关键创新在于其两阶段训练框架,该框架能够有效地整合全模态对齐和语音生成。通过在文本-图像任务上训练预训练的语音模型,实现了视觉到语音的零样本泛化,避免了对大规模三模态数据集的依赖。此外,采用轻量级解码器和直接偏好优化方法,实现了实时情感语音合成。
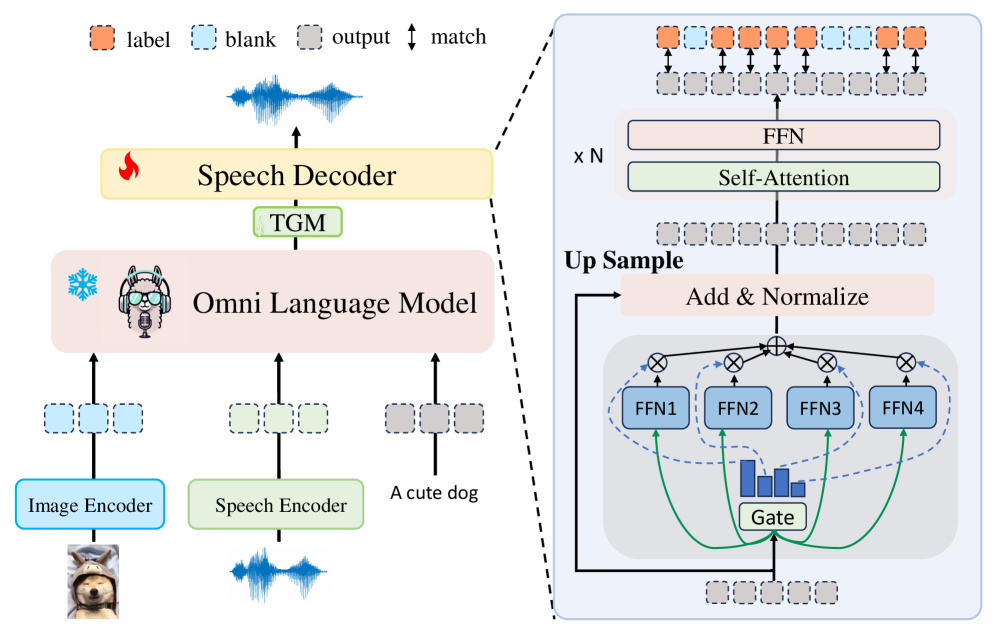
关键设计:在全模态对齐阶段,采用了对比学习损失函数,以促进不同模态之间的对齐。在语音生成阶段,使用了Transformer结构的解码器,并采用直接偏好优化方法,直接优化语音质量和情感表达。为了实现实时语音合成,采用了非自回归的生成方式,显著降低了推理延迟。具体参数设置和网络结构细节未知。
🖼️ 关键图片
📊 实验亮点
OpenOmni在OmniBench基准测试中,比领先的开源模型VITA取得了4个百分点的绝对提升,同时使用的训练样本少了5倍,模型尺寸也更小(7B vs. 7x8B)。此外,OpenOmni实现了非自回归模式下的实时语音生成,延迟小于1秒,与自回归方法相比,推理时间减少了5倍,并将情感分类准确率提高了7.7%。
🎯 应用场景
OpenOmni具有广泛的应用前景,例如智能助手、情感客服、语音交互游戏等。它可以用于生成具有丰富情感表达的语音,提升人机交互的自然性和用户体验。此外,该模型还可以应用于多模态内容创作,例如根据图像生成相应的语音描述,或根据文本生成带有情感的语音内容。
📄 摘要(原文)
Recent advancements in omnimodal learning have significantly improved understanding and generation across images, text, and speech, yet these developments remain predominantly confined to proprietary models. The lack of high-quality omnimodal datasets and the challenges of real-time emotional speech synthesis have notably hindered progress in open-source research. To address these limitations, we introduce \name, a two-stage training framework that integrates omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model undergoes further training on text-image tasks, enabling (near) zero-shot generalization from vision to speech, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder is trained on speech tasks with direct preference optimization, enabling real-time emotional speech synthesis with high fidelity. Experiments show that \name surpasses state-of-the-art models across omnimodal, vision-language, and speech-language benchmarks. It achieves a 4-point absolute improvement on OmniBench over the leading open-source model VITA, despite using 5x fewer training samples and a smaller model size (7B vs. 7x8B). Additionally, \name achieves real-time speech generation with <1s latency at non-autoregressive mode, reducing inference time by 5x compared to autoregressive methods, and improves emotion classification accuracy by 7.7\%