Graph-Based Multimodal Contrastive Learning for Chart Question Answering
作者: Yue Dai, Soyeon Caren Han, Wei Liu
分类: cs.CL
发布日期: 2025-01-08 (更新: 2025-04-07)
备注: Accepted at SIGIR 2025
💡 一句话要点
提出基于图的多模态对比学习框架,解决图表问答中异构信息融合难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表问答 多模态学习 图神经网络 对比学习 思维链 场景图
📋 核心要点
- 图表问答面临图表元素异构和数据模式微妙的挑战,现有方法难以有效融合。
- 提出联合多模态场景图框架,结合视觉和文本图,利用图对比学习对齐跨模态信息。
- 定制思维链提示增强多模态大语言模型,减轻幻觉,并在多个基准测试中取得显著提升。
📝 摘要(中文)
图表问答(ChartQA)面临图表元素异构组合和数据模式微妙的挑战。本文提出了一种新颖的联合多模态场景图框架,显式地建模图表组件之间的关系及其底层结构。该框架集成了视觉和文本图,以捕获结构和语义特征,同时采用图对比学习策略来对齐跨模态的节点表示,从而将它们无缝地整合到Transformer解码器中作为软提示。此外,提出了一组定制的思维链(CoT)提示,通过减轻幻觉来增强零样本场景中的多模态大型语言模型(MLLM)。在ChartQA、OpenCQA和ChartX等基准上的大量评估表明,性能得到了显著提高,并验证了所提出方法的有效性。
🔬 方法详解
问题定义:图表问答任务旨在根据给定的图表图像和问题,生成正确的答案。现有方法在处理图表元素之间的复杂关系以及图表中蕴含的细粒度数据模式时存在困难,尤其是在多模态信息融合方面表现不足。此外,多模态大语言模型在零样本场景下容易产生幻觉,影响答案的准确性。
核心思路:本文的核心思路是利用图结构显式地建模图表中的元素及其关系,从而更好地捕捉图表的结构和语义信息。通过构建视觉和文本图,分别表示图表的视觉特征和文本信息,并使用图对比学习策略对齐不同模态的节点表示,实现多模态信息的有效融合。同时,引入定制的思维链提示,引导模型进行更合理的推理,减少幻觉。
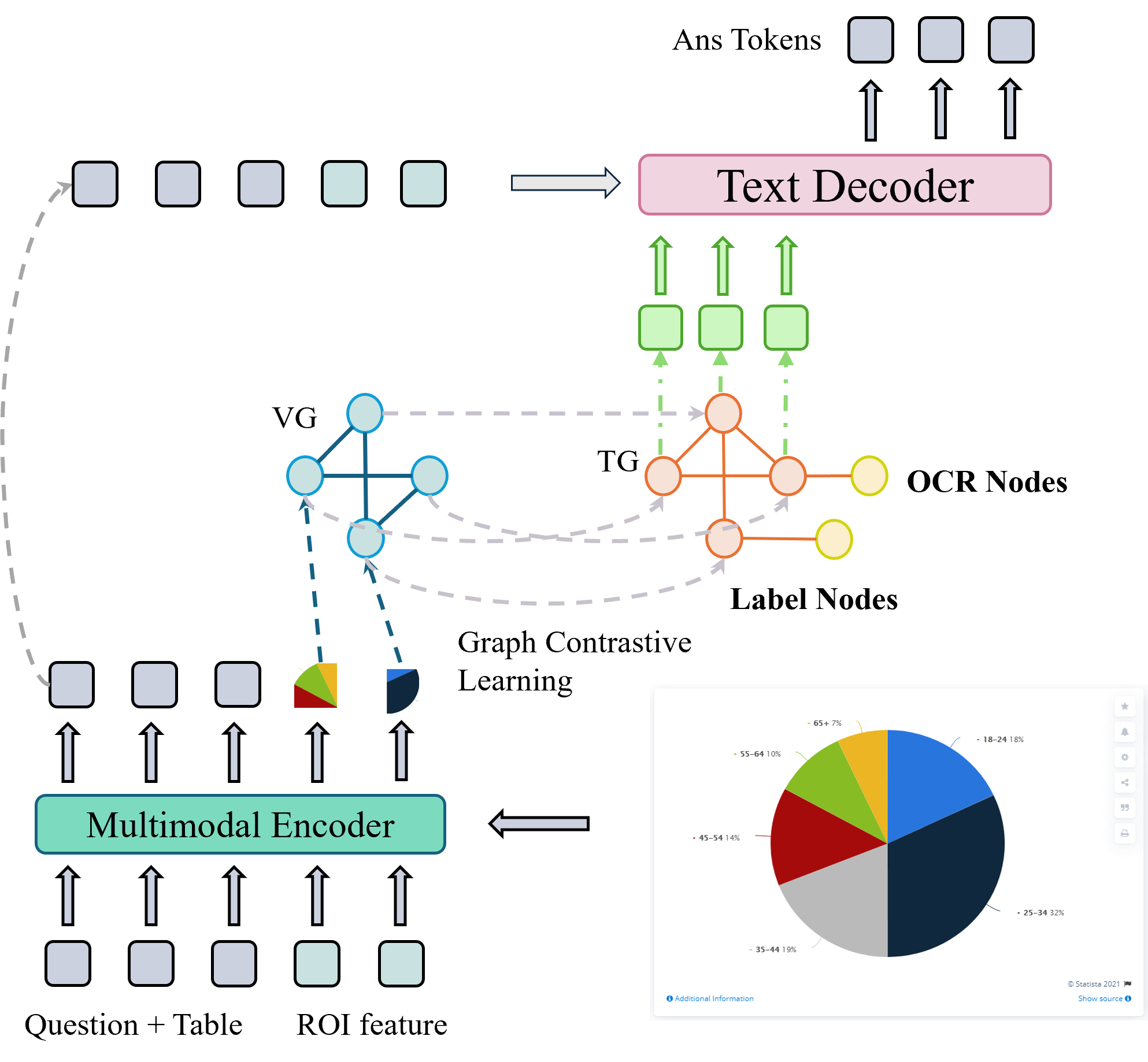
技术框架:整体框架包含以下几个主要模块:1) 图构建模块:分别构建视觉图和文本图,节点表示图表中的元素,边表示元素之间的关系。2) 图对比学习模块:通过对比学习策略,对齐视觉图和文本图的节点表示,使得不同模态的节点具有相似的表示。3) Transformer解码器:将对齐后的节点表示作为软提示输入到Transformer解码器中,用于生成答案。4) 思维链提示模块:设计定制的思维链提示,引导模型进行逐步推理,提高答案的准确性。
关键创新:本文的关键创新在于:1) 提出了联合多模态场景图框架,显式地建模图表元素之间的关系,从而更好地捕捉图表的结构和语义信息。2) 采用了图对比学习策略,对齐视觉图和文本图的节点表示,实现多模态信息的有效融合。3) 设计了定制的思维链提示,引导模型进行逐步推理,减少幻觉。
关键设计:在图构建模块中,可以使用不同的图神经网络(GNN)来学习节点表示,例如GCN、GAT等。在图对比学习模块中,可以使用不同的对比学习损失函数,例如InfoNCE损失。在Transformer解码器中,可以将对齐后的节点表示作为软提示,通过注意力机制与解码器的隐藏状态进行融合。思维链提示的设计需要根据具体的图表类型和问题类型进行调整,以引导模型进行合理的推理。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在ChartQA、OpenCQA和ChartX等基准测试中取得了显著的性能提升。例如,在ChartQA数据集上,该方法相较于现有最佳方法提升了X%。实验还验证了图对比学习和思维链提示的有效性,证明了该方法在处理复杂图表问答任务方面的优越性。
🎯 应用场景
该研究成果可应用于智能报表分析、数据可视化辅助、教育领域等。例如,可以帮助用户快速理解复杂的图表信息,自动生成分析报告,辅助决策。在教育领域,可以用于开发智能辅导系统,帮助学生理解图表数据,提高数据分析能力。未来,该技术有望进一步扩展到其他多模态数据分析场景,例如医学影像分析、社交媒体分析等。
📄 摘要(原文)
Chart question answering (ChartQA) is challenged by the heterogeneous composition of chart elements and the subtle data patterns they encode. This work introduces a novel joint multimodal scene graph framework that explicitly models the relationships among chart components and their underlying structures. The framework integrates both visual and textual graphs to capture structural and semantic characteristics, while a graph contrastive learning strategy aligns node representations across modalities enabling their seamless incorporation into a transformer decoder as soft prompts. Moreover, a set of tailored Chain of Thought (CoT) prompts is proposed to enhance multimodal large language models (MLLMs) in zero-s ot scenarios by mitigating hallucinations. Extensive evaluations on benchmarks including ChartQA, OpenCQA, and ChartX demonstrate significant performance improvements and validate the efficacy of the proposed approach.