Reasoning-Enhanced Self-Training for Long-Form Personalized Text Generation
作者: Alireza Salemi, Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, Tao Chen, Zhuowan Li, Michael Bendersky, Hamed Zamani
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-01-07
💡 一句话要点
提出REST-PG框架,通过推理增强的自训练提升长文本个性化生成效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化文本生成 长文本生成 推理增强 自训练 大型语言模型 强化学习 期望最大化
📋 核心要点
- 现有大型语言模型在个性化文本生成中难以有效利用用户偏好等上下文信息。
- REST-PG框架通过生成推理路径和自训练,提升模型在生成过程中的推理能力。
- 实验表明,REST-PG在LongLaMP基准测试中显著优于现有方法,平均性能提升14.5%。
📝 摘要(中文)
个性化文本生成要求大型语言模型(LLMs)具备独特的学习能力,从它们在标准训练中通常不会遇到的上下文中学习。一种鼓励LLMs更好地利用个性化上下文来生成更符合用户期望的输出的方法是,指示它们对用户过去的偏好、背景知识或写作风格进行推理。为了实现这一目标,我们提出了用于个性化文本生成的推理增强自训练(REST-PG)框架,该框架训练LLMs在响应生成过程中对个人数据进行推理。REST-PG首先生成推理路径来训练LLM的推理能力,然后采用期望最大化强化自训练,基于其自身的高奖励输出来迭代地训练LLM。我们在LongLaMP基准上评估REST-PG,该基准包含四个不同的个性化长文本生成任务。实验表明,REST-PG相对于最先进的基线方法取得了显著的改进,在该基准上平均相对性能提升了14.5%。
🔬 方法详解
问题定义:个性化文本生成任务需要模型根据用户的历史偏好、背景知识和写作风格等信息生成符合用户期望的长文本。现有的方法通常难以有效地利用这些个性化上下文信息,导致生成的文本与用户的实际需求不符。模型缺乏对用户信息的推理能力,无法准确捕捉用户的意图和偏好。
核心思路:REST-PG的核心思路是通过显式地训练模型进行推理,从而提升其利用个性化上下文信息的能力。该方法首先生成推理路径,引导模型学习如何从用户数据中提取相关信息并进行推理。然后,通过自训练的方式,让模型基于自身生成的高质量输出来不断提升性能。这种方法鼓励模型主动学习和利用个性化信息,从而生成更符合用户期望的文本。
技术框架:REST-PG框架包含两个主要阶段:推理路径生成阶段和期望最大化强化自训练阶段。在推理路径生成阶段,框架利用外部知识或规则生成一系列推理步骤,用于指导模型学习如何从用户数据中进行推理。在期望最大化强化自训练阶段,模型首先基于个性化上下文生成文本,然后根据奖励函数评估生成文本的质量。模型利用这些奖励信号进行强化学习,不断提升生成文本的质量。
关键创新:REST-PG的关键创新在于将推理能力融入到个性化文本生成过程中。通过显式地训练模型进行推理,该方法能够更好地利用个性化上下文信息,从而生成更符合用户期望的文本。与传统的端到端生成方法相比,REST-PG能够更好地控制生成过程,并提供更强的可解释性。
关键设计:REST-PG框架中的推理路径生成可以采用多种方法,例如基于知识图谱的推理或基于规则的推理。奖励函数的设计需要能够准确评估生成文本的质量,可以结合人工评估和自动评估指标。在强化学习过程中,可以采用不同的策略梯度算法,例如REINFORCE或PPO。具体的参数设置需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

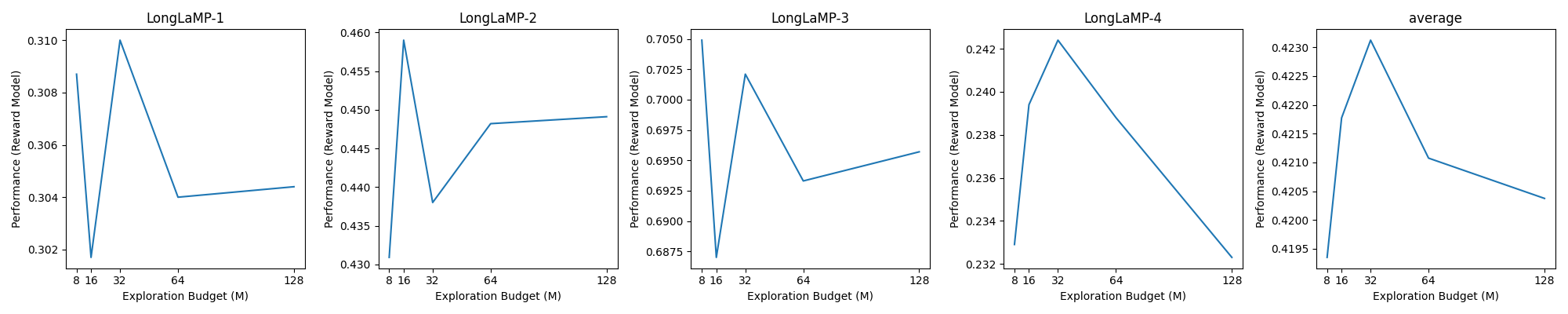
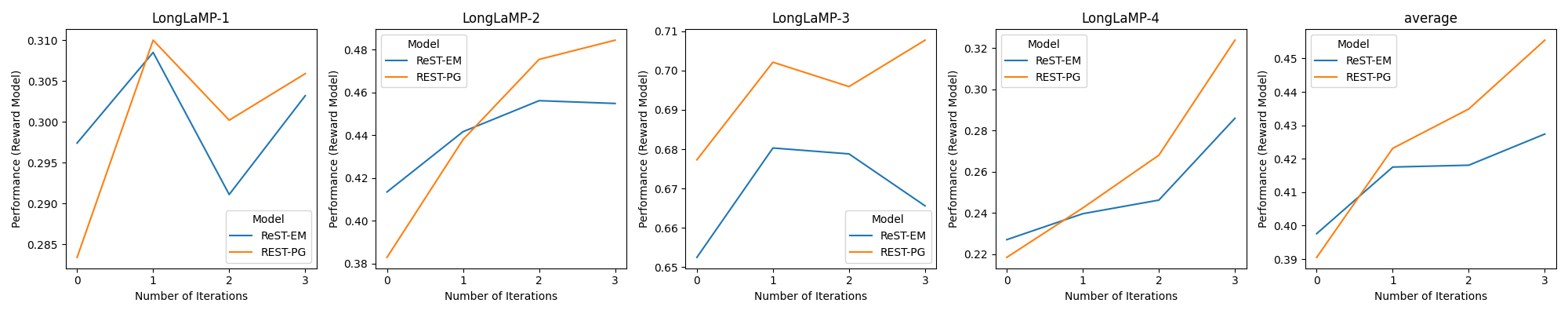
📊 实验亮点
实验结果表明,REST-PG在LongLaMP基准测试中取得了显著的改进,平均相对性能提升了14.5%。在不同的个性化长文本生成任务中,REST-PG均优于现有的最先进基线方法。这些结果表明,通过推理增强的自训练能够有效地提升个性化文本生成的效果。
🎯 应用场景
REST-PG框架可应用于多种个性化文本生成场景,例如个性化新闻推荐、个性化故事创作、个性化对话生成等。该方法能够提升生成文本的相关性、流畅性和个性化程度,从而改善用户体验。未来,该方法可以进一步扩展到其他模态的个性化生成任务,例如个性化图像生成和个性化音乐生成。
📄 摘要(原文)
Personalized text generation requires a unique ability of large language models (LLMs) to learn from context that they often do not encounter during their standard training. One way to encourage LLMs to better use personalized context for generating outputs that better align with the user's expectations is to instruct them to reason over the user's past preferences, background knowledge, or writing style. To achieve this, we propose Reasoning-Enhanced Self-Training for Personalized Text Generation (REST-PG), a framework that trains LLMs to reason over personal data during response generation. REST-PG first generates reasoning paths to train the LLM's reasoning abilities and then employs Expectation-Maximization Reinforced Self-Training to iteratively train the LLM based on its own high-reward outputs. We evaluate REST-PG on the LongLaMP benchmark, consisting of four diverse personalized long-form text generation tasks. Our experiments demonstrate that REST-PG achieves significant improvements over state-of-the-art baselines, with an average relative performance gain of 14.5% on the benchmark.