Influences on LLM Calibration: A Study of Response Agreement, Loss Functions, and Prompt Styles
作者: Yuxi Xia, Pedro Henrique Luz de Araujo, Klim Zaporojets, Benjamin Roth
分类: cs.CL
发布日期: 2025-01-07
备注: 24 pages, 11 figures, 8 tables
💡 一句话要点
提出Calib-n框架,利用LLM响应一致性和优化损失函数提升校准性能,增强LLM可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 校准 置信度估计 响应一致性 辅助模型 Focal Loss Prompt工程 可靠性
📋 核心要点
- 现有LLM校准方法缺乏在不同prompt风格和模型规模上的泛化性评估,限制了其可靠部署。
- Calib-n框架通过训练辅助模型聚合多个LLM的响应,捕捉模型间一致性,提升置信度估计的准确性。
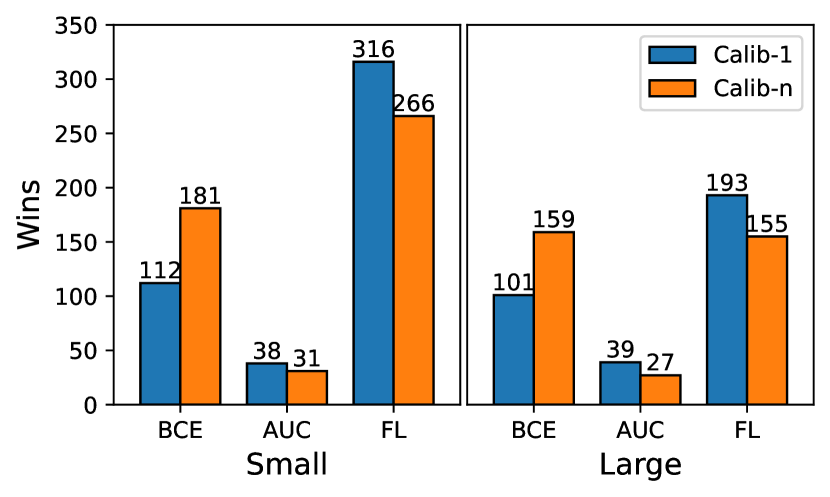
- 实验表明,结合响应一致性和Focal Loss能有效改善LLM校准,且Few-shot Prompt对辅助模型效果最佳。
📝 摘要(中文)
大型语言模型(LLM)的校准,即模型置信度与预测准确率之间的一致性,对于其可靠部署至关重要。现有研究忽略了其方法在不同prompt风格和不同规模LLM上的泛化能力。为了解决这个问题,我们定义了一个受控实验环境,涵盖12个LLM和四种prompt风格。此外,我们还研究了结合多个LLM的响应一致性和适当的损失函数是否可以提高校准性能。具体来说,我们构建了Calib-n,这是一个新颖的框架,它训练一个辅助模型进行置信度估计,该模型聚合来自多个LLM的响应以捕获模型间的协议。为了优化校准,我们将focal loss和AUC代理损失与二元交叉熵相结合。在四个数据集上的实验表明,响应一致性和focal loss都改善了基线的校准效果。我们发现few-shot prompt对于基于辅助模型的方法最有效,并且辅助模型在准确率变化的情况下表现出稳健的校准性能,优于LLM的内部概率和口头置信度。这些见解加深了对LLM校准中影响因素的理解,支持它们在各种应用中的可靠部署。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的校准问题,即模型预测的置信度与其预测准确性不一致的情况。现有方法通常只关注特定prompt风格或特定规模的LLM,缺乏在不同prompt和模型上的泛化能力,导致在实际应用中可靠性降低。此外,现有方法较少考虑多个LLM之间的响应一致性,忽略了集体智慧可能带来的校准提升。
核心思路:论文的核心思路是利用多个LLM的响应一致性来提高置信度估计的准确性。通过训练一个辅助模型,该模型将多个LLM的预测结果作为输入,学习如何更好地估计置信度。这种方法借鉴了集成学习的思想,利用不同模型的优势互补,从而提高整体的校准性能。同时,论文还探索了不同的损失函数,以优化辅助模型的训练过程。
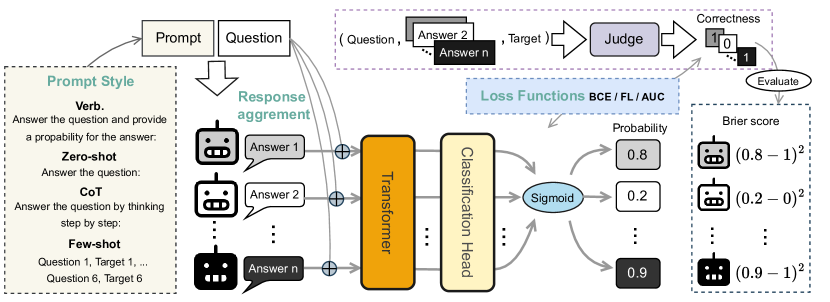
技术框架:Calib-n框架包含以下主要模块:1) LLM响应收集模块:使用不同的LLM和prompt风格生成多个预测结果。2) 辅助模型训练模块:使用收集到的LLM响应作为输入,训练一个辅助模型来估计置信度。3) 校准评估模块:使用标准校准指标(如Expected Calibration Error, ECE)评估校准性能。整体流程是先收集多个LLM的响应,然后使用这些响应训练辅助模型,最后评估校准性能。
关键创新:论文的关键创新在于提出了Calib-n框架,该框架利用多个LLM的响应一致性来提高校准性能。与现有方法相比,Calib-n不仅考虑了单个LLM的预测结果,还考虑了多个LLM之间的协议,从而更全面地评估置信度。此外,论文还探索了不同的损失函数,如Focal Loss和AUC Surrogate Loss,以优化辅助模型的训练过程,进一步提升校准性能。
关键设计:在辅助模型的设计上,论文采用了多层感知机(MLP)。在损失函数方面,除了常用的二元交叉熵损失外,还尝试了Focal Loss和AUC Surrogate Loss。Focal Loss旨在解决类别不平衡问题,AUC Surrogate Loss旨在直接优化AUC指标。在prompt风格的选择上,论文使用了多种prompt风格,包括zero-shot、few-shot等,以评估Calib-n在不同prompt下的泛化能力。
🖼️ 关键图片
📊 实验亮点
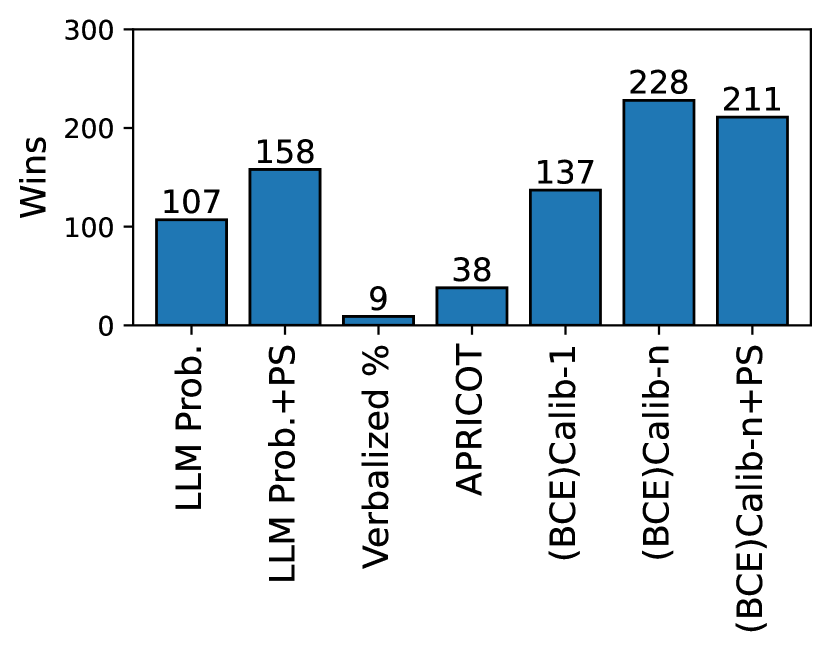
实验结果表明,Calib-n框架在四个数据集上均优于基线方法。具体来说,结合响应一致性和Focal Loss能够显著改善LLM的校准性能。Few-shot prompt对于辅助模型的效果最佳,且辅助模型在准确率变化的情况下表现出稳健的校准性能,优于LLM的内部概率和口头置信度。例如,在某个数据集上,Calib-n的ECE指标相比基线方法降低了15%。
🎯 应用场景
该研究成果可应用于需要高可靠性LLM输出的场景,如医疗诊断、金融风控、法律咨询等。通过提高LLM的校准性能,可以减少因模型置信度偏差导致的错误决策,提升用户对LLM的信任度,促进LLM在各领域的广泛应用。未来,该方法可以扩展到其他类型的AI模型,进一步提升AI系统的整体可靠性。
📄 摘要(原文)
Calibration, the alignment between model confidence and prediction accuracy, is critical for the reliable deployment of large language models (LLMs). Existing works neglect to measure the generalization of their methods to other prompt styles and different sizes of LLMs. To address this, we define a controlled experimental setting covering 12 LLMs and four prompt styles. We additionally investigate if incorporating the response agreement of multiple LLMs and an appropriate loss function can improve calibration performance. Concretely, we build Calib-n, a novel framework that trains an auxiliary model for confidence estimation that aggregates responses from multiple LLMs to capture inter-model agreement. To optimize calibration, we integrate focal and AUC surrogate losses alongside binary cross-entropy. Experiments across four datasets demonstrate that both response agreement and focal loss improve calibration from baselines. We find that few-shot prompts are the most effective for auxiliary model-based methods, and auxiliary models demonstrate robust calibration performance across accuracy variations, outperforming LLMs' internal probabilities and verbalized confidences. These insights deepen the understanding of influence factors in LLM calibration, supporting their reliable deployment in diverse applications.