Not all tokens are created equal: Perplexity Attention Weighted Networks for AI generated text detection
作者: Pablo Miralles-González, Javier Huertas-Tato, Alejandro Martín, David Camacho
分类: cs.CL, cs.AI
发布日期: 2025-01-07 (更新: 2025-07-14)
💡 一句话要点
提出Perplexity Attention Weighted Network (PAWN)用于提升AI生成文本的检测性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成文本检测 注意力机制 Perplexity 大型语言模型 零样本学习 鲁棒性 跨语言检测
📋 核心要点
- 现有AI生成文本检测方法在未见领域或未知LLM上表现不佳,zero-shot方法效果有限,无法充分利用LLM的token分布信息。
- PAWN通过注意力机制加权不同token的预测难度,利用LLM的隐藏状态和位置信息,更有效地聚合token分布特征。
- 实验表明,PAWN在分布内性能优于微调LM,且泛化能力更强,对对抗攻击更鲁棒,并具备跨语言检测能力。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展显著提高了它们生成连贯且上下文相关的文本的能力,但也引发了对AI生成内容滥用的担忧,因此检测此类内容至关重要。然而,这项任务仍然具有挑战性,尤其是在未见过的领域或使用不熟悉的LLM时。利用LLM的下一个token分布输出提供了一种理论上很有吸引力的检测方法,因为它封装了模型在各种语料库上进行大量预训练的见解。尽管前景广阔,但尝试操作这些输出的zero-shot方法并未取得成功。我们假设问题之一在于它们使用平均值来聚合token的下一个token分布指标,而某些token自然更容易或更难预测,应该被赋予不同的权重。基于此,我们提出了Perplexity Attention Weighted Network(PAWN),它使用LLM的最后一个隐藏状态和位置来加权基于序列长度上的下一个token分布指标的一系列特征的总和。虽然不是zero-shot,但我们的方法允许我们将最后一个隐藏状态和下一个token分布指标缓存在磁盘上,从而大大降低了训练资源需求。PAWN在分布内表现出与最强的基线(微调的LM)相比具有竞争力的甚至更好的性能,且可训练参数仅为它们的一小部分。我们的模型也能更好地泛化到未见过的领域和源模型,并且决策边界在分布偏移上的变化更小。它也更鲁棒,可以抵抗对抗性攻击,并且如果backbone具有多语言能力,则可以很好地泛化到监督训练中未见过的语言,其中LLaMA3-1B在使用九种语言进行交叉验证时,平均宏平均F1得分达到81.46%。
🔬 方法详解
问题定义:现有AI生成文本检测方法,特别是zero-shot方法,难以有效利用LLM的下一个token分布信息进行检测,主要痛点在于简单地平均token的预测概率,忽略了不同token预测难度的差异,导致检测精度不高,泛化能力差。
核心思路:核心思路是引入注意力机制,根据每个token的预测难度(通过perplexity衡量)动态调整其在检测过程中的权重。更容易预测的token权重较低,更难预测的token权重较高,从而更准确地捕捉AI生成文本的特征。
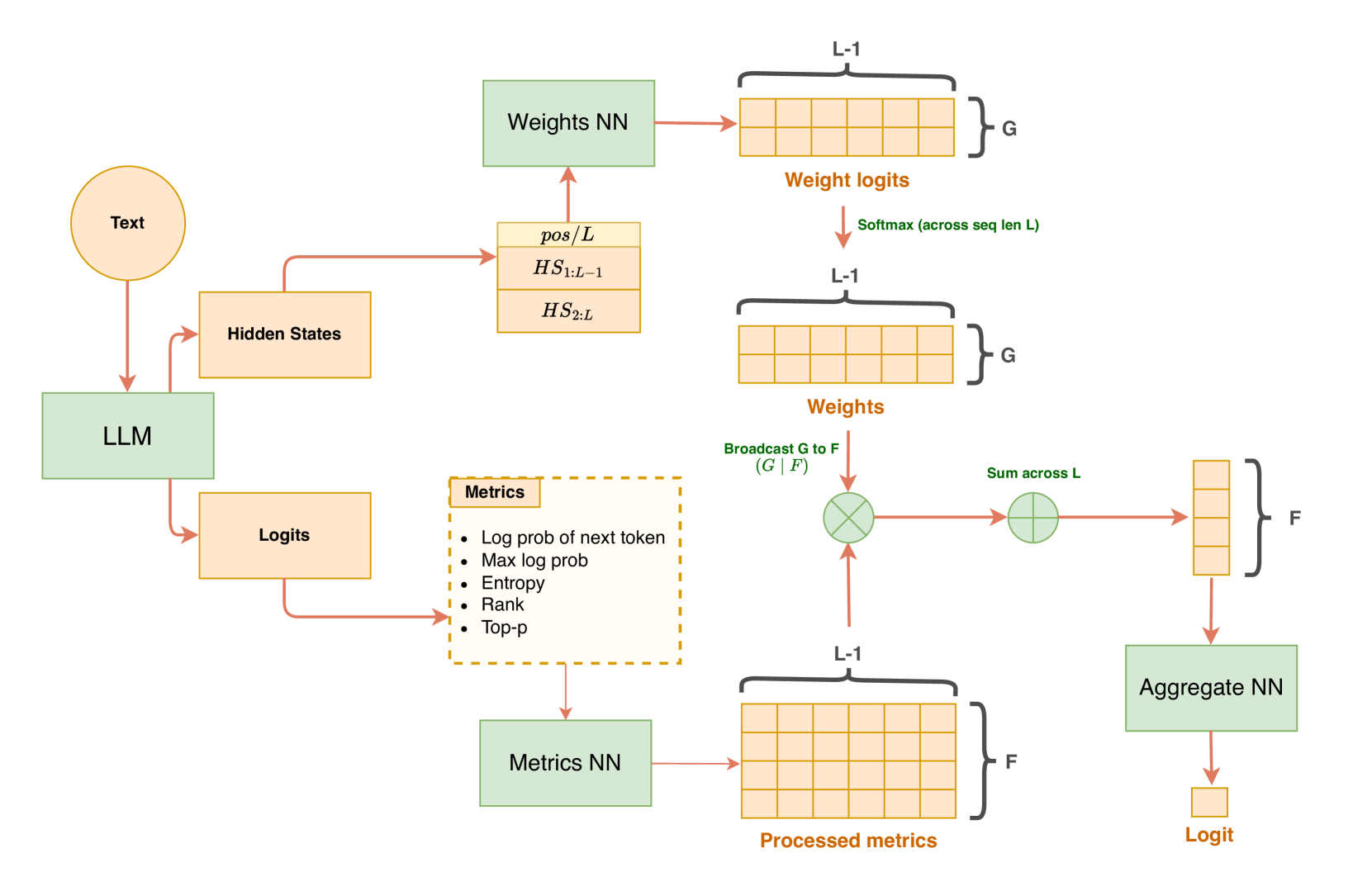
技术框架:PAWN模型的整体框架如下:1. 输入文本序列到LLM中,获取每个token的最后一个隐藏状态和下一个token的概率分布。2. 基于下一个token的概率分布计算每个token的perplexity。3. 使用LLM的最后一个隐藏状态和位置信息作为query,perplexity作为value,通过注意力机制计算每个token的权重。4. 将perplexity加权后的token分布特征进行聚合,输入到分类器中进行AI生成文本的判别。
关键创新:关键创新在于使用注意力机制对token的下一个token分布指标进行加权,解决了现有方法中简单平均的问题。通过LLM的隐藏状态和位置信息作为query,perplexity作为value,动态学习每个token的重要性,从而更有效地利用LLM的预测信息。
关键设计:关键设计包括:1. 使用perplexity作为衡量token预测难度的指标。2. 使用LLM的最后一个隐藏状态和位置信息作为注意力机制的query,从而更好地捕捉token的上下文信息。3. 将最后一个隐藏状态和下一个token分布指标缓存在磁盘上,从而降低训练资源需求。4. 使用简单的分类器(如线性层)进行最终的判别,减少模型的复杂度。
🖼️ 关键图片

📊 实验亮点
PAWN模型在分布内表现出与微调LM相当甚至更好的性能,同时显著减少了可训练参数。在未见过的领域和源模型上,PAWN展现出更强的泛化能力和更小的决策边界变化。此外,PAWN对对抗攻击更鲁棒,并且在多语言环境下表现出良好的跨语言检测能力,LLaMA3-1B在九种语言交叉验证中达到81.46%的平均宏平均F1得分。
🎯 应用场景
该研究成果可应用于内容安全领域,用于检测和过滤AI生成的虚假新闻、恶意评论等。有助于维护网络空间的健康生态,防止AI技术被滥用。未来可扩展到其他生成式AI内容的检测,如图像、音频等。
📄 摘要(原文)
The rapid advancement in large language models (LLMs) has significantly enhanced their ability to generate coherent and contextually relevant text, raising concerns about the misuse of AI-generated content and making it critical to detect it. However, the task remains challenging, particularly in unseen domains or with unfamiliar LLMs. Leveraging LLM next-token distribution outputs offers a theoretically appealing approach for detection, as they encapsulate insights from the models' extensive pre-training on diverse corpora. Despite its promise, zero-shot methods that attempt to operationalize these outputs have met with limited success. We hypothesize that one of the problems is that they use the mean to aggregate next-token distribution metrics across tokens, when some tokens are naturally easier or harder to predict and should be weighted differently. Based on this idea, we propose the Perplexity Attention Weighted Network (PAWN), which uses the last hidden states of the LLM and positions to weight the sum of a series of features based on metrics from the next-token distribution across the sequence length. Although not zero-shot, our method allows us to cache the last hidden states and next-token distribution metrics on disk, greatly reducing the training resource requirements. PAWN shows competitive and even better performance in-distribution than the strongest baselines (fine-tuned LMs) with a fraction of their trainable parameters. Our model also generalizes better to unseen domains and source models, with smaller variability in the decision boundary across distribution shifts. It is also more robust to adversarial attacks, and if the backbone has multilingual capabilities, it presents decent generalization to languages not seen during supervised training, with LLaMA3-1B reaching a mean macro-averaged F1 score of 81.46% in cross-validation with nine languages.