AlphaPO: Reward Shape Matters for LLM Alignment
作者: Aman Gupta, Shao Tang, Qingquan Song, Sirou Zhu, Jiwoo Hong, Ankan Saha, Viral Gupta, Noah Lee, Eunki Kim, Siyu Zhu, Parag Agrawal, Natesh Pillai, S. Sathiya Keerthi
分类: cs.CL
发布日期: 2025-01-07 (更新: 2025-05-30)
备注: 26 pages, 16 figures. Accepted to ICML 2025
💡 一句话要点
AlphaPO:通过调整奖励函数形状优化LLM对齐,提升指令遵循能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型对齐 直接偏好优化 奖励函数形状 强化学习 人类反馈 似然位移 AlphaPO
📋 核心要点
- 现有直接对齐算法(DAA)在优化LLM时,常出现似然位移问题,导致模型生成偏好响应的概率降低。
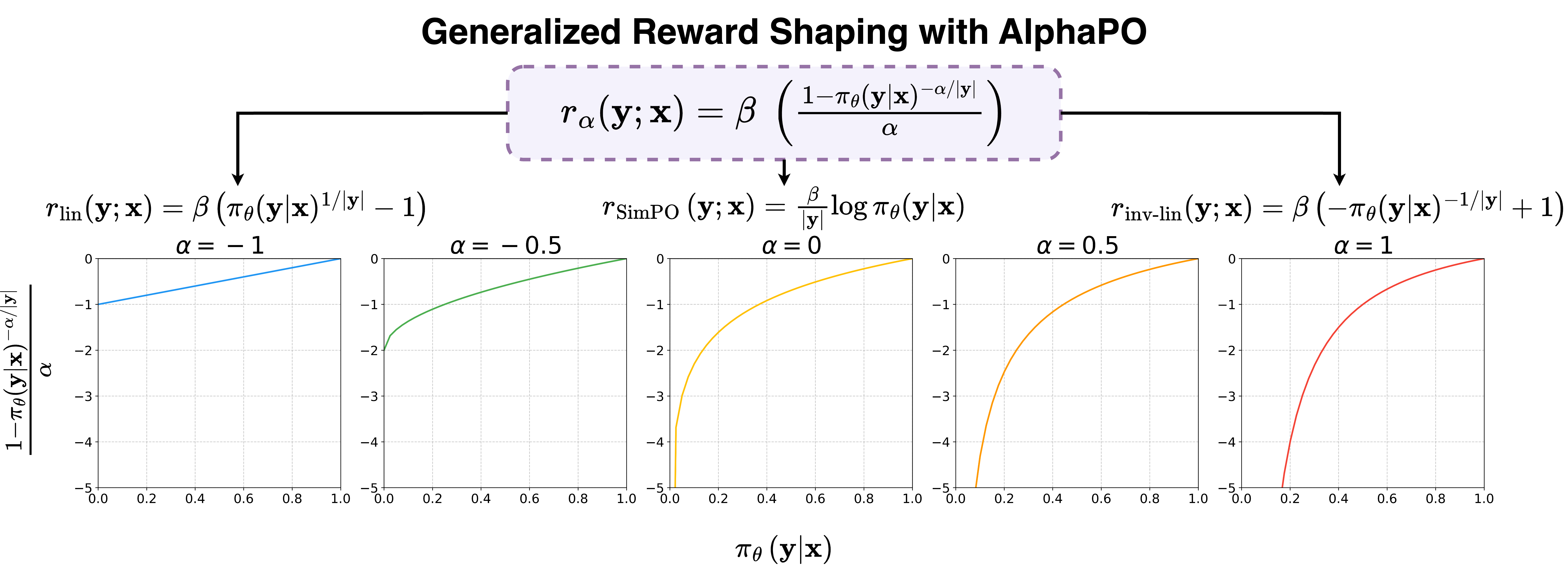
- AlphaPO通过引入α参数,精细控制奖励函数的形状,从而有效缓解似然位移和过度优化问题。
- 实验表明,AlphaPO在Mistral-7B和Llama3-8B模型上,相比SimPO和DPO,对齐性能分别提升7%-10%和15%-50%。
📝 摘要(中文)
通过人类反馈的强化学习(RLHF)及其变体在使大型语言模型(LLM)有效对齐以遵循指令和反映人类价值观方面取得了巨大进展。最近,直接对齐算法(DAA)开始出现,它跳过了RLHF的奖励建模阶段,直接将奖励描述为被学习策略的函数。一些流行的DAA例子包括直接偏好优化(DPO)和简单偏好优化(SimPO)。这些方法通常会受到似然位移的影响,即首选响应的概率经常被不希望地降低。在本文中,我们认为,对于DAA,奖励(函数)的形状很重要。我们引入了AlphaPO,一种新的DAA方法,它利用一个α参数来帮助改变奖励函数的形状,使其超出标准的log奖励。AlphaPO有助于保持对似然位移和过度优化的细粒度控制。与表现最佳的DAA之一SimPO相比,AlphaPO在Mistral-7B和Llama3-8B的instruct版本上,对齐性能提高了约7%到10%,相对于DPO,在相同的模型上提高了15%到50%。所提出的分析和结果突出了奖励形状的重要性,以及如何系统地改变它来影响训练动态,并提高对齐性能。
🔬 方法详解
问题定义:现有直接对齐算法(DAA),如DPO和SimPO,在优化大型语言模型(LLM)以符合人类偏好时,存在“似然位移”问题。这意味着模型在学习过程中,可能会降低原本应该被优先选择的响应的概率,从而影响模型的整体性能和对齐效果。现有方法缺乏对奖励函数形状的有效控制,导致难以平衡优化过程中的探索与利用。
核心思路:AlphaPO的核心思路是通过引入一个可调节的参数α,来改变奖励函数的形状。通过调整α值,可以更灵活地控制奖励函数对不同响应的区分度,从而更好地平衡优化过程中的探索与利用,并缓解似然位移问题。这种方法允许对奖励函数进行更细粒度的调整,使其更适应特定的任务和数据集。
技术框架:AlphaPO属于直接对齐算法(DAA)的范畴,它直接将奖励函数定义为策略的函数,避免了RLHF中单独训练奖励模型的步骤。其整体流程包括:1)收集人类偏好数据;2)使用偏好数据训练LLM,目标是优化AlphaPO定义的奖励函数;3)通过调整α参数,控制奖励函数的形状,从而影响训练动态和对齐性能。
关键创新:AlphaPO的关键创新在于引入了α参数,用于控制奖励函数的形状。与传统的log奖励函数相比,AlphaPO允许更灵活地调整奖励函数对不同响应的区分度,从而更好地平衡优化过程中的探索与利用,并缓解似然位移问题。这种方法提供了一种系统地改变奖励函数形状的途径,从而影响训练动态并提高对齐性能。
关键设计:AlphaPO的关键设计在于α参数的选择和调整。α参数决定了奖励函数的形状,不同的α值会导致不同的训练动态和对齐性能。论文可能探讨了如何选择合适的α值,以及如何根据训练过程中的反馈动态调整α值。此外,损失函数的设计也至关重要,它需要能够有效地利用人类偏好数据,并引导模型学习到符合人类价值观的策略。
🖼️ 关键图片
📊 实验亮点
AlphaPO在Mistral-7B和Llama3-8B的instruct版本上进行了实验,结果表明,相对于SimPO,AlphaPO的对齐性能提高了约7%到10%,相对于DPO,在相同的模型上提高了15%到50%。这些结果表明,通过调整奖励函数的形状,可以显著提高LLM的对齐性能。
🎯 应用场景
AlphaPO可应用于各种需要大型语言模型与人类价值观对齐的场景,例如智能助手、聊天机器人、内容生成等。通过优化模型对人类偏好的理解和遵循,可以提升用户体验,减少有害或不当内容的生成,并促进人工智能技术的安全可靠发展。该研究为未来LLM对齐算法的设计提供了新的思路。
📄 摘要(原文)
Reinforcement Learning with Human Feedback (RLHF) and its variants have made huge strides toward the effective alignment of large language models (LLMs) to follow instructions and reflect human values. More recently, Direct Alignment Algorithms (DAAs) have emerged in which the reward modeling stage of RLHF is skipped by characterizing the reward directly as a function of the policy being learned. Some popular examples of DAAs include Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO). These methods often suffer from likelihood displacement, a phenomenon by which the probabilities of preferred responses are often reduced undesirably. In this paper, we argue that, for DAAs the reward (function) shape matters. We introduce \textbf{AlphaPO}, a new DAA method that leverages an $α$-parameter to help change the shape of the reward function beyond the standard log reward. AlphaPO helps maintain fine-grained control over likelihood displacement and over-optimization. Compared to SimPO, one of the best performing DAAs, AlphaPO leads to about 7\% to 10\% relative improvement in alignment performance for the instruct versions of Mistral-7B and Llama3-8B while achieving 15\% to 50\% relative improvement over DPO on the same models. The analysis and results presented highlight the importance of the reward shape and how one can systematically change it to affect training dynamics, as well as improve alignment performance.