SLAM: Towards Efficient Multilingual Reasoning via Selective Language Alignment
作者: Yuchun Fan, Yongyu Mu, Yilin Wang, Lei Huang, Junhao Ruan, Bei Li, Tong Xiao, Shujian Huang, Xiaocheng Feng, Jingbo Zhu
分类: cs.CL, cs.AI
发布日期: 2025-01-07
备注: Accepted by COLING 2025 (Oral)
💡 一句话要点
提出SLAM:通过选择性语言对齐实现高效的多语言推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言推理 语言模型 选择性微调 语言对齐 高效训练
📋 核心要点
- 现有方法在多语言推理中采用全参数两阶段训练,导致计算资源消耗大和灾难性遗忘。
- SLAM方法通过选择性地对齐和微调负责多语言处理的底层网络层,提升效率。
- 实验表明,SLAM仅微调少量参数,在多语言推理任务上优于现有基线,并显著减少训练时间。
📝 摘要(中文)
尽管大型语言模型(LLMs)在英语推理任务中取得了显著的进步,但这些模型在多语言推理方面仍然面临挑战。最近的研究采用全参数和两阶段训练范式,首先训练模型理解非英语问题,然后再进行推理。然而,这种方法存在计算资源消耗大和灾难性遗忘的问题。根本原因是,在第一阶段,为了增强多语言理解,过度调整了大量不相关的层和参数。基于语言的表征学习主要在较低层进行的发现,我们提出了一种高效的多语言推理对齐方法SLAM,该方法精确地识别并微调负责处理多语言的层。实验结果表明,我们的方法SLAM仅调整了6个层的前馈子层,包括7B和13B LLM中所有参数的6.5-8%,在10种语言中实现了优于所有强基线的平均性能。同时,SLAM仅涉及一个训练阶段,与两阶段方法相比,训练时间减少了4.1-11.9倍。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在多语言推理任务中效率低下的问题。现有方法通常采用全参数微调的两阶段训练策略,即先让模型学习理解多种语言,再进行推理。这种方法计算成本高昂,且容易发生灾难性遗忘,因为在第一阶段微调了大量与推理无关的参数。
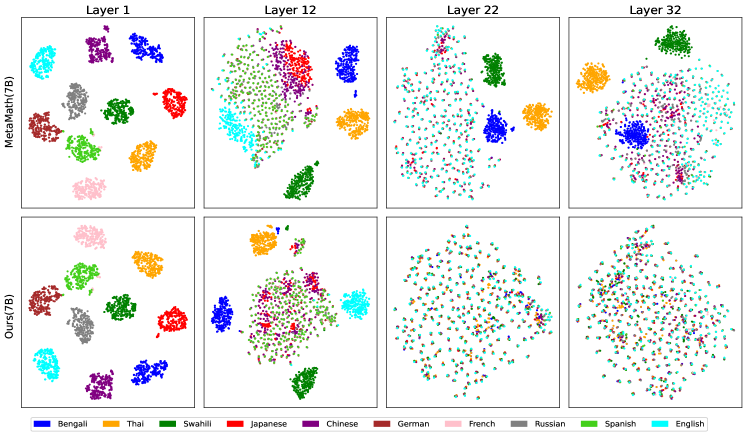
核心思路:论文的核心思路是,并非所有网络层都对多语言理解至关重要。作者观察到,语言表征学习主要发生在较低层的网络中。因此,只需要选择性地对齐和微调这些负责多语言处理的底层网络层,就可以在保证性能的同时,显著提高训练效率,并减少灾难性遗忘的风险。
技术框架:SLAM方法的核心在于识别并选择性地微调LLM中负责多语言处理的层。具体流程包括:1) 分析LLM各层对不同语言的表征能力;2) 确定负责多语言理解的关键层(通常是较低层);3) 仅微调这些关键层中的前馈子层,保持其他层参数不变。整个训练过程采用单阶段训练,避免了两阶段训练带来的额外开销和潜在的灾难性遗忘。
关键创新:SLAM的关键创新在于提出了选择性语言对齐的思想,即只针对LLM中负责多语言处理的关键层进行微调。这与传统的全参数微调方法形成鲜明对比,大大降低了计算成本,并提高了训练效率。此外,单阶段训练也避免了传统两阶段训练的缺点。
关键设计:SLAM的关键设计包括:1) 通过实验分析确定LLM中负责多语言处理的关键层;2) 只微调这些关键层中的前馈子层,因为作者发现这些子层对语言表征学习至关重要;3) 使用标准的反向传播算法进行微调;4) 实验中,作者在7B和13B的LLM上进行了实验,微调了6个层的前馈子层,约占总参数的6.5-8%。
🖼️ 关键图片

📊 实验亮点
SLAM方法在10种语言的多语言推理任务上取得了优于所有强基线的平均性能。该方法仅微调了LLM中6.5-8%的参数,与两阶段方法相比,训练时间减少了4.1-11.9倍。这些结果表明,SLAM是一种高效且有效的多语言推理对齐方法。
🎯 应用场景
SLAM方法可应用于各种需要多语言推理能力的场景,例如多语言问答系统、跨语言信息检索、多语言机器翻译等。该方法能够显著降低训练成本,提高模型在资源受限环境下的部署能力,并促进更广泛的多语言人工智能应用。
📄 摘要(原文)
Despite the significant improvements achieved by large language models (LLMs) in English reasoning tasks, these models continue to struggle with multilingual reasoning. Recent studies leverage a full-parameter and two-stage training paradigm to teach models to first understand non-English questions and then reason. However, this method suffers from both substantial computational resource computing and catastrophic forgetting. The fundamental cause is that, with the primary goal of enhancing multilingual comprehension, an excessive number of irrelevant layers and parameters are tuned during the first stage. Given our findings that the representation learning of languages is merely conducted in lower-level layers, we propose an efficient multilingual reasoning alignment approach that precisely identifies and fine-tunes the layers responsible for handling multilingualism. Experimental results show that our method, SLAM, only tunes 6 layers' feed-forward sub-layers including 6.5-8% of all parameters within 7B and 13B LLMs, achieving superior average performance than all strong baselines across 10 languages. Meanwhile, SLAM only involves one training stage, reducing training time by 4.1-11.9 compared to the two-stage method.