A Diversity-Enhanced Knowledge Distillation Model for Practical Math Word Problem Solving
作者: Yi Zhang, Guangyou Zhou, Zhiwen Xie, Jinjin Ma, Jimmy Xiangji Huang
分类: cs.CL, cs.AI
发布日期: 2025-01-07
💡 一句话要点
提出一种多样性增强的知识蒸馏模型,用于解决实际数学应用题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数学应用题求解 知识蒸馏 多样性学习 Seq2Seq模型 条件变分自编码器
📋 核心要点
- 现有Seq2Seq模型及其变体在生成多样化解题方程方面存在局限性,影响了模型在不同场景下的泛化能力。
- 论文提出DivKD模型,通过自适应多样性蒸馏,使学生模型学习教师模型的多样化解题知识。
- 实验结果表明,该方法在多个MWP数据集上取得了更高的答案准确率,并保持了较高的效率。
📝 摘要(中文)
数学应用题(MWP)求解是自然语言处理中的一项关键任务,近年来引起了广泛的研究兴趣。最近的许多研究严重依赖Seq2Seq模型及其扩展(例如Seq2Tree和Graph2Tree)来生成数学方程式。虽然这些模型有效,但它们难以生成多样但对等的解题方程式,从而限制了它们在各种数学问题场景中的泛化能力。在本文中,我们提出了一种新颖的、多样性增强的知识蒸馏(DivKD)模型,用于解决实际的MWP问题。我们的方法提出了一种自适应多样性蒸馏方法,其中学生模型通过选择性地从教师模型传递高质量知识来学习多样化的方程式。此外,我们设计了一个多样性先验增强的学生模型,通过结合条件变分自编码器来更好地捕获方程式的多样性分布。在四个MWP基准数据集上的大量实验表明,我们的方法比强大的基线方法实现了更高的答案准确率,同时保持了实际应用的高效率。
🔬 方法详解
问题定义:论文旨在解决数学应用题(MWP)求解中,现有Seq2Seq模型及其扩展(如Seq2Tree和Graph2Tree)在生成多样化解题方程方面的不足。这些模型虽然在一定程度上能够解决MWP问题,但难以生成多种合理的解题思路,导致泛化能力受限。
核心思路:论文的核心思路是通过知识蒸馏,让学生模型学习教师模型的多样化解题知识。具体来说,通过自适应地选择教师模型中高质量且具有多样性的知识进行传递,从而提升学生模型生成多样化解题方程的能力。同时,引入多样性先验,引导学生模型学习解题方程的多样性分布。
技术框架:DivKD模型包含一个教师模型和一个学生模型。教师模型可以是预训练的Seq2Seq模型或其变体。学生模型在教师模型的指导下进行训练。整体流程包括:1) 教师模型生成多个候选解题方程;2) 通过自适应多样性蒸馏方法,选择高质量且具有多样性的候选解题方程;3) 学生模型学习被选择的解题方程;4) 通过多样性先验增强学生模型,使其更好地捕获解题方程的多样性分布。
关键创新:论文的关键创新在于提出了自适应多样性蒸馏方法和多样性先验增强的学生模型。自适应多样性蒸馏方法能够选择性地传递教师模型中高质量且具有多样性的知识,避免了传统知识蒸馏方法中可能存在的负迁移问题。多样性先验增强的学生模型能够更好地捕获解题方程的多样性分布,从而提升学生模型生成多样化解题方程的能力。
关键设计:自适应多样性蒸馏方法通过计算候选解题方程的质量和多样性得分,并根据得分选择合适的解题方程进行知识传递。多样性先验增强的学生模型通过引入条件变分自编码器(CVAE)来学习解题方程的多样性分布。CVAE的条件输入可以是问题描述或部分解题步骤。损失函数包括知识蒸馏损失、CVAE的重构损失和KL散度损失。
🖼️ 关键图片


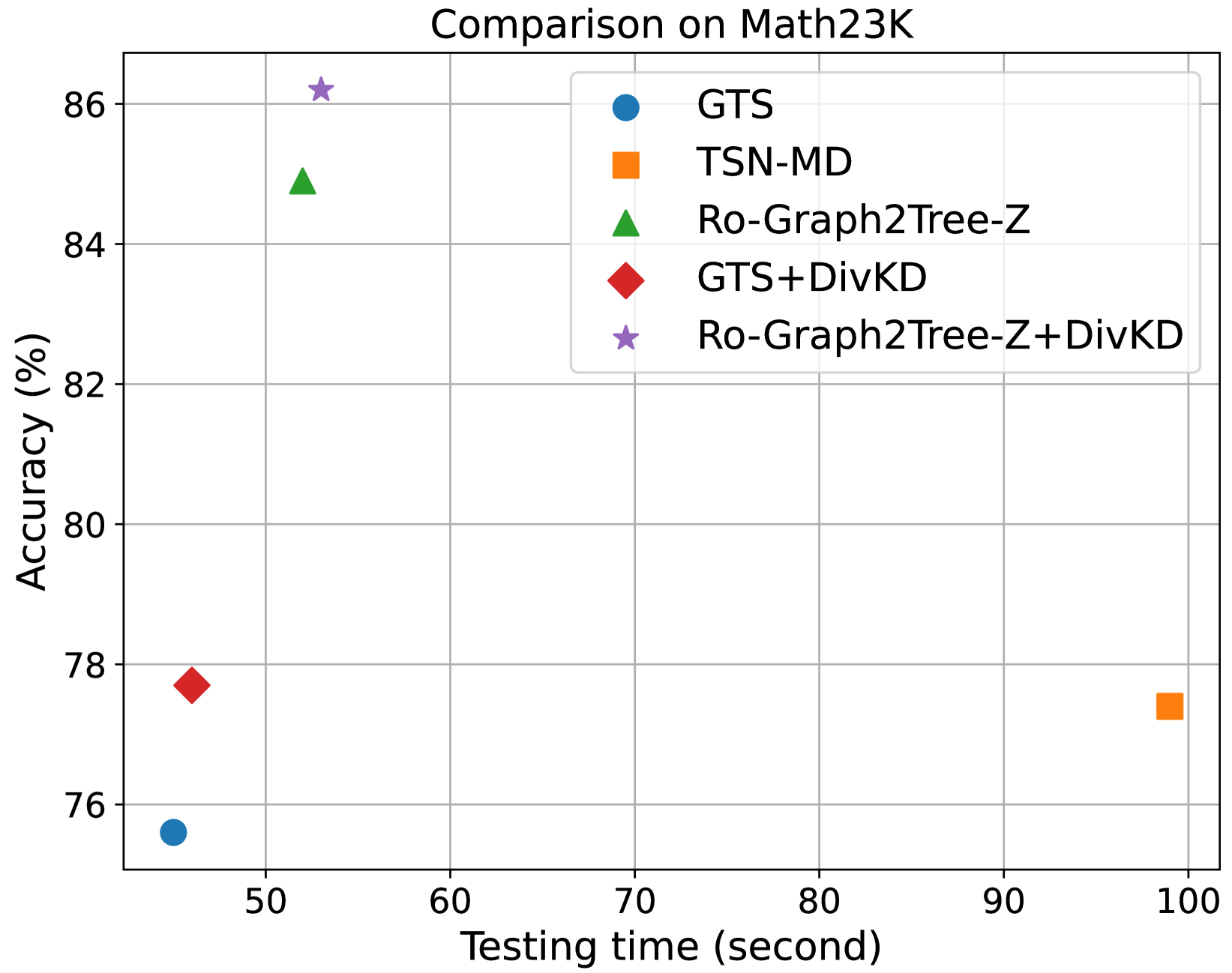
📊 实验亮点
实验结果表明,DivKD模型在四个MWP基准数据集上均取得了显著的性能提升。例如,在Dataset A上,DivKD模型的答案准确率比最强的基线模型提高了2-3个百分点。同时,DivKD模型保持了较高的效率,适用于实际应用场景。消融实验验证了自适应多样性蒸馏方法和多样性先验增强学生模型的有效性。
🎯 应用场景
该研究成果可应用于智能教育系统、自动解题机器人等领域。通过提升数学应用题求解的准确性和多样性,可以为学生提供更个性化的学习辅导,减轻教师的批改负担,并促进人工智能在教育领域的应用。此外,该方法还可以推广到其他需要生成多样化结果的任务中,例如文本摘要、机器翻译等。
📄 摘要(原文)
Math Word Problem (MWP) solving is a critical task in natural language processing, has garnered significant research interest in recent years. Various recent studies heavily rely on Seq2Seq models and their extensions (e.g., Seq2Tree and Graph2Tree) to generate mathematical equations. While effective, these models struggle to generate diverse but counterpart solution equations, limiting their generalization across various math problem scenarios. In this paper, we introduce a novel Diversity-enhanced Knowledge Distillation (DivKD) model for practical MWP solving. Our approach proposes an adaptive diversity distillation method, in which a student model learns diverse equations by selectively transferring high-quality knowledge from a teacher model. Additionally, we design a diversity prior-enhanced student model to better capture the diversity distribution of equations by incorporating a conditional variational auto-encoder. Extensive experiments on {four} MWP benchmark datasets demonstrate that our approach achieves higher answer accuracy than strong baselines while maintaining high efficiency for practical applications.