LlaMADRS: Prompting Large Language Models for Interview-Based Depression Assessment
作者: Gaoussou Youssouf Kebe, Jeffrey M. Girard, Einat Liebenthal, Justin Baker, Fernando De la Torre, Louis-Philippe Morency
分类: cs.HC, cs.CL
发布日期: 2025-01-07
💡 一句话要点
LlaMADRS:利用大语言模型进行访谈式抑郁症评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 抑郁症评估 零样本学习 临床访谈 心理健康
📋 核心要点
- 现有抑郁症评估方法耗时且依赖专家,限制了其可及性,尤其是在资源匮乏地区。
- LlaMADRS利用大语言模型和零样本提示,自动分析访谈记录,评估抑郁症严重程度。
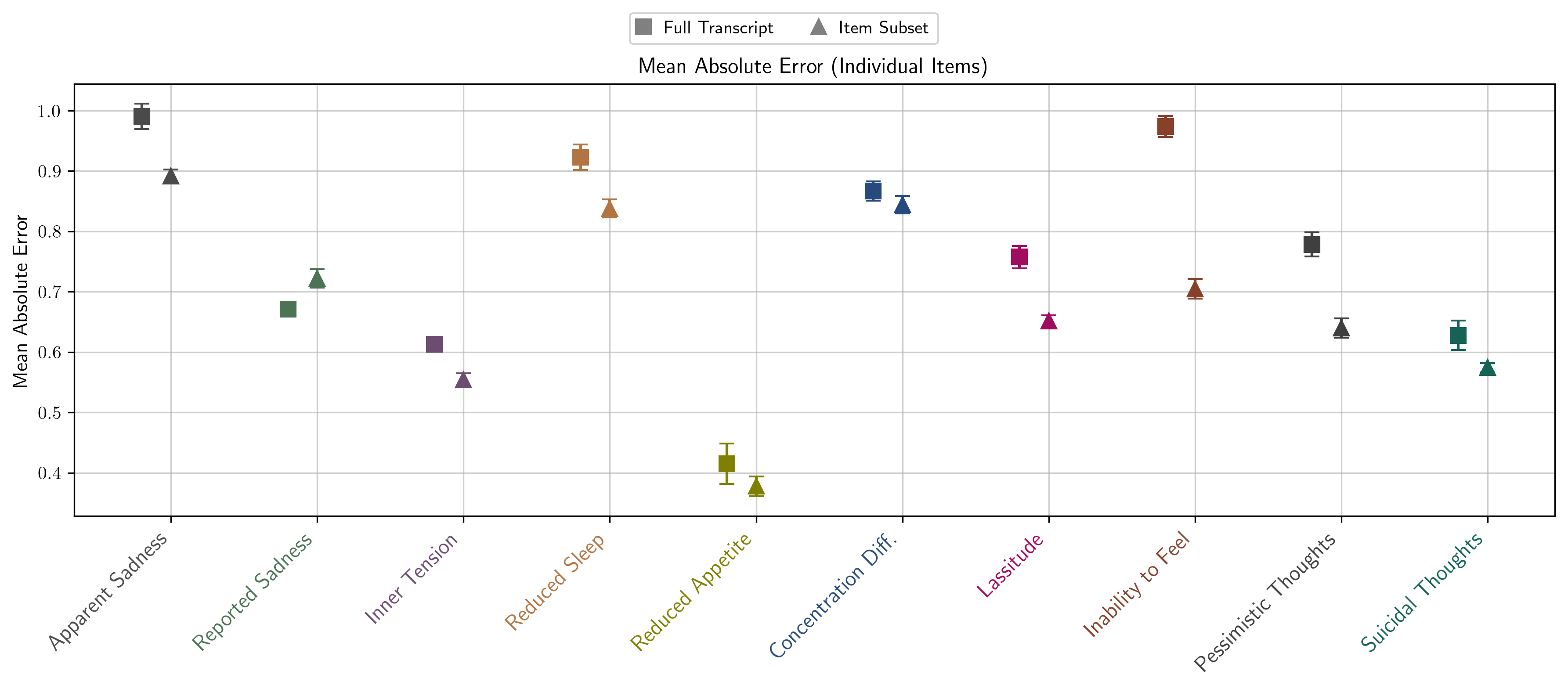
- 实验表明,LlaMADRS与临床医生评估高度相关,Qwen 2.5-72b模型性能接近人类水平。
📝 摘要(中文)
本研究提出了LlaMADRS,这是一个新颖的框架,利用开源大型语言模型(LLM)来自动评估抑郁症的严重程度,采用蒙哥马利-艾斯伯格抑郁评定量表(MADRS)。我们采用零样本提示策略,通过精心设计的提示来指导模型解释临床访谈记录并进行评分。我们的方法在来自Context-Adaptive Multimodal Informatics (CAMI)数据集的236个真实访谈中进行了测试,结果表明与临床医生的评估具有很强的相关性。Qwen 2.5-72b模型在大多数MADRS项目上实现了接近人类水平的一致性,类内相关系数(ICC)与人类评估者之间的系数非常接近。我们对模型在不同MADRS项目上的性能进行了全面分析,突出了优点和当前的局限性。我们的研究结果表明,通过适当的提示,LLM可以作为心理健康评估的有效工具,从而有可能提高资源有限环境中的可及性。然而,仍然存在挑战,尤其是在评估依赖于非语言线索的症状时,这突显了未来工作中采用多模态方法的必要性。
🔬 方法详解
问题定义:论文旨在解决抑郁症评估过程中人工评估耗时、成本高昂且依赖专业人员的问题。现有方法难以大规模应用,尤其是在资源有限的地区。此外,传统的评估方法可能受到评估者主观性的影响,导致评估结果的偏差。
核心思路:论文的核心思路是利用大型语言模型(LLM)的自然语言理解和生成能力,通过设计合适的提示(Prompting)来引导LLM自动分析临床访谈记录,并根据蒙哥马利-艾斯伯格抑郁评定量表(MADRS)进行评分。这种方法旨在减少人工干预,提高评估效率和客观性。
技术框架:LlaMADRS框架主要包含以下几个阶段:1) 数据准备:收集临床访谈录音,并将其转录为文本。2) 提示设计:根据MADRS量表的各项指标,设计合适的提示,引导LLM理解访谈内容并进行评分。3) 模型推理:将访谈文本和提示输入到LLM中,获得模型生成的MADRS评分。4) 结果评估:将模型生成的评分与临床医生的评分进行比较,评估模型的性能。
关键创新:该论文的关键创新在于将大型语言模型应用于抑郁症评估领域,并提出了一种基于零样本提示的自动化评估方法。与传统的基于机器学习的分类或回归方法不同,LlaMADRS无需大量的标注数据进行训练,而是通过精心设计的提示来激发LLM的内在知识和推理能力。
关键设计:论文的关键设计包括:1) 提示工程:设计清晰、明确的提示,引导LLM关注访谈文本中的关键信息,并根据MADRS量表的标准进行评分。提示的设计需要考虑到MADRS量表的各项指标的定义和评估标准。2) 模型选择:选择具有较强自然语言理解和生成能力的大型语言模型,例如Qwen 2.5-72b。3) 评估指标:采用类内相关系数(ICC)等指标来评估模型生成的评分与临床医生评分之间的一致性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LlaMADRS框架在抑郁症评估任务上表现出色。Qwen 2.5-72b模型在大多数MADRS项目上实现了接近人类水平的一致性,类内相关系数(ICC)与人类评估者之间的系数非常接近。这表明,通过适当的提示,LLM可以作为心理健康评估的有效工具。
🎯 应用场景
LlaMADRS具有广泛的应用前景,可用于大规模抑郁症筛查、临床诊断辅助、远程心理健康服务等领域。尤其是在资源匮乏地区,该方法可以有效提高抑郁症评估的可及性,降低评估成本。未来,结合多模态数据(如语音、面部表情等),LlaMADRS有望实现更准确、更全面的抑郁症评估。
📄 摘要(原文)
This study introduces LlaMADRS, a novel framework leveraging open-source Large Language Models (LLMs) to automate depression severity assessment using the Montgomery-Asberg Depression Rating Scale (MADRS). We employ a zero-shot prompting strategy with carefully designed cues to guide the model in interpreting and scoring transcribed clinical interviews. Our approach, tested on 236 real-world interviews from the Context-Adaptive Multimodal Informatics (CAMI) dataset, demonstrates strong correlations with clinician assessments. The Qwen 2.5--72b model achieves near-human level agreement across most MADRS items, with Intraclass Correlation Coefficients (ICC) closely approaching those between human raters. We provide a comprehensive analysis of model performance across different MADRS items, highlighting strengths and current limitations. Our findings suggest that LLMs, with appropriate prompting, can serve as efficient tools for mental health assessment, potentially increasing accessibility in resource-limited settings. However, challenges remain, particularly in assessing symptoms that rely on non-verbal cues, underscoring the need for multimodal approaches in future work.