Can LLMs Ask Good Questions?
作者: Yueheng Zhang, Xiaoyuan Liu, Yiyou Sun, Atheer Alharbi, Hend Alzahrani, Tianneng Shi, Basel Alomair, Dawn Song
分类: cs.CL, cs.AI
发布日期: 2025-01-07 (更新: 2025-06-17)
💡 一句话要点
评估大型语言模型生成问题的质量,揭示其与人类提问的差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 问题生成 质量评估 上下文覆盖 定位偏差
📋 核心要点
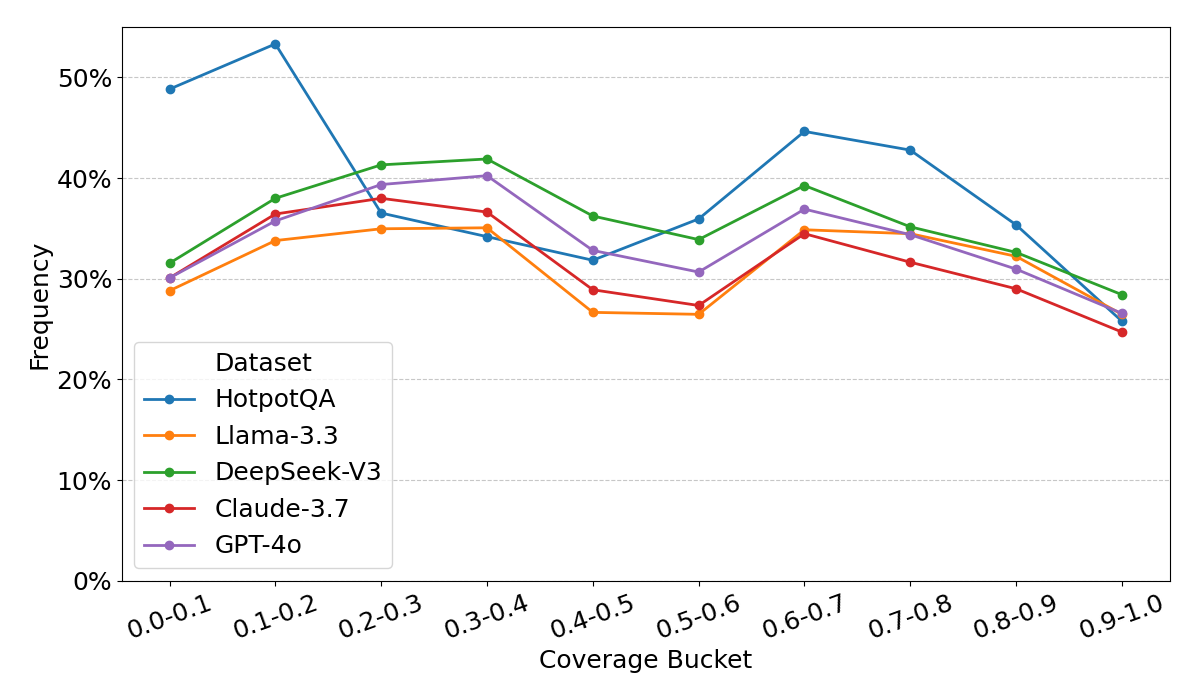
- 现有问答任务中,模型生成的答案常存在定位偏差,未能充分覆盖上下文信息。
- 该研究对比分析了LLM与人类生成问题的差异,从多个维度评估LLM提问能力。
- 实验结果表明,LLM生成的问题更注重上下文覆盖,且答案更倾向于长描述型。
📝 摘要(中文)
本文评估了大型语言模型(LLMs)在给定上下文后生成问题的能力,并将其与人类编写的问题在六个维度上进行了比较:问题类型、问题长度、上下文覆盖率、可回答性、不常见性和所需答案长度。研究涵盖了两个开源和两个专有的最先进模型。结果表明,LLM生成的问题倾向于需要更长的描述性答案,并且表现出更均匀的上下文关注度,这与QA任务中常见的定位偏差形成对比。这些发现为了解LLM生成问题的独特特征提供了见解,并为未来关于问题质量和下游应用的研究提供了信息。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)生成问题的质量,并将其与人类生成的问题进行对比分析。现有方法在问答任务中存在定位偏差,即模型倾向于关注上下文中的特定位置,而忽略其他重要信息。此外,对于LLM生成问题的质量评估缺乏系统性的研究。
核心思路:论文的核心思路是通过多维度对比LLM和人类生成的问题,从而揭示LLM提问的特点和优势。通过分析问题类型、问题长度、上下文覆盖率、可回答性、不常见性和所需答案长度等指标,全面评估LLM的提问能力。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择具有代表性的LLM模型(包括开源和专有模型);2) 构建包含上下文和对应问题的测试数据集;3) 使用LLM模型基于上下文生成问题;4) 从六个维度对LLM生成的问题和人类生成的问题进行对比分析;5) 统计分析实验结果,得出结论。
关键创新:该研究的关键创新在于:1) 系统性地评估了LLM生成问题的质量,填补了该领域的研究空白;2) 提出了多个维度来衡量问题的质量,为后续研究提供了参考;3) 揭示了LLM生成问题与人类生成问题的差异,为改进LLM的提问能力提供了方向。
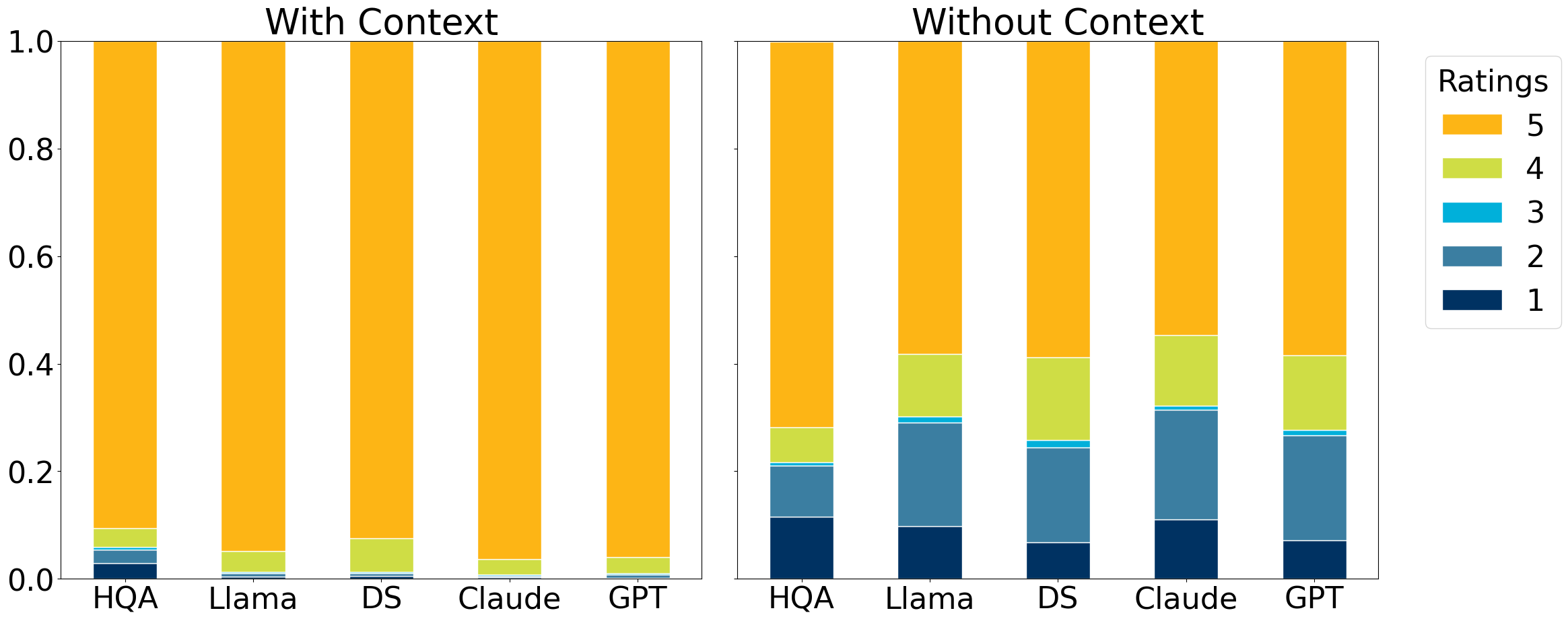
关键设计:研究中,上下文覆盖率通过计算问题与上下文中每个句子的相关性来衡量。可回答性通过人工评估或使用问答模型来判断。不常见性通过计算问题中单词的TF-IDF值来衡量。此外,研究还考虑了问题类型(如开放式问题、封闭式问题)和答案长度等因素,以更全面地评估问题的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM生成的问题倾向于需要更长的描述性答案,并且表现出更均匀的上下文关注度。与人类生成的问题相比,LLM生成的问题更少出现定位偏差,能够更全面地覆盖上下文信息。此外,LLM生成的问题在不常见性方面也表现出一定的优势。
🎯 应用场景
该研究成果可应用于智能教育、智能客服、信息检索等领域。通过提升LLM的提问能力,可以实现更高效的信息获取和知识挖掘。例如,在智能教育中,LLM可以生成引导性问题,帮助学生更深入地理解知识;在智能客服中,LLM可以生成针对用户问题的追问,从而更准确地理解用户需求。
📄 摘要(原文)
We evaluate questions generated by large language models (LLMs) from context, comparing them to human-authored questions across six dimensions: question type, question length, context coverage, answerability, uncommonness, and required answer length. Our study spans two open-source and two proprietary state-of-the-art models. Results reveal that LLM-generated questions tend to demand longer descriptive answers and exhibit more evenly distributed context focus, in contrast to the positional bias often seen in QA tasks. These findings provide insights into the distinctive characteristics of LLM-generated questions and inform future work on question quality and downstream applications.