MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
作者: Yannis Katsis, Sara Rosenthal, Kshitij Fadnis, Chulaka Gunasekara, Young-Suk Lee, Lucian Popa, Vraj Shah, Huaiyu Zhu, Danish Contractor, Marina Danilevsky
分类: cs.CL, cs.AI
发布日期: 2025-01-07
🔗 代码/项目: GITHUB
💡 一句话要点
MTRAG:用于评估检索增强生成系统的多轮对话基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多轮对话 基准测试 大型语言模型 自然语言处理
📋 核心要点
- 现有RAG系统在多轮对话中面临挑战,尤其是在处理上下文依赖、无法回答和跨领域问题时。
- MTRAG基准旨在提供一个更贴近真实场景的评估平台,包含人工生成的多轮对话,覆盖多个领域。
- 实验表明,即使是最先进的RAG系统在MTRAG上表现不佳,突显了提升检索和生成能力的需求。
📝 摘要(中文)
检索增强生成(RAG)最近已成为大型语言模型(LLM)的一项非常流行的任务。在多轮RAG对话中评估它们,即系统需要在先前对话的上下文中生成对问题的响应,这是一项重要但经常被忽视的任务,并且存在若干额外的挑战。我们提出了MTRAG:一个端到端的人工生成的多轮RAG基准,它反映了跨多个维度的若干真实世界属性,用于评估完整的RAG流程。MTRAG包含110个对话,平均每个对话7.7轮,跨越四个领域,总共842个任务。我们还探索了通过合成数据和LLM-as-a-Judge评估的自动化路径。我们的人工和自动评估表明,即使是最先进的LLM RAG系统在MTRAG上也表现不佳。我们证明了需要强大的检索和生成系统,这些系统可以处理后面的轮次、无法回答的问题、非独立问题和多个领域。MTRAG可在https://github.com/ibm/mt-rag-benchmark获得。
🔬 方法详解
问题定义:论文旨在解决现有RAG系统在多轮对话场景下的评估问题。现有的评估方法通常侧重于单轮问答或使用合成数据,无法充分反映真实世界多轮对话的复杂性,例如上下文依赖、无法回答的问题以及领域切换等。这导致评估结果与实际应用效果存在差距。
核心思路:论文的核心思路是构建一个高质量的人工生成的多轮对话数据集,该数据集覆盖多个领域,包含各种类型的对话场景,例如需要上下文信息的提问、无法回答的问题以及领域切换等。通过在这个数据集上评估RAG系统,可以更全面地了解其在真实世界多轮对话场景下的性能。
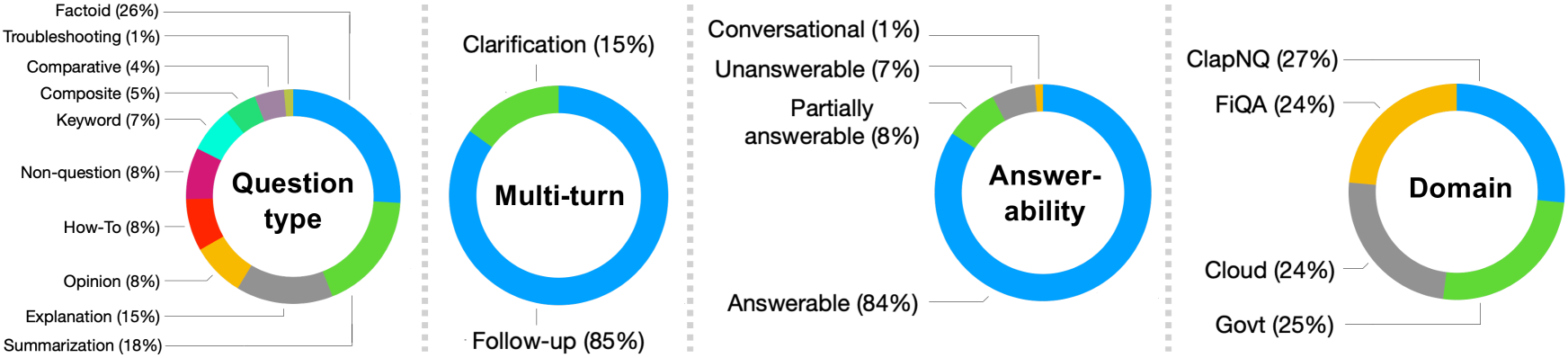
技术框架:MTRAG基准包含以下几个关键组成部分:1) 人工生成的多轮对话数据,涵盖四个领域,共110个对话,平均每个对话7.7轮;2) 评估指标,用于衡量RAG系统在多轮对话中的性能,包括检索准确率、生成质量等;3) 基于LLM的自动评估方法,用于降低人工评估的成本。整体流程是:给定一个多轮对话历史,RAG系统需要根据对话历史和外部知识库生成对当前问题的回答,然后使用评估指标或自动评估方法来评估生成的回答的质量。
关键创新:MTRAG的关键创新在于其数据集的真实性和多样性。与以往的合成数据集相比,MTRAG的数据由人工生成,更贴近真实世界的对话场景。此外,MTRAG还覆盖了多个领域,包含各种类型的对话场景,例如需要上下文信息的提问、无法回答的问题以及领域切换等,这使得MTRAG能够更全面地评估RAG系统在多轮对话中的性能。
关键设计:MTRAG数据集包含110个对话,平均每个对话7.7轮,跨越四个领域。数据集的设计考虑了多种因素,例如对话的长度、问题的类型、领域的覆盖范围等。为了保证数据的质量,论文作者采用了严格的数据标注和审核流程。此外,论文还探索了基于LLM的自动评估方法,例如使用LLM来判断生成的回答是否相关、准确和流畅。具体参数设置和损失函数等技术细节未在摘要中详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
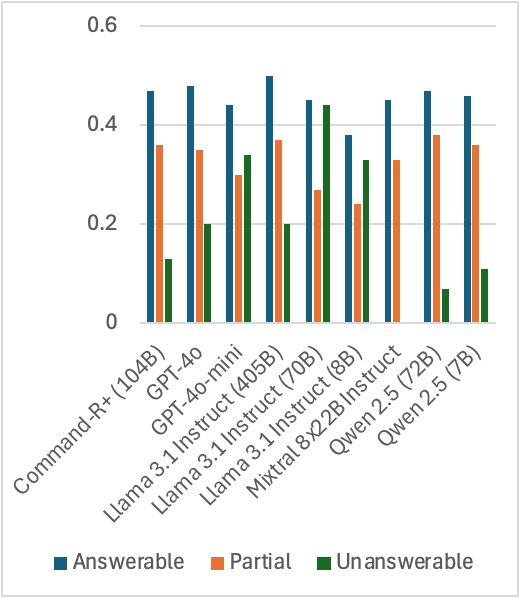
实验结果表明,即使是最先进的LLM RAG系统在MTRAG上也表现不佳,这突显了现有RAG系统在处理多轮对话时的不足。该结果表明,需要开发更强大的检索和生成系统,以更好地处理上下文依赖、无法回答的问题和领域切换等挑战。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。
🎯 应用场景
MTRAG基准可用于评估和改进各种RAG系统在多轮对话场景下的性能。该基准可以帮助研究人员和开发人员更好地了解RAG系统的优缺点,并开发出更强大的RAG系统,从而提升智能客服、聊天机器人等应用的性能和用户体验。未来,该基准可以扩展到更多领域,并包含更多类型的对话场景。
📄 摘要(原文)
Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.