ADePT: Adaptive Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning
作者: Pengwei Tang, Xiaolin Hu, Yong Liu
分类: cs.CL
发布日期: 2025-01-06 (更新: 2025-12-21)
备注: Published at ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出ADePT,通过自适应分解Prompt调整,提升参数高效微调性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 Prompt Tuning 自适应偏移 预训练语言模型 自然语言处理
📋 核心要点
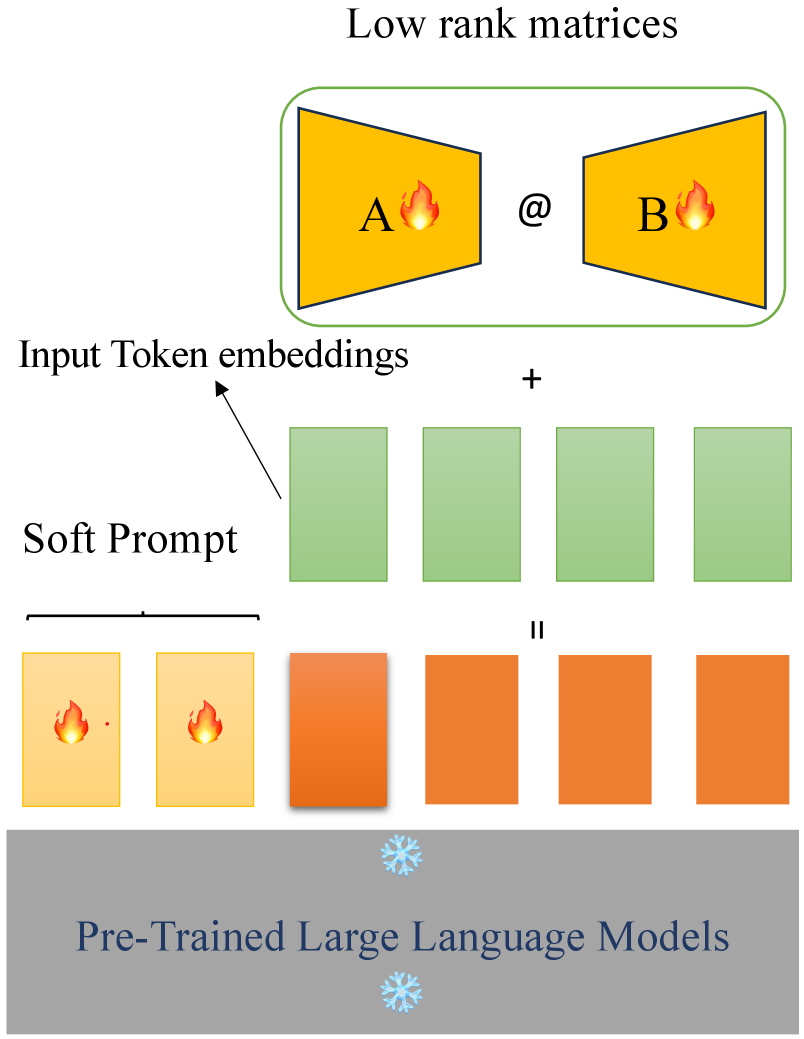
- DePT基于位置的token embedding偏移限制了模型在不同输入上的泛化能力,且共享偏移导致次优。
- ADePT使用token共享前馈神经网络学习每个token的embedding偏移,实现自适应偏移,优化token embedding。
- 实验表明,ADePT在多个NLP任务和PLM上超越其他参数高效微调方法,甚至优于全微调。
📝 摘要(中文)
Prompt Tuning (PT) 通过优化少量软虚拟tokens,将预训练大语言模型(PLMs)适配到下游任务。Decomposed Prompt Tuning (DePT) 通过将软prompt分解为更短的软prompt和一对低秩矩阵,展示了更优的适配能力。低秩矩阵的乘积被添加到输入token embeddings以进行偏移。此外,由于软prompt更短,DePT比PT实现了更快的推理速度。然而,本文发现DePT基于位置的token embedding偏移限制了其在不同模型输入上的泛化能力,并且许多token embeddings共享相同的偏移导致了次优解。为了解决这些问题,我们引入了Adaptive Decomposed Prompt Tuning (ADePT),它由一个短软prompt和一个浅层的token共享前馈神经网络组成。ADePT利用token共享前馈神经网络来学习每个token的embedding偏移,从而实现根据模型输入而变化的自适应embedding偏移,并更好地优化token embedding偏移。这使得ADePT能够在不需要更多推理时间或额外可训练参数的情况下,实现优于vanilla PT及其变体的适配性能。在跨越23个自然语言处理任务和4个不同规模的典型PLM的综合实验中,ADePT始终优于其他领先的参数高效微调方法,甚至在某些情况下优于全微调。我们还对ADePT进行了理论分析。代码可在https://github.com/HungerPWAY/ADePT获取。
🔬 方法详解
问题定义:论文旨在解决现有Decomposed Prompt Tuning (DePT)方法中存在的泛化能力不足和优化次优的问题。DePT虽然通过分解prompt并使用低秩矩阵进行embedding偏移,在一定程度上提升了性能,但其基于位置的偏移方式无法很好地适应不同的输入,且多个token共享相同的偏移限制了模型的表达能力。
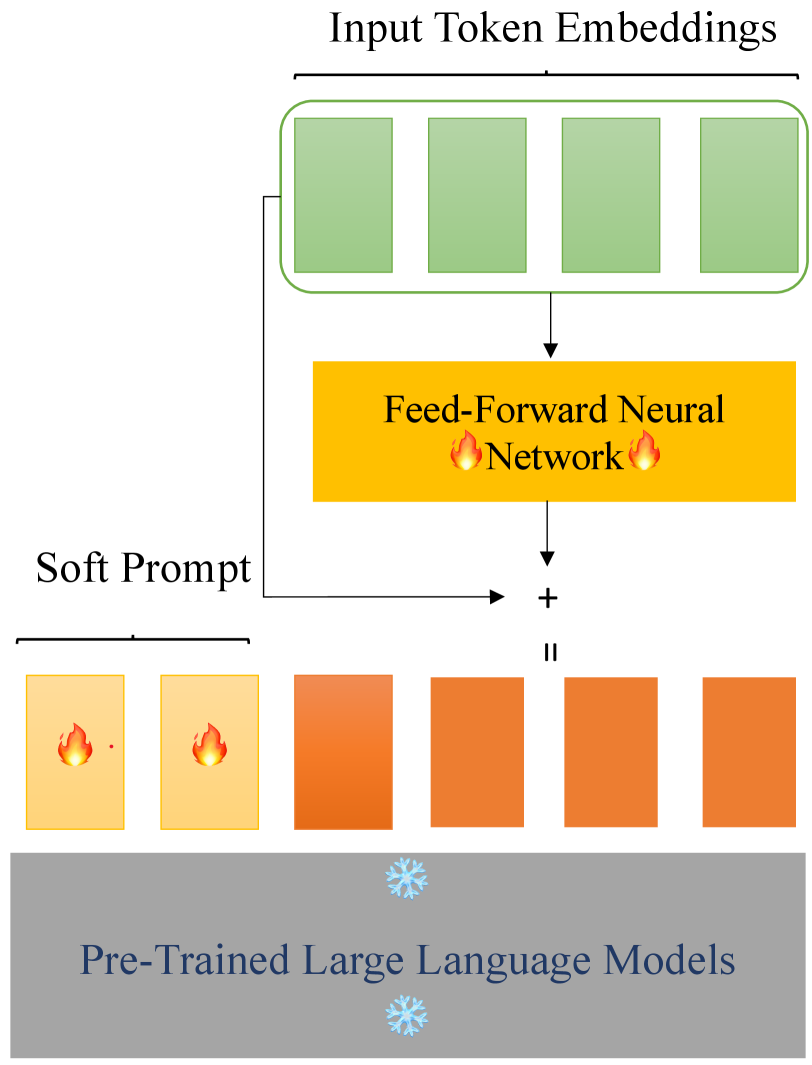
核心思路:论文的核心思路是引入自适应的embedding偏移,使得每个token的偏移能够根据输入动态调整。通过使用一个token共享的前馈神经网络来学习每个token的embedding偏移,从而克服DePT的局限性,提升模型的泛化能力和优化效果。
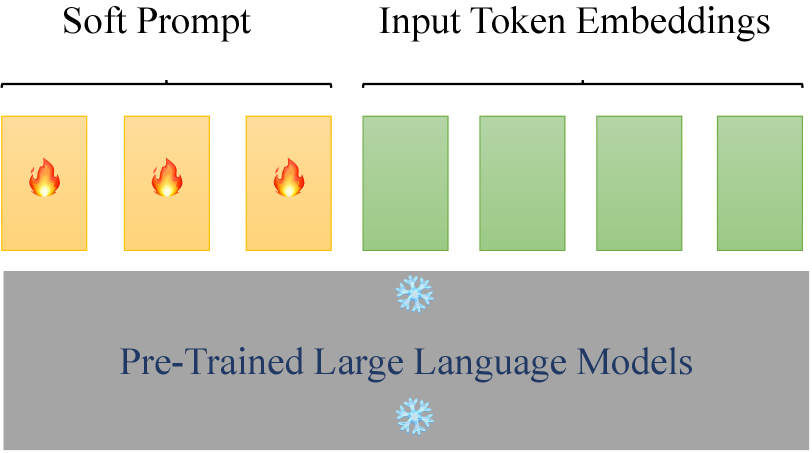
技术框架:ADePT的整体框架包括一个短软prompt和一个浅层的token共享前馈神经网络。首先,将短软prompt添加到输入token embeddings中。然后,使用token共享前馈神经网络为每个token生成自适应的embedding偏移。最后,将这些偏移添加到相应的token embeddings中,从而得到最终的输入表示。整个过程无需额外的推理时间或可训练参数。
关键创新:ADePT的关键创新在于引入了自适应的token embedding偏移。与DePT中固定的、基于位置的偏移不同,ADePT的偏移是根据输入动态生成的,这使得模型能够更好地适应不同的输入,并提升模型的表达能力。此外,token共享前馈神经网络的设计也保证了模型参数的效率。
关键设计:ADePT的关键设计包括:1) 使用短软prompt以减少推理时间;2) 使用浅层token共享前馈神经网络来学习自适应的embedding偏移,该网络可以是简单的MLP;3) 损失函数与下游任务保持一致,无需额外的正则化项。参数设置方面,需要选择合适的网络层数和隐藏层维度,以平衡模型复杂度和性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ADePT在23个NLP任务和4个PLM上均优于其他参数高效微调方法,并在某些情况下超过了全微调。例如,在特定数据集上,ADePT相比于baseline方法取得了显著的性能提升,证明了其自适应embedding偏移的有效性。此外,ADePT在保持推理速度的同时,实现了更高的参数效率。
🎯 应用场景
ADePT可应用于各种自然语言处理任务,尤其是在资源受限的场景下,例如移动设备或边缘计算。它能够以较少的参数实现与全微调相当甚至更优的性能,降低了模型部署和维护的成本。此外,ADePT的自适应性使其在处理不同类型的文本数据时具有更强的鲁棒性,具有广泛的应用前景。
📄 摘要(原文)
Prompt Tuning (PT) enables the adaptation of Pre-trained Large Language Models (PLMs) to downstream tasks by optimizing a small amount of soft virtual tokens, which are prepended to the input token embeddings. Recently, Decomposed Prompt Tuning (DePT) has demonstrated superior adaptation capabilities by decomposing the soft prompt into a shorter soft prompt and a pair of low-rank matrices. The product of the pair of low-rank matrices is added to the input token embeddings to offset them. Additionally, DePT achieves faster inference compared to PT due to the shorter soft prompt. However, in this paper, we find that the position-based token embedding offsets of DePT restrict its ability to generalize across diverse model inputs, and that the shared embedding offsets across many token embeddings result in sub-optimization. To tackle these issues, we introduce Adaptive Decomposed Prompt Tuning (ADePT), which is composed of a short soft prompt and a shallow token-shared feed-forward neural network. ADePT utilizes the token-shared feed-forward neural network to learn the embedding offsets for each token, enabling adaptive embedding offsets that vary according to the model input and better optimization of token embedding offsets. This enables ADePT to achieve superior adaptation performance without requiring more inference time or additional trainable parameters compared to vanilla PT and its variants. In comprehensive experiments across 23 natural language processing tasks and 4 typical PLMs of different scales, ADePT consistently surpasses the other leading parameter-efficient fine-tuning methods, and even outperforms the full fine-tuning in certain scenarios. We also provide a theoretical analysis towards ADePT. Code is available at https://github.com/HungerPWAY/ADePT.