VicSim: Enhancing Victim Simulation with Emotional and Linguistic Fidelity
作者: Yerong Li, Yiren Liu, Yun Huang
分类: cs.CL, cs.HC
发布日期: 2025-01-06
备注: 21 pages, 10 figures
💡 一句话要点
VicSim:通过情感和语言保真度增强受害者模拟,用于情景训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 受害者模拟 情景训练 生成对抗网络 情感建模 语言风格
📋 核心要点
- 现有方法在情景训练中模拟受害者时,难以兼顾信息准确性、情感表达和语言风格。
- VicSim模型通过GAN训练和关键信息提示,提升受害者模拟的真实感,着重情感和语言的细致表达。
- 实验表明,VicSim在模拟受害者的人性化方面优于GPT-4,证明了其有效性。
📝 摘要(中文)
情景训练已广泛应用于许多公共服务部门。大型语言模型(LLMs)的最新进展显示出在模拟不同角色以创建这些训练情景方面的潜力。然而,关于如何开发LLM来模拟用于情景训练的受害者知之甚少。本文介绍了一种名为VicSim(受害者模拟器)的新模型,该模型解决了用户模拟的三个关键维度:信息忠实度、情感动态和语言风格(例如,语法使用)。我们率先将基于情景的受害者建模与基于GAN的训练工作流程和基于关键信息的提示相结合,旨在提高模拟受害者的真实感。我们的对抗训练方法教会判别器将语法和情感线索识别为合成内容的可靠指标。根据人工评估员的评估,VicSim模型在类人度方面优于GPT-4。
🔬 方法详解
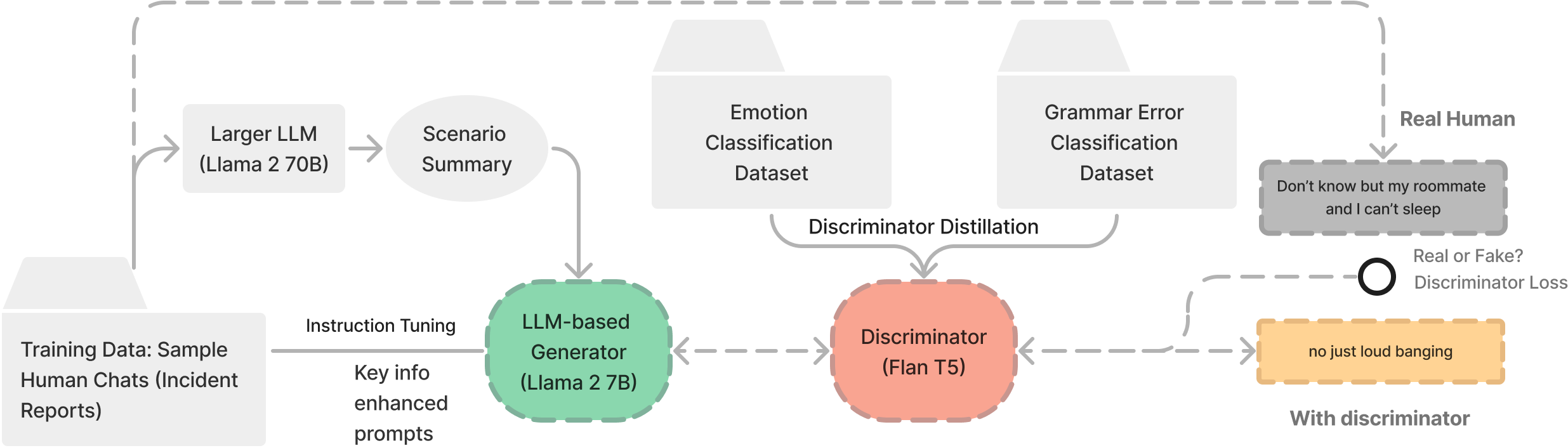
问题定义:论文旨在解决情景训练中受害者模拟真实度不足的问题。现有方法,特别是直接使用大型语言模型,难以同时保证信息准确、情感丰富和语言自然。痛点在于缺乏针对受害者模拟的专门优化,导致生成的内容在情感表达和语法使用上不够逼真。
核心思路:VicSim的核心思路是将情景化的受害者建模与GAN(生成对抗网络)的训练流程相结合。通过对抗训练,判别器学习区分真实和合成的受害者表达,从而迫使生成器生成更逼真的内容。此外,利用关键信息提示,引导模型关注与情景相关的关键细节,确保信息忠实度。
技术框架:VicSim的整体框架包含一个生成器和一个判别器。生成器负责根据给定的情景和关键信息生成受害者的表达,判别器则负责判断生成的内容是真实的还是合成的。通过对抗训练,生成器不断优化其生成能力,判别器不断提高其判别能力。此外,系统还包含一个关键信息提取模块,用于从情景描述中提取关键信息,作为生成器的输入。
关键创新:VicSim的关键创新在于将GAN的对抗训练机制应用于受害者模拟,并结合了关键信息提示。这种方法能够有效地提高生成内容的真实感,特别是在情感表达和语言风格方面。与直接使用大型语言模型相比,VicSim能够更好地控制生成内容的质量,并针对受害者模拟进行专门优化。
关键设计:VicSim的具体设计细节包括:生成器和判别器的网络结构(具体结构未知),损失函数的设计(可能包括对抗损失、情感损失和语言损失),以及关键信息提示的具体形式(例如,使用特定的prompt模板)。此外,对抗训练的超参数设置,如学习率、batch size等,也会影响模型的性能。
🖼️ 关键图片


📊 实验亮点
VicSim在人工评估中,于人性化指标上超越了GPT-4。这表明,通过对抗训练和关键信息提示,VicSim能够生成更逼真、更具情感感染力的受害者模拟内容。具体的性能提升幅度未知,但结果表明VicSim在受害者模拟方面具有显著优势。
🎯 应用场景
VicSim可应用于公共服务部门的情景训练,例如执法部门的危机谈判训练、医疗机构的急救模拟演练等。通过提供更逼真的受害者模拟,VicSim能够帮助训练人员更好地应对真实场景,提高其专业技能和应变能力。未来,该技术还可扩展到其他需要角色扮演的领域,如教育、娱乐等。
📄 摘要(原文)
Scenario-based training has been widely adopted in many public service sectors. Recent advancements in Large Language Models (LLMs) have shown promise in simulating diverse personas to create these training scenarios. However, little is known about how LLMs can be developed to simulate victims for scenario-based training purposes. In this paper, we introduce VicSim (victim simulator), a novel model that addresses three key dimensions of user simulation: informational faithfulness, emotional dynamics, and language style (e.g., grammar usage). We pioneer the integration of scenario-based victim modeling with GAN-based training workflow and key-information-based prompting, aiming to enhance the realism of simulated victims. Our adversarial training approach teaches the discriminator to recognize grammar and emotional cues as reliable indicators of synthetic content. According to evaluations by human raters, the VicSim model outperforms GPT-4 in terms of human-likeness.