LangFair: A Python Package for Assessing Bias and Fairness in Large Language Model Use Cases
作者: Dylan Bouchard, Mohit Singh Chauhan, David Skarbrevik, Viren Bajaj, Zeya Ahmad
分类: cs.CL, cs.AI, cs.CY, cs.LG
发布日期: 2025-01-06
备注: Journal of Open Source Software; LangFair repository: https://github.com/cvs-health/langfair
期刊: Journal of Open Source Software, 10(105), 7570 (2025)
DOI: 10.21105/joss.07570
💡 一句话要点
LangFair:用于评估大型语言模型偏见和公平性的Python软件包
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见评估 公平性 开源工具包 Python 自然语言处理 机器学习
📋 核心要点
- 大型语言模型在各种应用中展现出强大的能力,但同时也暴露出潜在的偏见问题,可能对特定群体造成不公平影响。
- LangFair 旨在通过提供一套全面的工具,帮助开发者评估和减轻其 LLM 应用中的偏见风险,确保公平性。
- LangFair 提供了数据集生成、指标计算和决策框架等功能,方便从业者针对特定用例进行偏见评估和改进。
📝 摘要(中文)
大型语言模型(LLMs)在许多方面都表现出偏见,可能对受性别、种族、性取向或年龄等受保护属性识别的特定群体造成或加剧不良后果。为了弥补这一差距,我们推出了LangFair,这是一个开源Python软件包,旨在为LLM从业者提供评估与其特定用例相关的偏见和公平性风险的工具。该软件包提供易于生成评估数据集的功能,数据集包含LLM对特定用例提示的响应,并随后计算适用于从业者用例的指标。为了指导指标选择,LangFair提供了一个可操作的决策框架。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时可能存在偏见,导致对某些群体的不公平待遇。现有的方法缺乏针对特定用例的、易于使用的偏见评估工具,使得开发者难以发现和解决这些问题。
核心思路:LangFair 的核心思路是提供一个开源的 Python 软件包,允许 LLM 从业者针对其特定用例,方便地生成评估数据集,并计算相关的公平性指标。通过提供一个可操作的决策框架,LangFair 帮助用户选择合适的指标来评估偏见。
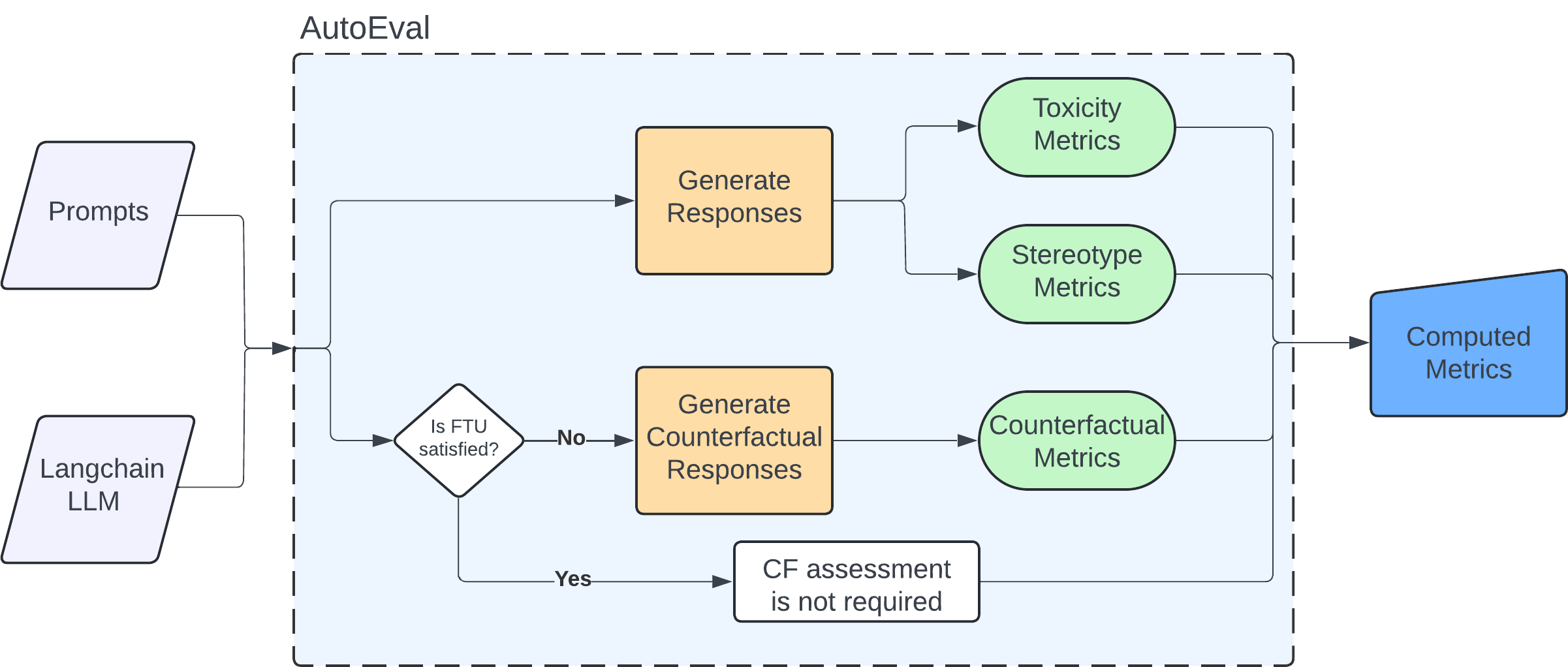
技术框架:LangFair 的整体框架包含以下几个主要阶段:1) 数据集生成:根据用户提供的用例和提示,自动生成用于评估 LLM 响应的数据集。2) LLM 响应:将生成的数据集输入到 LLM 中,获取 LLM 的响应。3) 指标计算:根据用户选择的公平性指标,计算 LLM 响应的偏见程度。4) 决策框架:提供一个决策框架,帮助用户选择合适的公平性指标。
关键创新:LangFair 的关键创新在于其易用性和针对特定用例的评估能力。它提供了一个完整的工具链,从数据集生成到指标计算,使得 LLM 从业者可以方便地评估其应用的偏见风险。此外,LangFair 的决策框架可以帮助用户选择最合适的公平性指标。
关键设计:LangFair 的关键设计包括:1) 灵活的数据集生成:允许用户自定义提示和用例,以生成针对特定场景的评估数据集。2) 可扩展的指标库:支持多种公平性指标,并允许用户添加自定义指标。3) 可操作的决策框架:提供清晰的指导,帮助用户选择合适的指标来评估偏见。
🖼️ 关键图片
📊 实验亮点
LangFair 作为一个开源工具包,其主要亮点在于提供了一个易于使用的平台,用于评估 LLM 在特定用例中的偏见。它通过自动生成评估数据集和计算相关指标,简化了偏见评估流程。此外,LangFair 还提供了一个决策框架,帮助用户选择合适的指标,从而更有效地识别和解决 LLM 中的偏见问题。
🎯 应用场景
LangFair 可应用于各种使用大型语言模型的场景,例如招聘、信贷评估、内容生成等。通过评估和减轻 LLM 中的偏见,LangFair 可以帮助开发者构建更公平、更可靠的 AI 系统,避免对特定群体造成歧视,提升用户体验和信任度。该工具包的开源特性也促进了社区合作,共同推动 LLM 的公平性和可信赖性。
📄 摘要(原文)
Large Language Models (LLMs) have been observed to exhibit bias in numerous ways, potentially creating or worsening outcomes for specific groups identified by protected attributes such as sex, race, sexual orientation, or age. To help address this gap, we introduce LangFair, an open-source Python package that aims to equip LLM practitioners with the tools to evaluate bias and fairness risks relevant to their specific use cases. The package offers functionality to easily generate evaluation datasets, comprised of LLM responses to use-case-specific prompts, and subsequently calculate applicable metrics for the practitioner's use case. To guide in metric selection, LangFair offers an actionable decision framework.