ComMer: a Framework for Compressing and Merging User Data for Personalization
作者: Yoel Zeldes, Amir Zait, Ilia Labzovsky, Danny Karmon, Efrat Farkash
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-01-05
备注: 13 pages, 7 figures
💡 一句话要点
ComMer:一种压缩和合并用户数据的个性化框架,解决LLM个性化应用的资源瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化 数据压缩 多文档合并 技能学习
📋 核心要点
- 现有LLM个性化方法面临上下文长度限制和高昂的计算成本,阻碍了其在资源受限场景下的应用。
- ComMer框架通过压缩用户数据为紧凑表示,再合并输入冻结的LLM,实现高效的个性化。
- 实验表明,ComMer在技能学习任务中表现出色,但在知识密集型任务中存在信息损失的局限性。
📝 摘要(中文)
大型语言模型(LLM)擅长各种任务,但将其应用于新数据,特别是对于个性化应用,由于资源和计算限制,面临着重大挑战。现有方法要么通过提示将新数据暴露给模型,这受到上下文大小的限制,并且在推理时计算成本高昂,要么进行微调,这会产生大量的训练和更新成本。本文介绍了一种新颖的框架ComMer - 压缩和合并 - 通过将用户文档压缩成紧凑的表示,然后将其合并并输入到冻结的LLM中,从而有效地个性化LLM。我们在两种类型的个性化任务上评估ComMer - 个性化技能学习(使用tweet paraphrasing数据集和LaMP基准测试中的个性化新闻标题生成数据集)和知识密集型任务(使用PerLTQA数据集)。我们的实验表明,在受限的推理预算场景中,ComMer在技能学习任务中实现了卓越的质量,同时突出了由于详细信息丢失而在知识密集型设置中的局限性。这些结果为个性化多文档压缩中的权衡和潜在优化提供了见解。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在个性化应用中面临挑战。直接将用户数据通过prompt输入LLM受限于上下文窗口大小,且推理成本高昂。对LLM进行微调虽然有效,但需要大量的计算资源和时间,更新成本也很高。因此,如何在资源有限的情况下,高效地利用用户数据进行LLM的个性化是一个关键问题。
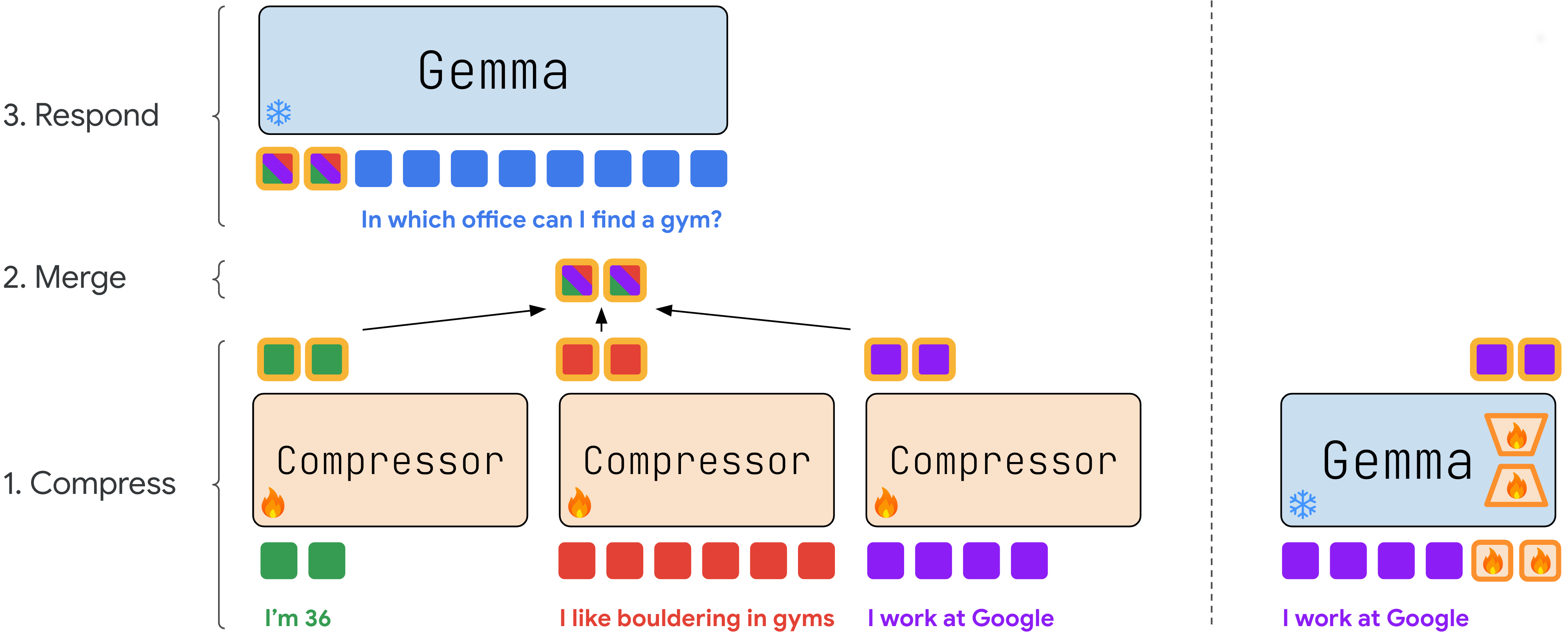
核心思路:ComMer的核心思路是将用户的文档压缩成紧凑的表示形式,然后将这些压缩后的表示合并,并输入到一个冻结的LLM中。通过压缩用户数据,可以减少输入LLM的信息量,从而降低计算成本和上下文长度的限制。合并压缩后的表示,使得LLM能够同时利用多个用户的个性化信息。
技术框架:ComMer框架主要包含两个阶段:压缩阶段和合并阶段。在压缩阶段,使用一个压缩模型将用户的文档压缩成紧凑的向量表示。在合并阶段,将多个用户的压缩向量进行合并,例如通过求平均或加权平均等方式。然后,将合并后的向量输入到一个冻结的LLM中,LLM基于这些信息生成个性化的输出。
关键创新:ComMer的关键创新在于将压缩和合并的思想应用于LLM的个性化。通过压缩用户数据,降低了计算成本和上下文长度的限制。通过合并多个用户的压缩表示,使得LLM能够同时利用多个用户的个性化信息。这种方法避免了对整个LLM进行微调,从而降低了训练和更新的成本。
关键设计:压缩模型的选择是一个关键设计。可以使用各种压缩技术,例如自编码器、向量量化等。合并策略的选择也很重要,不同的合并策略可能会影响LLM的性能。此外,损失函数的设计也需要考虑,例如可以使用对比学习损失来鼓励压缩后的表示保留用户个性化的信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在受限的推理预算场景中,ComMer在技能学习任务(如tweet paraphrasing和个性化新闻标题生成)中表现优于其他方法。虽然在知识密集型任务中存在局限性,但ComMer为个性化多文档压缩提供了有价值的见解,并为未来的优化方向提供了指导。
🎯 应用场景
ComMer框架可应用于各种需要个性化的场景,例如个性化推荐系统、个性化内容生成、个性化对话系统等。该框架能够在资源受限的环境下,高效地利用用户数据进行LLM的个性化,从而提升用户体验。未来,ComMer可以扩展到处理更复杂的数据类型,例如图像、音频等,并应用于更广泛的领域。
📄 摘要(原文)
Large Language Models (LLMs) excel at a wide range of tasks, but adapting them to new data, particularly for personalized applications, poses significant challenges due to resource and computational constraints. Existing methods either rely on exposing fresh data to the model through the prompt, which is limited by context size and computationally expensive at inference time, or fine-tuning, which incurs substantial training and update costs. In this paper, we introduce ComMer - Compress and Merge - a novel framework that efficiently personalizes LLMs by compressing users' documents into compact representations, which are then merged and fed into a frozen LLM. We evaluate ComMer on two types of personalization tasks - personalized skill learning, using the tweet paraphrasing dataset and the personalized news headline generation dataset from the LaMP benchmark, and knowledge-intensive, using the PerLTQA dataset. Our experiments demonstrate that in constrained inference budget scenarios ComMer achieves superior quality in skill learning tasks, while highlighting limitations in knowledge-intensive settings due to the loss of detailed information. These results offer insights into trade-offs and potential optimizations in multi-document compression for personalization.