Multi-LLM Collaborative Caption Generation in Scientific Documents
作者: Jaeyoung Kim, Jongho Lee, Hong-Jun Choi, Ting-Yao Hsu, Chieh-Yang Huang, Sungchul Kim, Ryan Rossi, Tong Yu, Clyde Lee Giles, Ting-Hao 'Kenneth' Huang, Sungchul Choi
分类: cs.CL, cs.CV
发布日期: 2025-01-05
备注: Accepted to AAAI 2025 AI4Research Workshop
🔗 代码/项目: GITHUB
💡 一句话要点
提出MLBCAP框架,利用多LLM协作生成高质量科学文档图表标题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多LLM协作 图表标题生成 科学文档 多模态学习 数据质量评估
📋 核心要点
- 现有科学图表标题生成方法依赖不完整信息,未能充分理解图表上下文,导致生成质量不高。
- MLBCAP框架利用多个专业LLM协同工作,分别负责数据质量评估、多样化标题生成和最佳标题选择。
- 实验结果表明,MLBCAP生成的信息丰富的标题优于人工编写的标题,显著提升了标题质量。
📝 摘要(中文)
科学图表标题生成是一项复杂的任务,需要生成与上下文相关的视觉内容描述。然而,现有方法通常因信息不完整而效果不佳,仅仅将该任务视为图像到文本或文本摘要问题。这种局限性阻碍了生成能够充分捕捉必要细节的高质量标题。此外,来自arXiv论文的现有数据包含低质量的标题,对训练大型语言模型(LLM)构成重大挑战。本文介绍了一个名为多LLM协作图表标题生成(MLBCAP)的框架,通过利用专门的LLM来处理不同的子任务来应对这些挑战。我们的方法分为三个关键模块:(质量评估)我们利用多模态LLM来评估训练数据的质量,从而过滤掉低质量的标题。(多样化标题生成)然后,我们采用一种在标题生成任务上微调/提示多个LLM的策略,以生成候选标题。(判断)最后,我们提示一个突出的LLM从候选标题中选择质量最高的标题,然后完善任何剩余的不准确之处。人工评估表明,我们的方法生成的信息丰富的标题比人工编写的标题更好,突出了其有效性。
🔬 方法详解
问题定义:论文旨在解决科学文档中图表标题生成质量不高的问题。现有方法通常将图表标题生成简单地视为图像到文本或文本摘要任务,忽略了图表与文档上下文之间的复杂关系,并且缺乏高质量的训练数据,导致生成的标题信息不完整、不准确。
核心思路:论文的核心思路是利用多个大型语言模型(LLM)的优势,通过协作的方式完成图表标题生成任务。每个LLM负责不同的子任务,例如数据质量评估、多样化标题生成和最佳标题选择,从而提高整体的标题生成质量。这种分工合作的方式能够充分利用不同LLM的特点,避免单一模型在处理复杂任务时的局限性。
技术框架:MLBCAP框架包含三个主要模块:1) 质量评估:使用多模态LLM评估训练数据的质量,过滤掉低质量的标题,保证训练数据的纯净度。2) 多样化标题生成:使用多个经过微调或提示的LLM生成候选标题,增加标题的多样性。3) 判断:使用一个强大的LLM从候选标题中选择最佳标题,并进行润色,确保标题的准确性和流畅性。
关键创新:该论文的关键创新在于提出了一个多LLM协作的框架,将图表标题生成任务分解为多个子任务,并分配给不同的LLM完成。这种方法能够充分利用不同LLM的优势,提高整体的标题生成质量。此外,该论文还提出了使用多模态LLM进行数据质量评估的方法,有效地过滤掉了低质量的训练数据。
关键设计:在质量评估模块中,使用了多模态LLM来评估标题的质量,考虑了图像和文本信息。在多样化标题生成模块中,使用了多个经过微调或提示的LLM,并采用了不同的prompt策略,以生成多样化的候选标题。在判断模块中,使用了强大的LLM来选择最佳标题,并进行润色,确保标题的准确性和流畅性。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片
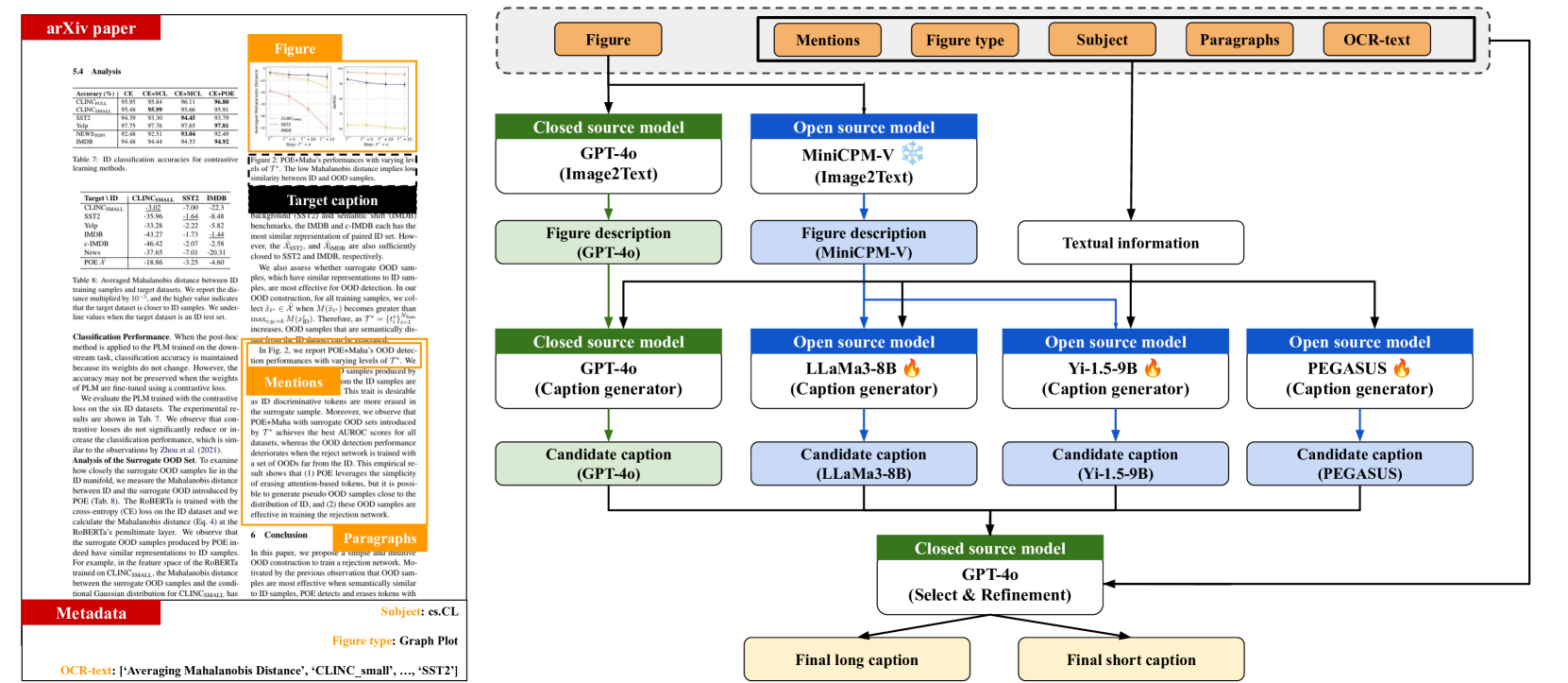
📊 实验亮点
人工评估结果表明,MLBCAP框架生成的信息丰富的标题比人工编写的标题更好,证明了该方法的有效性。具体的性能数据和提升幅度在摘要中没有给出,属于未知信息。代码已开源,方便研究人员复现和改进。
🎯 应用场景
该研究成果可广泛应用于科学文档处理、学术论文写作辅助、科研数据可视化等领域。高质量的图表标题能够帮助研究人员更好地理解图表内容,提高科研效率。未来,该技术还可以应用于自动生成教材、报告等文档中的图表标题,具有重要的实际应用价值和学术意义。
📄 摘要(原文)
Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP