REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
作者: Jian Hu, Jason Klein Liu, Haotian Xu, Wei Shen
分类: cs.CL, cs.LG
发布日期: 2025-01-04 (更新: 2025-11-10)
备注: refactor
💡 一句话要点
提出REINFORCE++,通过全局优势归一化稳定无Critic策略优化,提升RLHF性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 策略优化 全局优势归一化 大型语言模型 无Critic算法 REINFORCE++
📋 核心要点
- 现有无Critic的RLHF方法依赖局部优势归一化,导致优势估计不准确,易过拟合,且理论上有偏差。
- REINFORCE++通过全局优势归一化,在全局批次上进行归一化,提供更稳定、理论上更合理的无偏估计。
- 实验表明,REINFORCE++及其变体在各自领域表现出卓越的稳定性和性能,优于现有方法甚至PPO。
📝 摘要(中文)
从人类反馈中强化学习(RLHF)在对齐大型语言模型(LLMs)方面起着至关重要的作用。主流算法近端策略优化(PPO)采用Critic网络来估计优势函数,这带来了显著的计算和内存开销。为了解决这个问题,出现了一系列无Critic算法(例如,GRPO,RLOO)。然而,这些方法通常依赖于提示级别的(局部)优势归一化,这导致不准确的优势估计,容易过拟合,并且在理论上是有偏的估计。为了解决这些挑战,我们引入了REINFORCE++,这是一个以全局优势归一化为中心的无Critic框架。通过在整个全局批次上而不是在小的、特定于提示的组上归一化优势,我们的方法提供了一个更稳定和理论上合理的、有效的无偏估计(其偏差随着批次大小的增加而消失)。我们介绍了两个变体:REINFORCE++,一种高效且通用的算法(k≥1),适用于通用领域的RLHF;以及REINFORCE++ /w baseline,一种鲁棒的组采样变体(k>1),适用于复杂的推理任务。我们的实证评估表明,每个变体在其各自的领域都表现出卓越的稳定性和性能,优于现有方法,甚至在复杂的智能体设置中优于PPO。
🔬 方法详解
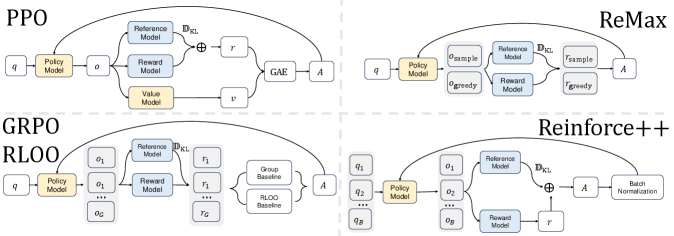
问题定义:论文旨在解决在RLHF中,使用无Critic算法时,由于局部优势归一化导致的优势估计不准确、易过拟合以及理论偏差问题。现有的无Critic方法,如GRPO和RLOO,虽然避免了Critic网络的计算和内存开销,但其局部归一化策略限制了性能。
核心思路:论文的核心思路是使用全局优势归一化来替代局部优势归一化。通过在整个全局批次上计算和归一化优势函数,可以获得更稳定、更准确的优势估计,从而减少偏差和过拟合的风险。这种全局视角能够更好地捕捉不同提示之间的关系,从而提升策略优化效果。
技术框架:REINFORCE++框架主要包括以下几个阶段:1) 从人类反馈数据中采样一批提示和对应的奖励信号。2) 使用策略模型生成响应。3) 计算每个响应的优势函数,这里是关键,采用全局优势归一化。4) 使用REINFORCE算法更新策略模型,目标是最大化期望奖励。框架包含两个变体:REINFORCE++ (k≥1) 适用于通用领域RLHF,REINFORCE++ /w baseline (k>1) 适用于复杂推理任务,后者引入了基线函数以进一步稳定训练。
关键创新:最重要的技术创新点是全局优势归一化。与现有方法的局部归一化相比,全局归一化能够更准确地估计优势函数,减少偏差,并提高训练的稳定性。此外,论文还提出了两种不同的变体,以适应不同类型的RLHF任务。
关键设计:REINFORCE++的关键设计包括:1) 全局优势归一化的具体实现,即计算整个批次上的均值和标准差,并使用这些统计量来归一化每个样本的优势函数。2) 对于REINFORCE++ /w baseline,基线函数的选择和训练方式,论文中可能使用了某种形式的回归模型来预测基线值。3) 策略模型的选择和训练方式,通常使用Transformer架构,并采用梯度上升等优化算法。
🖼️ 关键图片
📊 实验亮点
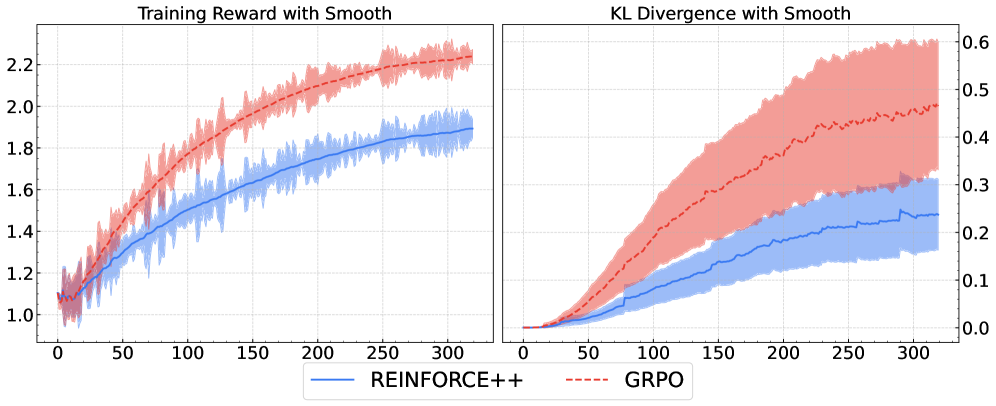
实验结果表明,REINFORCE++及其变体在各自领域均优于现有方法,甚至在复杂的智能体设置中超越了PPO。具体性能提升数据未知,但摘要强调了其在稳定性和性能方面的优势。该方法尤其在复杂推理任务中表现出色,证明了全局优势归一化的有效性。
🎯 应用场景
REINFORCE++可广泛应用于大型语言模型的对齐任务,例如指令遵循、对话生成、内容创作等。通过更稳定和高效的策略优化,可以提升LLM生成内容的质量、安全性和符合人类偏好的程度。该方法在智能客服、AI写作助手、教育辅导等领域具有潜在的应用价值。
📄 摘要(原文)
Reinforcement Learning from Human Feedback~(RLHF) plays a crucial role in aligning Large Language Models~(LLMs). The dominant algorithm, Proximal Policy Optimization~(PPO), employs a critic network to estimate advantages, which introduces significant computational and memory overhead. To address this, a family of critic-free algorithms (e.g., GRPO, RLOO) has emerged. However, these methods typically rely on \textit{prompt-level (local)} advantage normalization, which suffers from inaccurate advantage estimation, a tendency to overfit, and, as we show, is a theoretically biased estimator. To solve these challenges, we introduce REINFORCE++, a critic-free framework centered on \textbf{Global Advantage Normalization}. By normalizing advantages across the entire global batch rather than small, prompt-specific groups, our method provides a more stable and theoretically sound, \textit{effectively unbiased} estimate (whose bias vanishes as batch size increases). We introduce two variants: REINFORCE++, a highly efficient and general algorithm ($k \ge 1$) for general-domain RLHF, and REINFORCE++ /w baseline, a robust group-sampling variant ($k > 1$) for complex reasoning tasks. Our empirical evaluation demonstrates that each variant shows superior stability and performance in its respective domain, outperforming existing methods and even PPO in complex agentic settings.