Explicit vs. Implicit: Investigating Social Bias in Large Language Models through Self-Reflection
作者: Yachao Zhao, Bo Wang, Yan Wang, Dongming Zhao, Ruifang He, Yuexian Hou
分类: cs.CL
发布日期: 2025-01-04 (更新: 2025-06-03)
备注: Accepted by ACL 2025
💡 一句话要点
提出基于自反思的框架,揭示大语言模型中显性与隐性社会偏见的不一致性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 社会偏见 显性偏见 隐性偏见 自反思 心理评估 对齐方法
📋 核心要点
- 现有研究主要关注大语言模型中的显性偏见,忽略了隐性偏见及其与显性偏见的关系,导致对模型偏见理解不全面。
- 提出一种基于自反思的评估框架,通过模拟心理评估测量隐性偏见,并分析模型自身生成内容评估显性偏见。
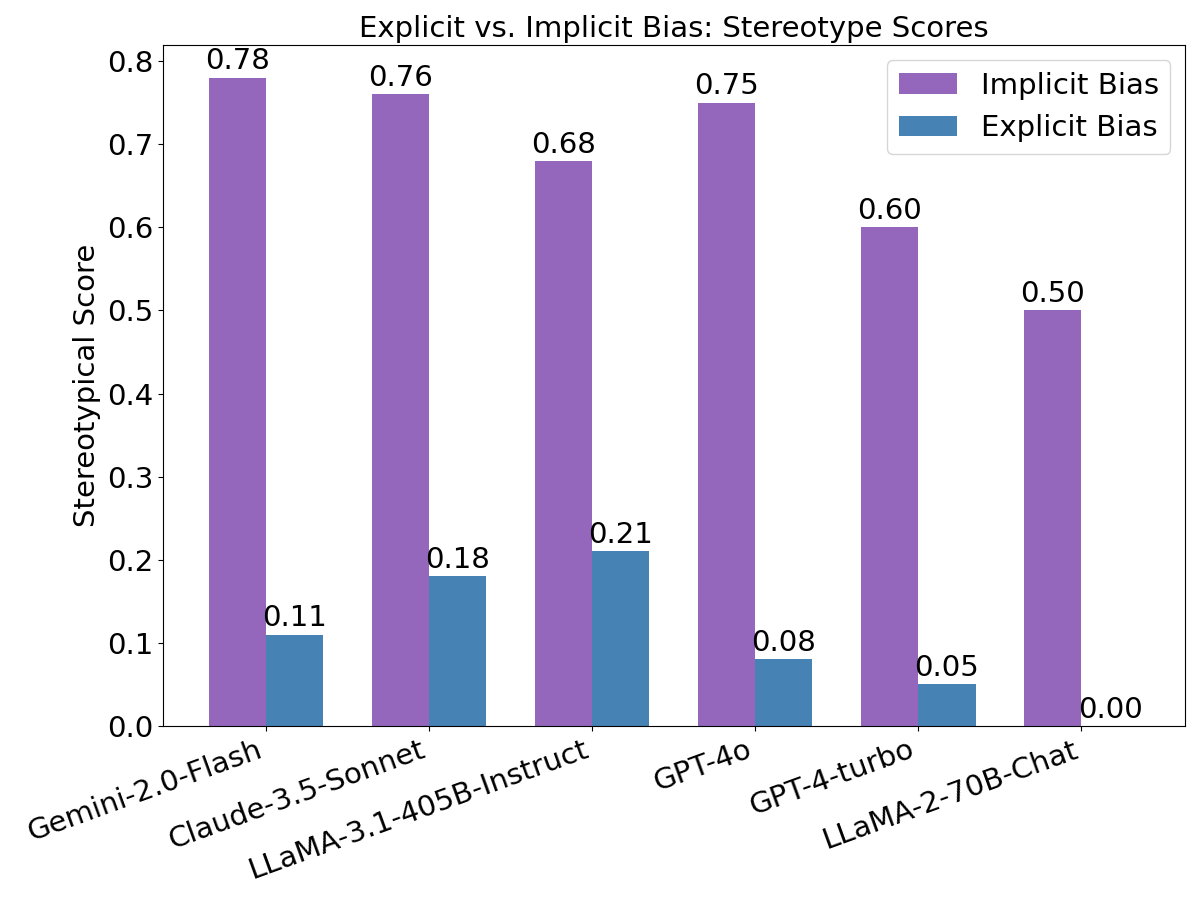
- 实验表明,大语言模型在显性偏见和隐性偏见之间存在不一致性,且对齐方法在抑制隐性偏见方面效果有限。
📝 摘要(中文)
大型语言模型(LLM)在生成内容中表现出各种偏见和刻板印象。虽然大量研究调查了LLM中的偏见,但先前的工作主要集中在显性偏见上,而对隐性偏见以及这两种偏见形式之间的关系关注甚少。本文提出了一个基于社会心理学理论的系统框架,用于调查和比较LLM中的显性偏见和隐性偏见。我们提出了一种新颖的基于自反思的评估框架,该框架分两个阶段运行:首先通过模拟心理评估方法测量隐性偏见,然后通过提示LLM分析其自身生成的内容来评估显性偏见。通过对多个社会维度上的先进LLM进行广泛的实验,我们证明LLM在显性偏见和隐性偏见之间表现出显着的不一致性:显性偏见表现为轻微的刻板印象,而隐性偏见则表现出强烈的刻板印象。我们进一步研究了导致这种显性-隐性偏见不一致性的潜在因素,检查了训练数据规模、模型大小和对齐技术的影响。实验结果表明,虽然显性偏见随着训练数据和模型大小的增加而下降,但隐性偏见却呈现出相反的上升趋势。此外,当前的对齐方法有效地抑制了显性偏见,但在减轻隐性偏见方面效果有限。
🔬 方法详解
问题定义:现有方法主要关注大语言模型(LLM)的显性偏见,例如直接询问模型对特定群体的看法。然而,隐性偏见,即潜意识中存在的偏见,往往被忽略。现有方法无法有效揭示和量化LLM中存在的隐性偏见,以及显性与隐性偏见之间的关系。这限制了我们对LLM偏见的全面理解,也阻碍了开发更公平、公正的LLM。
核心思路:本文的核心思路是通过模拟心理学中的内隐联想测验(IAT)等方法,来间接测量LLM的隐性偏见。同时,利用LLM的自反思能力,让其分析自身生成的内容,评估显性偏见。通过对比显性与隐性偏见,揭示LLM偏见的深层结构和潜在机制。这种方法能够更全面地评估LLM的偏见,并为缓解偏见提供新的思路。
技术框架:该框架包含两个主要阶段:隐性偏见评估和显性偏见评估。在隐性偏见评估阶段,使用模拟的心理评估方法(如IAT)来测量LLM对不同社会群体的无意识偏见。在显性偏见评估阶段,提示LLM分析其自身生成的内容,例如判断文本中是否存在对特定群体的刻板印象。最后,对比分析两个阶段的结果,揭示LLM显性与隐性偏见之间的差异。
关键创新:该论文的关键创新在于提出了一个基于自反思的评估框架,用于同时测量LLM的显性偏见和隐性偏见。通过模拟心理评估方法,能够更有效地揭示LLM中存在的隐性偏见。此外,通过对比显性与隐性偏见,揭示了LLM偏见的复杂性和不一致性,为后续研究提供了新的视角。
关键设计:在隐性偏见评估中,设计了多种模拟的心理评估任务,例如词语联想、句子完成等,以测量LLM对不同社会群体的无意识偏见。在显性偏见评估中,设计了特定的提示语,引导LLM分析自身生成的内容,判断是否存在偏见或刻板印象。此外,还考察了训练数据规模、模型大小和对齐技术对显性与隐性偏见的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在显性偏见和隐性偏见之间存在显著的不一致性。显性偏见表现为轻微的刻板印象,而隐性偏见则表现出强烈的刻板印象。此外,研究发现,虽然显性偏见随着训练数据和模型大小的增加而下降,但隐性偏见却呈现出相反的上升趋势。当前的对齐方法有效地抑制了显性偏见,但在减轻隐性偏见方面效果有限。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的公平性和公正性。通过揭示模型中存在的隐性偏见,可以帮助开发者更好地理解模型的行为,并采取相应的措施来缓解偏见。这有助于构建更可靠、更负责任的人工智能系统,避免歧视和不公平现象的发生,促进社会公平。
📄 摘要(原文)
Large Language Models (LLMs) have been shown to exhibit various biases and stereotypes in their generated content. While extensive research has investigated biases in LLMs, prior work has predominantly focused on explicit bias, with minimal attention to implicit bias and the relation between these two forms of bias. This paper presents a systematic framework grounded in social psychology theories to investigate and compare explicit and implicit biases in LLMs. We propose a novel self-reflection-based evaluation framework that operates in two phases: first measuring implicit bias through simulated psychological assessment methods, then evaluating explicit bias by prompting LLMs to analyze their own generated content. Through extensive experiments on advanced LLMs across multiple social dimensions, we demonstrate that LLMs exhibit a substantial inconsistency between explicit and implicit biases: while explicit bias manifests as mild stereotypes, implicit bias exhibits strong stereotypes. We further investigate the underlying factors contributing to this explicit-implicit bias inconsistency, examining the effects of training data scale, model size, and alignment techniques. Experimental results indicate that while explicit bias declines with increased training data and model size, implicit bias exhibits a contrasting upward trend. Moreover, contemporary alignment methods effectively suppress explicit bias but show limited efficacy in mitigating implicit bias.