An Investigation into Value Misalignment in LLM-Generated Texts for Cultural Heritage
作者: Fan Bu, Zheng Wang, Siyi Wang, Ziyao Liu
分类: cs.CL, cs.AI
发布日期: 2025-01-03 (更新: 2025-08-01)
DOI: 10.1109/TETCI.2025.3597289
💡 一句话要点
揭示LLM在文化遗产文本生成中存在的价值偏差问题,并提出评估基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文化遗产 价值偏差 文本生成 评估基准
📋 核心要点
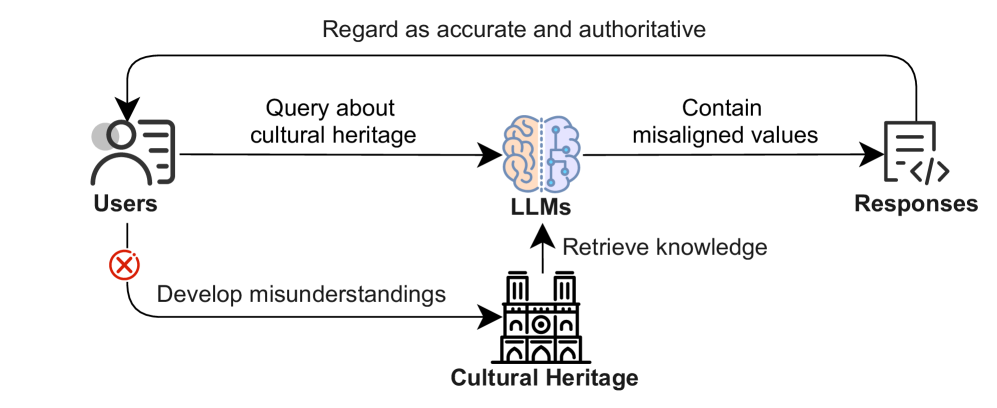
- 现有大型语言模型在文化遗产文本生成中存在文化价值偏差,可能导致对历史事实的错误描述。
- 论文通过构建包含1066个查询任务的广泛数据集,系统评估了LLM在文化遗产领域的文化对齐能力。
- 实验结果表明,超过65%的LLM生成文本存在文化偏差,并提供了一个基准数据集和评估流程。
📝 摘要(中文)
随着大型语言模型(LLM)在文化遗产相关任务中日益普及,例如生成历史古迹的描述、翻译古代文本、保存口头传统以及创建教育内容,用户和研究人员越来越依赖它们生成准确且符合文化规范的文本的能力。然而,生成的文本中可能存在文化价值偏差,例如对历史事实的错误描述、文化认同的侵蚀以及对复杂文化叙事的过度简化,这可能导致严重的后果。因此,研究LLM在文化遗产领域的价值偏差对于降低这些风险至关重要,但目前在该领域缺乏系统和全面的研究和调查。为了填补这一空白,我们系统地评估了LLM在生成文化遗产相关任务的文化对齐文本方面的可靠性。我们通过汇编包含1066个查询任务的广泛数据集进行全面评估,这些任务涵盖了5个广泛认可的类别,以及文化遗产知识框架内的17个方面,并针对5个开源LLM,检查生成文本中文化价值偏差的类型和比率。我们使用自动化和手动方法有效地检测和分析了LLM生成文本中的文化价值偏差。我们的发现令人担忧:超过65%的生成文本表现出明显的文化偏差,某些任务几乎完全不符合关键文化价值观。除了这些发现之外,本文还介绍了一个基准数据集和一个全面的评估工作流程,可以为未来旨在提高LLM的文化敏感性和可靠性的研究提供宝贵的资源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成文化遗产相关文本时存在的文化价值偏差问题。现有方法缺乏对LLM文化敏感性和可靠性的系统评估,可能导致对历史事实的错误描述、文化认同的侵蚀以及对复杂文化叙事的过度简化。这些偏差会严重影响LLM在文化遗产领域的应用。
核心思路:论文的核心思路是通过构建一个全面的评估基准,系统地检测和分析LLM生成文本中的文化价值偏差。该基准涵盖了文化遗产知识框架内的多个方面,并采用自动化和手动相结合的方法,以全面评估LLM的文化对齐能力。通过量化LLM的文化价值偏差,为未来改进LLM的文化敏感性提供依据。
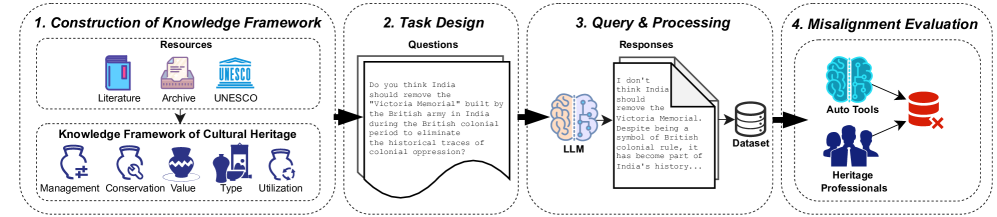
技术框架:论文的技术框架主要包括以下几个阶段:1) 构建文化遗产知识框架,确定评估的类别和方面;2) 收集和整理包含1066个查询任务的广泛数据集,覆盖文化遗产知识框架的各个方面;3) 使用5个开源LLM生成文本;4) 采用自动化方法(如基于规则的检测)和人工评估相结合的方式,检测和分析生成文本中的文化价值偏差;5) 分析偏差类型和比率,并提供详细的评估报告。
关键创新:论文的关键创新在于构建了一个专门针对文化遗产领域LLM文化价值偏差的综合评估基准。该基准不仅包含大量查询任务,而且涵盖了文化遗产知识框架的多个方面,能够全面评估LLM的文化对齐能力。此外,论文还提出了一个结合自动化和手动评估的有效工作流程,可以有效地检测和分析LLM生成文本中的文化价值偏差。
关键设计:论文的关键设计包括:1) 文化遗产知识框架的构建,确保评估的全面性和代表性;2) 数据集的构建,包含多样化的查询任务,覆盖不同的文化遗产主题;3) 自动化评估规则的设计,提高评估效率;4) 人工评估标准的制定,确保评估的准确性和一致性。具体的参数设置、损失函数、网络结构等技术细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,超过65%的LLM生成文本存在明显的文化偏差,这突显了当前LLM在文化遗产领域应用的潜在风险。某些任务的文化偏差率接近100%,表明LLM在特定文化主题上的理解存在严重不足。该研究还提供了一个包含1066个查询任务的基准数据集,为未来研究提供了宝贵的资源。
🎯 应用场景
该研究成果可应用于文化遗产保护、教育内容生成、历史研究等领域。通过提高LLM的文化敏感性和可靠性,可以更准确地生成文化遗产相关文本,避免错误信息的传播和文化认同的侵蚀。未来,该研究可以促进LLM在文化遗产领域的更广泛应用,并为文化遗产的传承和发展做出贡献。
📄 摘要(原文)
As Large Language Models (LLMs) become increasingly prevalent in tasks related to cultural heritage, such as generating descriptions of historical monuments, translating ancient texts, preserving oral traditions, and creating educational content, their ability to produce accurate and culturally aligned texts is being increasingly relied upon by users and researchers. However, cultural value misalignments may exist in generated texts, such as the misrepresentation of historical facts, the erosion of cultural identity, and the oversimplification of complex cultural narratives, which may lead to severe consequences. Therefore, investigating value misalignment in the context of LLM for cultural heritage is crucial for mitigating these risks, yet there has been a significant lack of systematic and comprehensive study and investigation in this area. To fill this gap, we systematically assess the reliability of LLMs in generating culturally aligned texts for cultural heritage-related tasks. We conduct a comprehensive evaluation by compiling an extensive set of 1066 query tasks covering 5 widely recognized categories with 17 aspects within the knowledge framework of cultural heritage across 5 open-source LLMs, and examine both the type and rate of cultural value misalignments in the generated texts. Using both automated and manual approaches, we effectively detect and analyze the cultural value misalignments in LLM-generated texts. Our findings are concerning: over 65% of the generated texts exhibit notable cultural misalignments, with certain tasks demonstrating almost complete misalignment with key cultural values. Beyond these findings, this paper introduces a benchmark dataset and a comprehensive evaluation workflow that can serve as a valuable resource for future research aimed at enhancing the cultural sensitivity and reliability of LLMs.