CarbonChat: Large Language Model-Based Corporate Carbon Emission Analysis and Climate Knowledge Q&A System
作者: Zhixuan Cao, Ming Han, Jingtao Wang, Meng Jia
分类: cs.CL, cs.AI
发布日期: 2025-01-03
备注: 26 pages
💡 一句话要点
CarbonChat:基于大语言模型的企业碳排放分析与气候知识问答系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 碳排放分析 大语言模型 检索增强生成 气候知识问答 企业可持续发展
📋 核心要点
- 现有大语言模型在气候变化知识更新方面存在滞后,传统增强生成架构在处理复杂问题时缺乏专业性和准确性。
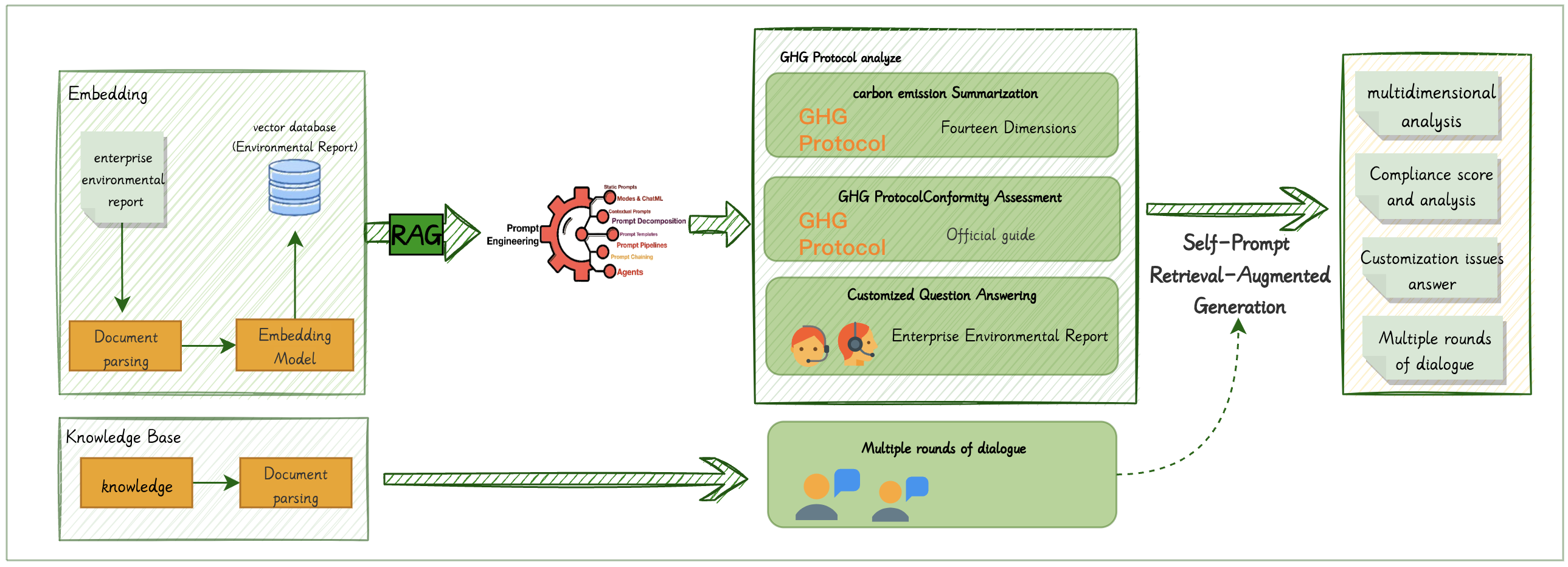
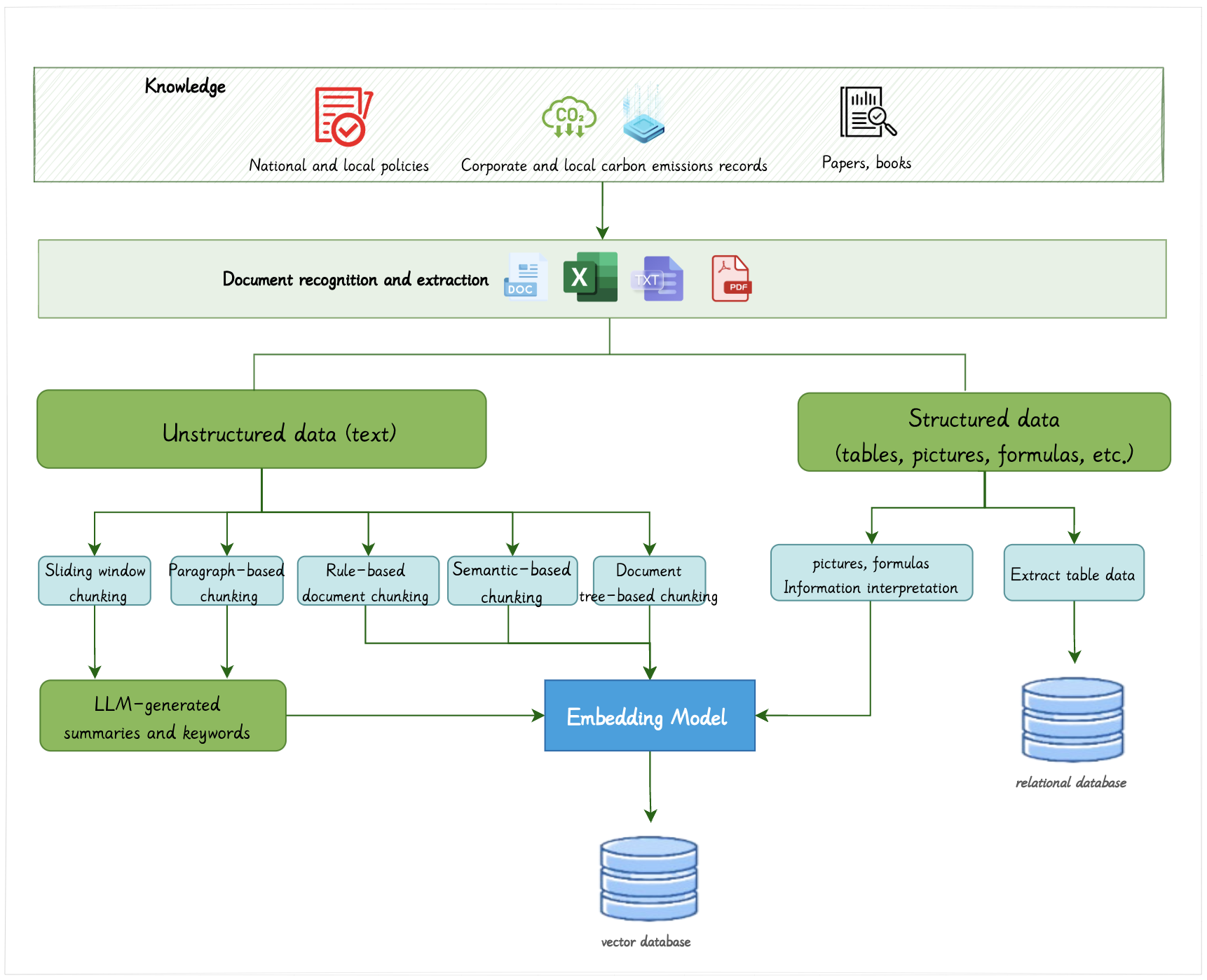
- CarbonChat通过多样化指标模块构建、增强的自提示检索增强生成架构以及多层分块机制等方法,提升碳排放分析的准确性和效率。
- 该系统基于温室气体核算框架,建立了14个维度的碳排放分析,并集成了幻觉检测功能,确保分析结果的可信度。
📝 摘要(中文)
本文提出了CarbonChat,一个基于大语言模型的企业碳排放分析与气候知识问答系统,旨在实现精确的碳排放分析和政策理解,以应对全球气候变化影响加剧、大语言模型气候变化知识更新滞后、传统增强生成架构在复杂问题上缺乏专业性和准确性、以及可持续性报告分析成本高昂且耗时等问题。该系统首先提出了一种多样化的指标模块构建方法,处理规则型和长文本文件的分割以及结构化数据的提取,从而优化关键信息的解析。其次,设计了一种增强的自提示检索增强生成架构,集成了意图识别、结构化推理链、混合检索和Text2SQL,提高了语义理解和查询转换的效率。接下来,基于温室气体核算框架,建立了14个维度的碳排放分析,实现了报告总结、相关性评估和定制化响应。最后,通过多层分块机制、时间戳和幻觉检测功能,确保了分析结果的准确性和可验证性,降低了幻觉率,提高了响应的精度。
🔬 方法详解
问题定义:论文旨在解决企业碳排放分析领域中,现有方法存在的知识更新滞后、专业性不足、分析成本高昂以及结果可信度低等问题。具体来说,现有方法难以有效处理可持续性报告中的复杂信息,并且容易产生幻觉,导致分析结果不准确。
核心思路:论文的核心思路是利用大语言模型强大的语义理解和生成能力,结合领域知识和检索增强技术,构建一个能够精确分析企业碳排放并提供可靠气候知识问答的系统。通过优化信息解析、提高语义理解和查询转换效率、以及降低幻觉率,提升碳排放分析的准确性和可信度。
技术框架:CarbonChat系统的整体架构包含以下几个主要模块:1) 多样化指标模块构建,用于处理规则型和长文本文件,提取结构化数据;2) 增强的自提示检索增强生成架构,集成了意图识别、结构化推理链、混合检索和Text2SQL;3) 基于温室气体核算框架的碳排放分析模块,包含14个维度;4) 多层分块机制、时间戳和幻觉检测模块,用于提高分析结果的准确性和可验证性。
关键创新:该论文的关键创新在于:1) 提出了一种多样化的指标模块构建方法,能够有效处理不同类型的碳排放相关文档;2) 设计了一种增强的自提示检索增强生成架构,通过集成多种技术,提高了语义理解和查询转换的效率;3) 引入了多层分块机制、时间戳和幻觉检测功能,有效降低了幻觉率,提高了分析结果的准确性和可验证性。
关键设计:在增强的自提示检索增强生成架构中,意图识别模块用于识别用户查询的意图,结构化推理链用于生成推理步骤,混合检索模块用于检索相关信息,Text2SQL模块用于将自然语言查询转换为SQL查询。多层分块机制将长文本分割成多个小块,以便大语言模型更好地处理。幻觉检测模块用于检测生成结果中是否存在不真实的信息。
🖼️ 关键图片

📊 实验亮点
论文重点在于方法论的提出,具体实验数据未知。但通过多层分块机制、时间戳和幻觉检测功能,可以有效降低幻觉率,提高响应的精度,从而保证分析结果的准确性和可验证性。增强的自提示检索增强生成架构,集成了意图识别、结构化推理链、混合检索和Text2SQL,提高了语义理解和查询转换的效率。
🎯 应用场景
CarbonChat可应用于企业碳排放管理、政策制定支持、投资者决策参考等领域。该系统能够帮助企业更高效地分析自身碳排放情况,为政府部门提供更准确的政策制定依据,并为投资者提供更全面的企业可持续发展信息,从而促进全球气候变化应对。
📄 摘要(原文)
As the impact of global climate change intensifies, corporate carbon emissions have become a focal point of global attention. In response to issues such as the lag in climate change knowledge updates within large language models, the lack of specialization and accuracy in traditional augmented generation architectures for complex problems, and the high cost and time consumption of sustainability report analysis, this paper proposes CarbonChat: Large Language Model-based corporate carbon emission analysis and climate knowledge Q&A system, aimed at achieving precise carbon emission analysis and policy understanding.First, a diversified index module construction method is proposed to handle the segmentation of rule-based and long-text documents, as well as the extraction of structured data, thereby optimizing the parsing of key information.Second, an enhanced self-prompt retrieval-augmented generation architecture is designed, integrating intent recognition, structured reasoning chains, hybrid retrieval, and Text2SQL, improving the efficiency of semantic understanding and query conversion.Next, based on the greenhouse gas accounting framework, 14 dimensions are established for carbon emission analysis, enabling report summarization, relevance evaluation, and customized responses.Finally, through a multi-layer chunking mechanism, timestamps, and hallucination detection features, the accuracy and verifiability of the analysis results are ensured, reducing hallucination rates and enhancing the precision of the responses.